在回归分析中,线性模型的一般预测公式是:
![]()
![]() 是预测值,读作"y hat",是特征的线性组合,把向量w称作 coef_(系数),公式是:
是预测值,读作"y hat",是特征的线性组合,把向量w称作 coef_(系数),公式是:
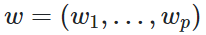
把w0称作intercept_(截距),这两个属性是线性模型的共有属性。
一,线性回归
最基本的线性模型是线性回归,也称作最小二乘法(OLS),线性回归的原理是:计算训练集中y的预测值和其真实值之间的差值的平方Vn,使得Vn的和达到最小。从二维图形来看, 最优拟合曲线应该使各点到直线的距离的平方和(即残差平方和,简称RSS)最小:
![]()
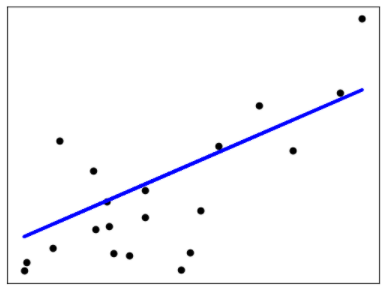
OLS线性回归的目标是通过减少响应变量的真实值与预测值的差值来获得模型参数(截距项和斜率),就是使RSS最小。
举个线性回归(OLS)的例子,通过学习训练集获得模型的参数:coef_(系数)和 intercept_(截距),通过score()来评估模型,满分是1.0,表示模型拟合的优劣程度:
>>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) >>> # y = 1 * x_0 + 2 * x_1 + 3 >>> y = np.dot(X, np.array([1, 2])) + 3 >>> reg = LinearRegression().fit(X, y) >>> reg.score(X, y) 1.0 >>> reg.coef_ array([1., 2.]) >>> reg.intercept_ 3.0000... >>> reg.predict(np.array([[3, 5]])) array([16.])
也可以通过计算预测值和实际值的 Mean squared error 来评估模型。
>>> from sklearn.metrics import mean_squared_error >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> mean_squared_error(y_true, y_pred)
二,岭回归
岭回归(Ridge)实际上是一种改良的OLS,能够避免过拟合的线性模型,在岭回归中,模型会保留所有的特征向量,但是会减少特征变量的系数,让特征变量对预测结果的影响变小,在岭回归中是通过改变alpha参数来控制减少特征向量系数的程度。通过保留全部特征变量,只是降低特征向量的系数值来避免过拟合,这种方法称作L2正则化。
参数alpha称作正则强度,必须为正浮点数,较大的值表示较强的正则化,增加alpha的值会降低特征变量的系数,从而降低训练集对模型的拟合程度,有助于模型的泛化。
>>> from sklearn import linear_model >>> reg = linear_model.Ridge(alpha=.5) >>> reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1]) Ridge(alpha=0.5) >>> reg.coef_ array([0.34545455, 0.34545455]) >>> reg.intercept_ 0.13636...
三,套索回归
套索回归使用L1正则化来增加模型的泛化能力,L1正则化是指不使用全部的特征变量,这就导致在使用套索回归的时候,会有一部分特征的系数等于0,也就是说,有一些特征会被模型忽略。L1正则化把一部分特征的系数变成0,有助于突出体现模型中最重要的那些特征。
>>> from sklearn import linear_model >>> reg = linear_model.Lasso(alpha=0.1) >>> reg.fit([[0, 0], [1, 1]], [0, 1]) Lasso(alpha=0.1) >>> reg.predict([[1, 1]]) array([0.8])
套索回归拥有线性回归的一般属性:coef_ 和 intercept_。套索回归容易发生欠拟合,这意味着模型使用的特征变量过少,这需要通过调节套索回归的alpha来实现,alpha参数用于控制特征变量的系数被约束到0的强度,默认值是1,降低alpha的值会增加特征变量的系数,使特征变量不容易被忽略。实际上,alpha参数可以看作是忽略特征变量的强度,1为最强,0表示使用全部的特征变量。如果把alpha值设置的太低,就等于把正则化效果去除了,模型可能会像线性模型一样,出现过拟合。
四,弹性网模型
弹性网(Elastic Net)模型是一个线性模型,使用L1和L2正则化,是套索回归和岭回归的组合,在实践中这两个模型的组合是最好的,然而代价是用户需要调节两个参数,一个是惩罚因子,另一个是L1和L2的正则化参数,通过控制l1_ratio参数来控制L1和L2的正则化。
sklearn.linear_model.ElasticNet(alpha=1.0, l1_ratio=0.5, ...)
alpha:惩罚因子,默认值是1,如果设置为0,那么等价于OLS。
l1_ratio:对于l1_ratio = 0,惩罚L2正则,对于l1_ratio = 1,惩罚L1正则,对于0 <l1_ratio <1,惩罚是L1和L2的组合。
弹性网(Elastic Net)模型适用于当数据集有很多特征,而这些特征都跟另一个特征相关时,Lasso模型倾向于从这些特征中随机挑选一个,而ElasticNet倾向于全部选择。
在实际的应用中,常常要决定是使用L1正则化还是L2正则化,原则大体上是:如果数据集有很多特征,而这些特征不是每一个都对结果有重要的影响,那么就应该选择L1正则化;如果数据集中的特征不是很多,而且每一个特征都会结果有重要的影响,那么就应该使用L2正则化。
参考文档: