Solr是apache的顶级开源项目,它是使用java开发 ,基于lucene的全文检索服务器。Solr比lucene提供了更多的查询语句,而且它可扩展、可配置,同时它对lucene的性能进行了优化。Solr和lucene有什么区别呢?
Lucene是一个全文检索引擎工具包,它只是一个jar包,不能独立运行与对外提供服务。
Solr是一个全文检索服务器,它可以单独运行在servlet容器上,可以单独对外提供搜索和索引功能。Solr比lucene在开发全文检索功能方面更快捷、更方便。
那么,Solr是如何实现全文检索的呢?
索引流程:solr客户端(浏览器、java程序)可以向solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档,通过该文档,solr实现对索引的维护(增删改)。
搜索流程:solr客户端(浏览器、java程序)可以向solr服务端发送GET请求,solr服务器返回一个xml文档。
在使用solr时,先要下载与安装solr(本文使用4.10.3版本),下载地址:http://archive.apache.org/dist/lucene/solr/。其中,Solr和lucene的版本是同步更新的。
Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
solr运行环境是:
Jdk:1.7及以上 Solr:4.10.3 Mysql:5X Web服务器:tomcat 7
将solr-4.10.3/dist下的solr-4.10.3.war包(为使用方便,将其更名为solr.war)拷贝到tomcat的webapps下,启动tomcat时,该war包会自动解压缩为名称为solr的文件夹,此时,将solr.war包删除。接下来,添加solr的扩展服务包,截图如下(jar包数量较多,部分显示):
接下来,将log4j.properties等配置文件拷贝到如下路径:
接下来,在web.xml中指定solrhome的目录:
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>E: omcatapache-tomcat-7.0.53-8090solrhome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>
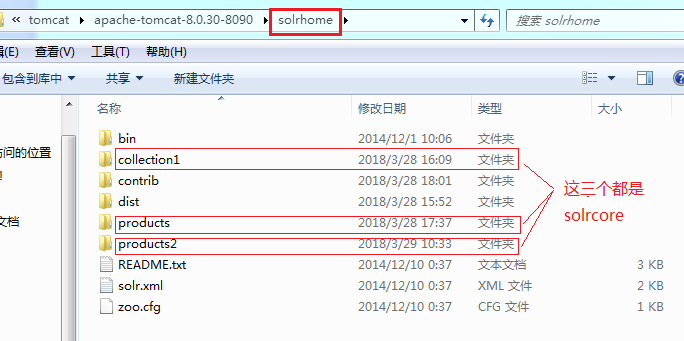
其中,Solrhome是solr服务运行的主目录,一个solrhome目录里面包含多个solrcore目录,一个solrcore目录里面包含了一个solr实例运行时所需要的配置文件和数据文件。每一个solrcore都可以单独对外提供搜索和索引服务。多个solrcore之间没有关系。solrhome的文件结构:
solrcore的文件结构如下:
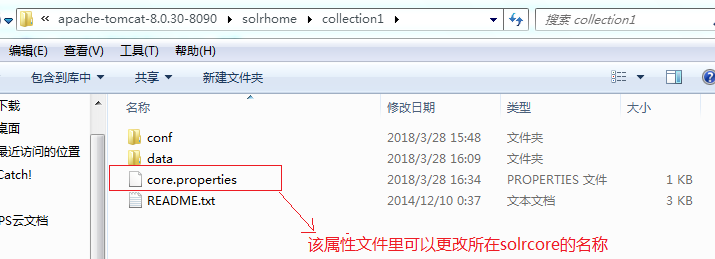
在solrcore的conf文件下,找到solrconfig.xml文件,通过里面的lib标签来指定依赖包的地址:
<lib dir="${solr.install.dir:..}/contrib/extraction/lib" regex=".*.jar" />
<lib dir="${solr.install.dir:..}/dist/" regex="solr-cell-d.*.jar" />
<lib dir="${solr.install.dir:..}/contrib/clustering/lib/" regex=".*.jar" />
<lib dir="${solr.install.dir:..}/dist/" regex="solr-clustering-d.*.jar" />
<lib dir="${solr.install.dir:..}/contrib/langid/lib/" regex=".*.jar" />
<lib dir="${solr.install.dir:..}/dist/" regex="solr-langid-d.*.jar" />
<lib dir="${solr.install.dir:..}/contrib/velocity/lib" regex=".*.jar" />
<lib dir="${solr.install.dir:..}/dist/" regex="solr-velocity-d.*.jar" />
<lib dir="${solr.install.dir:..}/contrib/dataimporthandler/lib" regex=".*.jar" />
<lib dir="${solr.install.dir:..}/contrib/db/lib" regex=".*.jar" />
里面的“solr.install.dir”表示solrcore的安装目录。
再在solrcore的conf文件下找到schema.xml文件,加入如下配置信息:
<!-- Chinese -->
<fieldType name="text_zh" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"> </analyzer>
</fieldType>
<field name="content_zh" type="text_zh" indexed="true" stored="true"></field>
<field name="product_name" type="text_zh" indexed="true" stored="true"></field>
<field name="product_catalog_name" type="text_zh" indexed="true" stored="true"></field>
<field name="product_price" type="float" indexed="true" stored="true"></field>
<field name="product_description" type="text_zh" indexed="true" stored="true"></field>
<field name="product" type="text_zh" indexed="true" stored="true" multiValued="true"></field>
