1、第一句Python代码
在 当前目录下创建 hello.py 文件,内容如下:
print "hello,world!"
执行 hello.py 文件,即: python hello.py
注:后缀可以不是.py
python内部执行过程如下:
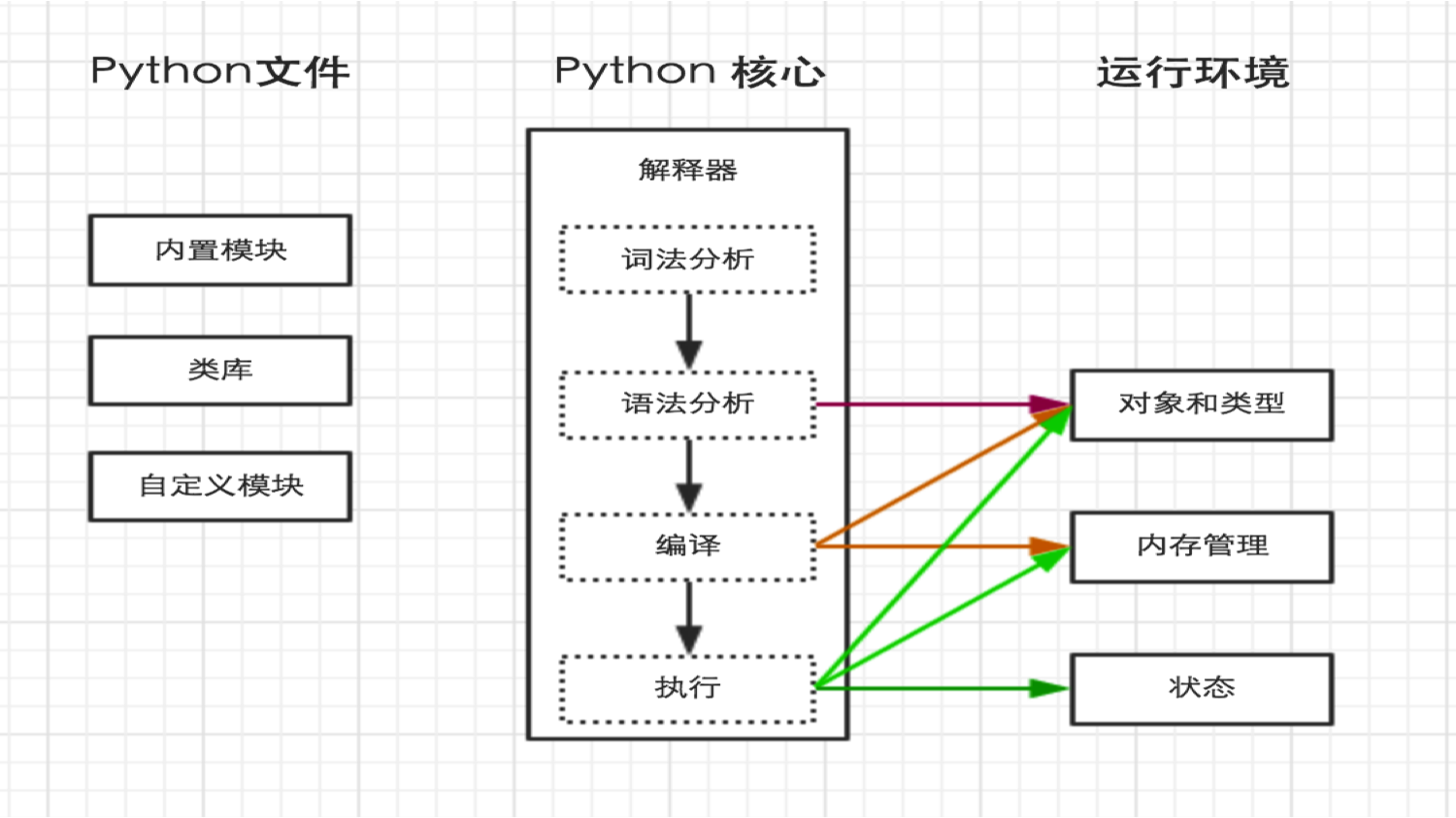
2、解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,则
- 要有执行(x)权限
- hello.py 文件的头部指定解释器,如下:
1 #!/usr/bin/env python 2 3 print "hello,world"
如此一来,执行: ./hello.py 即可。
同C语言相比解释器编译过程:
python语句—>字节码—>机器码
C语言语句—>机器码
ps:给予 hello.py 执行权限,chmod 755 hello.py
pyc文件:执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
当.py文件里的内容发生改变时,当调用此文件当模块时.pyc会重新生成一个新文件
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码
3、内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
1 #!/usr/bin/env python 2 3 print "你好 " 4 5 报错:ascii码无法表示中文( SyntaxError: Non-ASCII character 'xc4' in file hello.txt on line 2)
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 print "你好 5 6
4、注释
单行注视:# 被注释内容
多行注释:""" 被注释内容 """ 或’’’ 被注释内容’’’
5、执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
例子:Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行python脚本时传入的参数
1 #!/usr/bin/env python 2 3 # -*- coding: utf-8 -*- 4 5 import sys 6 7 print sys.argv 8 9 结果: 10 11 F:python>python hello.py localhost:80 12 13 ['hello.py', 'localhost:80']
6、变量
1) 声明变量
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name = "lenliu"
上述代码声明了一个变量,变量名为: name,变量name的值为:"lenliu"
变量的作用:昵称,引用地址,其代指内存里某个地址中保存的内容;用id()方法查询内存地址
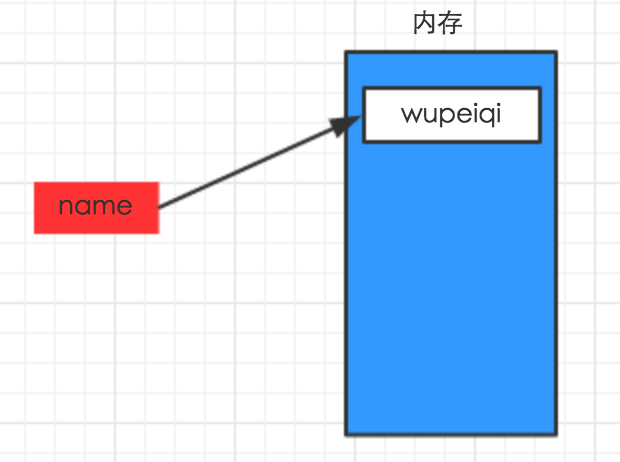
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
2)、变量的赋值
1 #!/usr/bin/env python 2 3 # -*- coding: utf-8 -*- 4 5 name1 = "wupeiqi" 6 7 name2 = "lenliu"
8 name1 = "wupeiqi" 9 10 name2 = name1 11
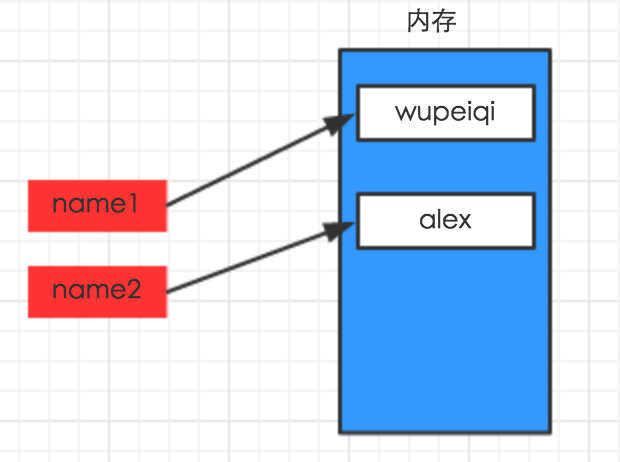
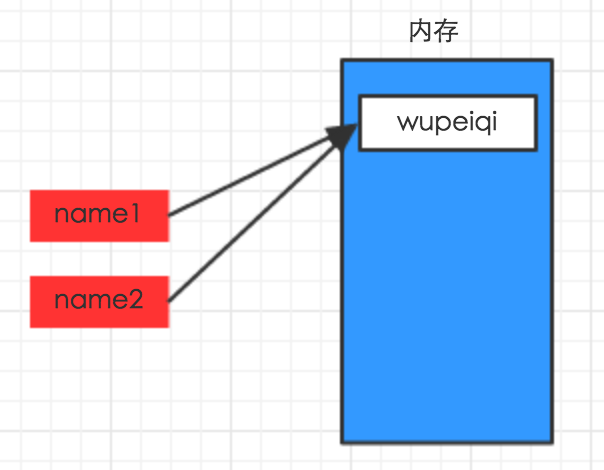
12
7、输入
1) raw_input
name = raw_input("请输入用户名:") # 将用户输入的内容赋值给 name 变量
print name # 打印输入的内容
输入密码时想要不可见,需要利用getpass 模块中的 getpass方法,即:
import getpass
pwd = getpass.getpass("请输入密码:")
print pwd
2) raw_input与input比较:
例子:


1 >>> name = input("what is your name?") 2 3 what is your name?lzl 4 5 Traceback (most recent call last): 6 7 File "<stdin>", line 1, in <module> 8 9 File "<string>", line 1, in <module> 10 11 NameError: name 'lzl' is not defined 12 13 14 15 >>> name = input("what is your name?") 16 17 what is your name?"lzl" #字符串必须加双引号 18 19 20 21 >>> age=raw_input("How old are you?") 22 23 How old are you?18 24 25 >>> type(age) 26 27 <type 'str'> #存为字符串
