写在前面:该篇文章的内容以及相关代码(代码在最后),都是我亲自手敲出来的,相关结论分析也是花了挺长时间做出来的,如需转载该文章,请务必先联系我,在后台留言即可。
在深度学习中,神经网络的权重初始化方式非常重要,其对模型的收敛速度和性能有着较大的影响。一个好的权值初始值有以下优点:
- 梯度下降的收敛速度较快
- 深度神经中的网络模型不易陷入梯度消失或梯度爆炸问题
该系列共两篇文章,我们主要讨论以下两个话题:
- 为什么在线性回归和逻辑回归中可以采用0初始化,而在神经网络中不能采用(实际上不光是0初始化,将权值初始化为任意相同值,都很有可能使模型失效);
- 常用的三种权值初始化方法:随机初始化、Xavier initialization、He initialization
在这一篇文章中,我们主要谈论第一个话题
0 初始化
在线性回归和逻辑回归中,我们通常把权值 w 和偏差项 b 初始化为0,并且我们的模型也能取得较好的效果。在线性回归和逻辑回归中,我们采用下面的代码将权值初始化为0(tensorflow框架下):
w = tf.Variable([[0,0,0]],dtype=tf.float32,name='weights')
b = tf.Variable(0,dtype=tf.float32,name='bias')
但是,当在神经网络中的权值全部都使用 0 初始化时,模型无法正常工作了。
原因是:在神经网络中因为存在隐含层。我们假设模型的输入为[x1,x2,x3],隐含层数为1,隐含层单元数为2,输出为 y ,模型如下图所示:
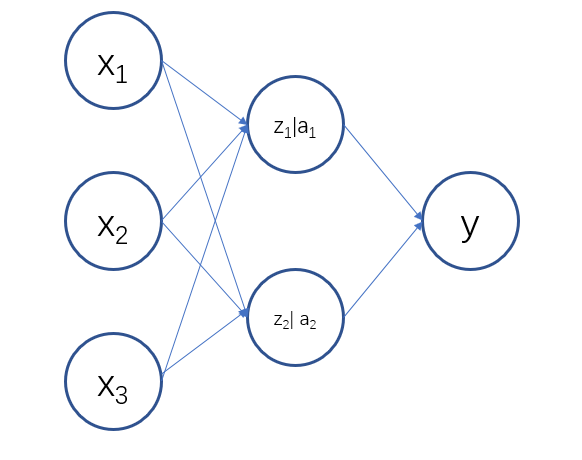
则通过正向传播计算之后,可得:
z1 = w10 * x0 + w11 * x1 + w12 * x2 +w13 * x3
z2 = w20 * x0 + w21 * x1 + w22 * x2 +w23 * x3
在所有的权值 w 和偏差值 b (可以看做是w10)初始化为 0 的情况下,即计算之后的 z1 和 z2 都等于0
那么由于 a1 = g(z1) 、a2 = g(z2),经过激活函数之后得到的 a1 和 a2 也肯定是相同的数了,即 a1 = a2 = g(z1)
则输出层:y = g(w20 * a0 + w21 * a1 + w22 *a2 ) 也是固定值了。
重点:在反向传播过程中,我们使用梯度下降的方式来降低损失函数,但在更新权值的过程中,代价函数对不同权值参数的偏导数相同 ,即Δw相同,因此在反向传播更新参数时:
w21 = 0 + Δw
w22 = 0 + Δw
实际上使得更新之后的不同节点的参数相同,同理可以得到其他更新之后的参数也都是相同的,不管进行多少轮的正向传播和反向传播,得到的参数都一样!因此,神经网络就失去了其特征学习的能力。
在神经网络中使用0 初始化的效果
我们来看一下使用 0 初始化会出现什么样的情况:
我们使用MNIST手写数字数据集进行测试:手写数据集是图像处理和机器学习研究最多的数据集之一,在深度学习的发展中起到了重要的作用。

我们看一下使用权值 0 初始化的神经网络训练并测试该数据集的结果:
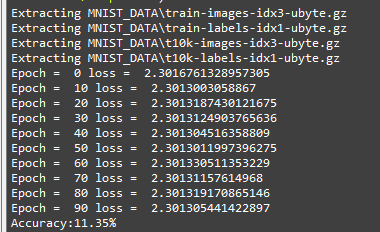
- 在100次的迭代中,每一次迭代,损失值都没有变化
- 模型检测的准确度为11.35%,几乎完全没有检测出来
总结一下:在神经网络中,如果将权值初始化为 0 ,或者其他统一的常量,会导致后面的激活单元具有相同的值,所有的单元相同意味着它们都在计算同一特征,网络变得跟只有一个隐含层节点一样,这使得神经网络失去了学习不同特征的能力!
如果这篇文章帮助到了你,或者你有任何问题,欢迎扫码关注微信公众号:一刻AI 在后台留言即可,让我们一起学习一起进步!

代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed May 8 08:25:40 2019
@author: Li Kangyu
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
import time
# 数据集下载地址:http://yann.lecun.com/exdb/mnist/
MINIBATCH_SIZE = 100
NUM_HD = 100
data = read_data_sets('MNIST_DATA',one_hot=True)
x = tf.placeholder(tf.float32,[None,784])
y_true = tf.placeholder(tf.float32,[None,10])
def nn_model(x):
hidden_layer = {
'w':tf.Variable(tf.zeros([784,NUM_HD])),
'b':tf.Variable(tf.zeros([NUM_HD]))
}
output_layer = {
'w':tf.Variable(tf.zeros([NUM_HD,10])),
'b':tf.Variable(tf.zeros([10]))
}
z1 = tf.matmul(x,hidden_layer['w']) + hidden_layer['b']
a1 = tf.nn.relu(z1)
output = tf.matmul(a1,output_layer['w']) + output_layer['b']
return output
def train_nn(x):
y_pred = nn_model(x)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_pred,labels=y_true))
optimizer = tf.train.AdamOptimizer().minimize(cost)
correct_mask = tf.equal(tf.argmax(y_pred,1),tf.argmax(y_true,1))
accuracy = tf.reduce_mean(tf.cast(correct_mask,tf.float32))
NUM_STEPS = 100
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
for epoch in range(NUM_STEPS):
epoch_loss = 0
num_minibatch = int(data.train.num_examples/MINIBATCH_SIZE)
for _ in range(num_minibatch):
batch_xs,batch_ys = data.train.next_batch(MINIBATCH_SIZE)
_,loss = sess.run([optimizer,cost],feed_dict={x:batch_xs,y_true:batch_ys})
epoch_loss += loss / num_minibatch
if epoch % 10 ==0:
print("Epoch = ",epoch,"loss = ",epoch_loss)
ans = sess.run(accuracy,feed_dict={x:data.test.images,
y_true:data.test.labels})
print("Accuracy:{:.4}%".format(ans*100))
train_nn(x)