<copyField source="id" dest="product"/>
<copyField source="product_name" dest="product"/>
<copyField source="product_catalog_name" dest="product"/>
<copyField source="product_price" dest="product"/>
<copyField source="product_description" dest="product"/>
其中,product是测试搜索的数据。
每个SolrCore都有自己的索引文件目录 ,默认在SolrCore目录下的data中。data数据目录下包括了index索引目录 和tlog日志文件目录。如果不想使用默认的目录也可以通过solrConfig.xml更改索引目录 ,如下:
<dataDir>${solr.data.dir:E:/develop/solr/solrhome/solrcore/data}</dataDir>
在solrconfig.xml文件中,有个requestHandler标签,它是一个请求处理器,定义了索引和搜索的访问方式。通过/update维护索引,可以完成索引的添加、修改、删除操作;通过/select搜索索引;通过/dataimport可以导入数据库中的数据。如下:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
在配置完solr后,启动tomcat,访问solr,界面如下:
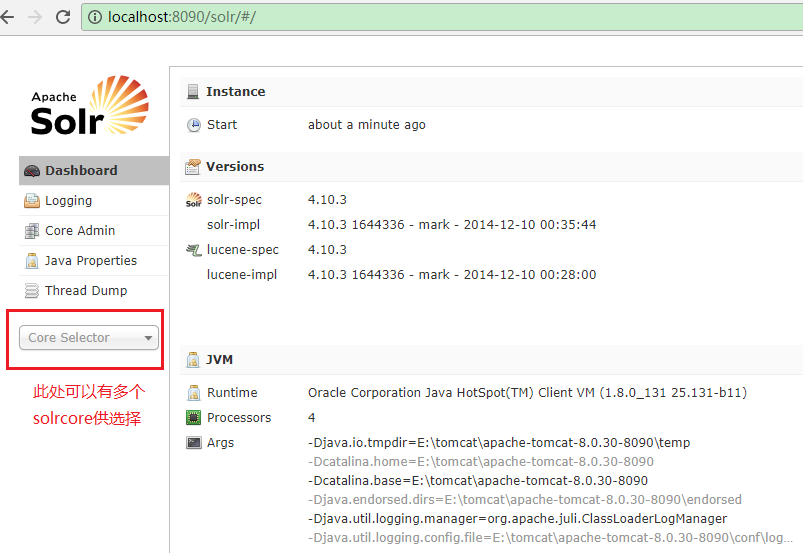
一个solr服务器可以配置多个solrcore,这样做的好处有:
(1)在进行solrcloud的时候,必须配置多solrcore。
(2) 每个solrcore之间是独立的,都可以单独对外提供服务;不同的业务模块可以使用不同的solrcore来提供搜索和索引服务。
在使用solr时,要先在schema.xml文件中配置solrcore的一些数据信息,包括Field和FieldType的定义等信息,在solr中,Field和FieldType都需要先定义后使用。
定义Field域
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
Name:指定域的名称
Type:指定域的类型
Indexed:是否索引
Stored:是否存储
Required:是否必须
multiValued:是否多值,比如商品信息中,一个商品有多张图片,一个Field像存储多个值的话,必须将multiValued设置为true。
----------------------------------------------
动态域
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
Name:指定动态域的命名规则
------------------------------------------------
指定唯一键
<uniqueKey>id</uniqueKey>
其中的id是在Field标签中已经定义好的域名,而且该域要设置为required为true。
一个schema.xml文件中必须有且仅有一个唯一键
-----------------------------------------------
复制域
<copyField source="cat" dest="text"/>
Source:要复制的源域的域名
Dest:目标域的域名
由dest指的的目标域,必须设置multiValued为true。
-------------------------------------------------
定义域的类型
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Name:指定域类型的名称
Class:指定该域类型对应的solr的类型
Analyzer:指定分析器
Type:index、query,分别指定搜索和索引时的分析器
Tokenizer:指定分词器
Filter:指定过滤器
-------------------------------------------------
使用ikanalyzer进行中文分词
<!-- Chinese -->
<fieldType name="text_zh" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"> </analyzer>
</fieldType>
<field name="content_zh" type="text_zh" indexed="true" stored="true"></field>
我们在java程序中使用solr时,需要使用solrj,这是solr服务器的java客户端。其操作逻辑如下:
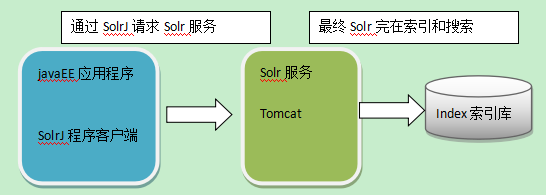
接下来通过代码演示操作solr:
package com.itszt.solr;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;
import java.io.IOException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* 测试solr
*/
public class TestUpdate {
//products中,product_price的type为text_zh
// //products2中,product_price的type为float
//更换另一个solr-core
//测试插入数据
@Test
public void testInsertData() throws IOException, SolrServerException {
HttpSolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr/products2");
SolrInputDocument solrInputDocument = new SolrInputDocument();
solrInputDocument.addField("id","10086");
solrInputDocument.addField("product_name","大红花");
solrInputDocument.addField("product_price","28.89");
solrInputDocument.addField("product_description","这朵大红花就是好好看");
solrServer.add(solrInputDocument);
solrServer.commit();
}
//测试更新数据
@Test
public void testUpdateData() throws IOException, SolrServerException {
HttpSolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr/products2");
SolrInputDocument solrInputDocument = new SolrInputDocument();
solrInputDocument.addField("id","10086");
solrInputDocument.addField("product_name","大红花");
solrInputDocument.addField("product_price","28.79");
solrInputDocument.addField("product_description","这朵大红花在加工后就是好好看");
solrServer.add(solrInputDocument);
solrServer.commit();
}
//测试删除数据
@Test
public void testDelteData() throws IOException, SolrServerException {
HttpSolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr/products2");
//solrServer.deleteById("10086");
solrServer.deleteByQuery("product:10086");
solrServer.commit();
}
//测试查询数据
@Test
public void testQueryDatas() throws SolrServerException {
HttpSolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr/products2");
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery("product_name:花儿");
QueryResponse queryResponse = solrServer.query(solrQuery);
SolrDocumentList results = queryResponse.getResults();
for(SolrDocument result:results){
// System.out.println("result = " + result);
Collection<String> fieldNames = result.getFieldNames();
for(String fieldName:fieldNames){
System.out.println(fieldName+" ---> " + result.get(fieldName));
}
}
}
//测试查询高亮度显示的数据
@Test
public void testQueryDatasHl() throws SolrServerException {
HttpSolrServer solrServer = new HttpSolrServer("http://localhost:8090/solr/products2");
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery("product_name:家居");
solrQuery.setFields("product_name,product_price");
solrQuery.setFilterQueries("product_price:[10 TO 100]");
solrQuery.setSort("product_price",SolrQuery.ORDER.asc);
solrQuery.setHighlight(true);
solrQuery.set("hl.fl","product_name");
QueryResponse queryResponse = solrServer.query(solrQuery);
SolrDocumentList results = queryResponse.getResults();
System.out.println("查询回来的数据量:" + results.size());
for(SolrDocument result:results){
Collection<String> fieldNames = result.getFieldNames();
for(String fieldName:fieldNames){
System.out.println(fieldName+"--->"+result.get(fieldName));
System.out.println("----------------------");
}
}
System.out.println("获取高亮数据:");
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
Set<String> keySet1 = highlighting.keySet();
for(String key1:keySet1){
System.out.println("key1 = " + key1);
Map<String, List<String>> map2 = highlighting.get(key1);
System.out.println("map2 = " + map2);
Set<String> keySet2 = map2.keySet();
for(String key2:keySet2){
System.out.println("key2 = " + key2);
}
}
}
}