- input会假设用户输入的是合法的python表达式
- raw_input会把输入当做原始数据(raw data),然后放入字符串中
8 、流程控制和缩进
需求一、用户登陆验证
# 提示输入用户名和密码
# 验证用户名和密码
# 如果错误,则输出用户名或密码错误
# 如果成功,则输出 欢迎,XXX!
1 #!/usr/bin/env python 2 3 # -*- coding: encoding -*- 4 5 6 7 import getpass 8 9 name = raw_input('请输入用户名:') 10 11 pwd = getpass.getpass('请输入密码:') 12 13 14 15 if name == "lenliu" and pwd == "cmd": 16 17 print "欢迎,lenliu!" 18 19 else: 20 21 print "用户名和密码错误"
需求二、根据用户输入内容输出其权限
# 根据用户输入内容打印其权限
# lenliu --> 超级管理员
# amy --> 普通管理员
# 其他 --> 普通用户
1 #!/usr/bin/env python 2 3 # -*- coding: encoding -*- 4 5 6 7 name = raw_input('请输入用户名:') 8 9 10 11 if name == "lenliu": 12 13 print "超级管理员" 14 15 elif name == "amy": 16 17 print "普通管理员" 18 19 else: 20 21 print "普通用户"
PS:外层变量,可以被内层变量使用,但内层变量,无法被外层变量使用
学习Python与其他语言最大的区别就是,Python的代码块不使用大括号({})来控制类,函数以及其他逻辑判断。python最具特色的就是用缩进来写模块。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行
9.多行语句
Python语句中一般以新行作为为语句的结束符。
但是我们可以使用斜杠( )将一行的语句分为多行显示,如下所示:
1 total = item_one + 2 3 item_two + 4 5 item_three
语句中包含[], {} 或 () 括号就不需要使用多行连接符。如下实例:
1 days = ['Monday', 'Tuesday', 'Wednesday', 2 3 'Thursday', 'Friday']
10、初识基本数据类型
1)、数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
PS:3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
PS:(-5+4j)和(2.3-4.6j)是复数的例子
注:Python中存在小数字池:-5 ~ 257,即
2)、布尔值
真或假 (1 或 0)
3)、字符串
"lenliu"
万恶的字符串拼接“+”:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空间,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化
1 name = "lzl" 2 3 print "I am %s " % name 4 5 输出: I am lzl
PS: 字符串是 %s 整数 %d 浮点数%f
字符串常用功能:
移除空白、分割(split)、长度、索引、切片、连接(join)
4)列表
创建列表:
name_list = ['lenliu', 'seven'] 或
name_list = list(['lenliu', 'seven'])
基本操作:
索引、切片、追加、删除、长度、切片、循环、包含
5)元祖 (不能修改和删除)
创建元祖:
ages = (11, 22, 33, 44, 55) 或
ages = tuple((11, 22, 33, 44, 55))
基本操作:
索引、切片、循环、长度、包含
6)字典(无序)
创建字典:
person = {"name": "lenliu", 'age': 18} 或
person = dict({"name": "lenliu", 'age': 18})
常用操作:
索引、新增、删除、键、值、键值对、循环、长度
PS:循环,range,continue 和 break
11、初识文本的基本操作
打开文件:
file_obj = file("文件路径","模式") 或 file_obj = open("文件路径","模式")
打开文件的模式有:
- r,以只读方式打开文件
- w,打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
- a,打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
- w+,打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
读取文件的内容:
obj.read() # 一次性加载所有内容到内存
obj.readlines() # 一次性加载所有内容到内存,并根据行分割成字符串
for line in obj: # 每次仅读取一行数据
print line
写文件的内容:
obj.write('内容')
关闭文件句柄:
obj.close()