在目标检测中有很多常用的数据标注工具,如LabelImg、Labelme等等,经过标注生成的格式各不相同,但基本符合几大数据集的标注格式。
本文用来介绍目标检测中常见的几种数据格式,以及格式之间的相互转换代码。
1、数据格式
我之前整理了图像分类和目标检测领域常用的数据集,点此查看:链接
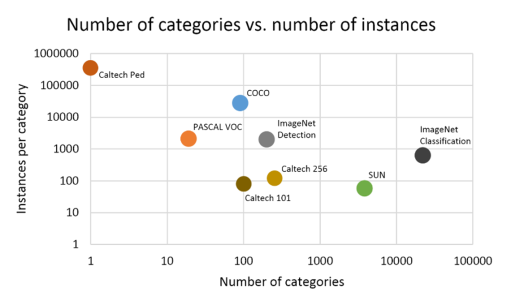
下图也给出了常用的数据集,本文主要关注PASCAL VOC、ImageNet和COCO的标注形式,其中PASCAL VOC和ImageNet使用同样的xml标注格式,COCO为json标注格式。
1.1 PASCAL VOC(xml,csv)
PASCAL VOC挑战赛(The PASCAL Visual Object Classes )是计算机视觉领域最著名的竞赛之一,该竞赛始于2005年,于2012年举办了最后一届。
PASCAL VOC目标检测任务中所使用的的数据集和标注格式为xml,每张图片对应一个xml格式的标注文件。以一个xml文件为例:
xml文件中给出了:图片名称、图像尺寸、标注矩形框坐标、目标物类别、遮挡程度和辨别难度等信息。
<annotation>
<folder>VOC2007</folder>
<filename>test100.mp4_3380.jpeg</filename>
<size>
<width>1280</width> <!--图像尺寸-->
<height>720</height>
<depth>3</depth>
</size>
<object>
<name>banana</name> <!--目标类别-->
<bndbox> <!--GT矩形框坐标-->
<xmin>549</xmin>
<xmax>715</xmax>
<ymin>257</ymin>
<ymax>289</ymax>
</bndbox>
<truncated>0</truncated> <!--物体是否被遮挡(>15%)-->
<difficult>0</difficult> <!--物体是否难以辨别,主要指需结合背景才能判断出类别的物体-->
</object>
<segmented>0</segmented> <!--是否有分割label-->
</annotation>
由于标注文件是每个图像对应一个xml文件,在训练时首先需要将xml文件转为一个统一的csv文件,xml_to_csv的转换代码后面说明。
转换后的数据集为以下格式:
- csv/
- annotation.csv
- images/
- image_1.jpg
- image_2.jpg
- ...
annotation.csv的形式为:
/path/to/image,xmin,ymin,xmax,ymax,class
1.2 COCO(json)
COCO数据集是微软构建的一个数据集,其中包括detection, segmentation, keypoints等任务。从前面的图片也可以看出,COCO数据集的类别总数虽然没有 ImageNet 中用于detection的类别总数多,但是每个类别的实例目标总数要比PASCAL和ImageNet都要多。
使用labelme等标注工具进行标注,同样是一张图片对应一个json文件json格式如下:
{
"version": "3.16.7",
"flags": {},
"shapes": [
{
"label": "scratches",
"line_color": null,
"fill_color": null,
"points": [
[
0.6363636363636402,
96.2809917355372
],
[
199,
123
]
],
"shape_type": "rectangle",
"flags": {}
}
],
"lineColor": [
0,
255,
0,
128
],
"fillColor": [
255,
0,
0,
128
],
"imagePath": "JPEGImages\scratches_100.jpg",
"imageData": "<----太长省略了---->",
"imageHeight": 200,
"imageWidth": 200
}
在训练时,需要将labelme标注的json文件转换成统一的COCOjson文件,注意这两种json格式是有很大差异的。COCO的json文件由以下五个字段组成:
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
"categories": [category]
}
info和licenses字段的内容一般不太关注
images字段是包含了多个image信息的序列,例如下面的这个images包含了4个images的信息,每个图片唯一对应一个id
"images": [
{
"height": 200,
"width": 200,
"id": 0,
"file_name": "scratches_30.jpg"
},
{
"height": 200,
"width": 200,
"id": 1,
"file_name": "scratches_229.jpg"
},
{
"height": 200,
"width": 200,
"id": 2,
"file_name": "scratches_109.jpg"
},
{
"height": 200,
"width": 200,
"id": 3,
"file_name": "scratches_232.jpg"
}
annotations字段是包含多个annotation实例的一个列表,以一个annotation实例为例,内容包括图像id,目标物类别category_id,标注框的坐标信息
"annotations": [
{
"id": 0,
"image_id": 0,
"category_id": 1,
"segmentation": [
[
14,
1,
14,
37.0,
14,
73,
24.0,
73,
34,
73,
34,
37.0,
34,
1,
24.0,
1
]
]}
转换COCO格式的数据集为以下形式:
- csv/
- annotation.csv
- instances_train.json
- instances_val.json
- images/
- image_1.jpg
- image_2.jpg
- ...
- annotation.csv
1.3 YOLO(txt)
labelImg等标注工具,既可以标注生成VOC的xml格式,也可以生成YOLO的txt格式。
YOLO的txt标注文件有两部分组成:类别编号和矩形框坐标。
类别编号:如果都是实现目标检测功能的话,那么所有的类别编号均为0。
矩形框坐标:矩形框坐标为归一化之后的信息,从左到右分别为:中心点x坐标、中心点y坐标,矩形框宽度和矩形框高度
0 0.467785 0.486111 0.054398 0.241770 0 0.311728 0.090021 0.030093 0.179012 0 0.077932 0.201132 0.155093 0.308642 0 0.795139 0.281636 0.233796 0.204218
2、格式转换
篇幅有限,格式转换需要的代码和使用指南我整理汇总到了一起。如果有需要,关注我的公众号一刻AI,回复:数据转换 即可获取
