在之前的博客中已经攻克了人脸检測的问题,我们计划在这篇博客中介绍人脸识别、性别识别方面的相关实现方法。
事实上性别识别和人脸识别本质上是相似的,由于这里仅仅是一个简单的MFC开发,主要工作并不在算法研究上,因此我们直接将性别识别视为一种特殊的人脸识别模式。
人脸识别可能须要分为几十甚至上百个类(由于有几十甚至上百个人)。而性别识别则是一种特殊的人脸识别——仅仅有两个类。
一、基本工具
通过OpenCv进行性别识别的基本工具是FaceRecognizer。这是OpenCv2.x版本号中的一个主要的人脸识别类,它封装了三种基本但也是经典的人脸识别算法:基于PCA变换的人脸识别(EigenFaceRecognizer)、基于Fisher变换的人脸识别(FisherFaceRecognizer)、基于局部二值模式的人脸识别(LBPHFaceRecognizer)。这些算法几乎相同都是十年曾经的人脸识别方法了,因此在今天看来正确率应该不会太让人惬意。只是我们这里重在实践。而非算法研究(尽管本人就是搞图像识别算法研究的),因此我们不会在算法创新方面下太多功夫,所以选择了这三个主要的识别算法。
关于FaceRecognizer类人脸识别的具体操作,这里为大家推荐两篇博客:FaceRecognizer帮助文档以及FaceRecognizer。
这里我们直接使用FaceRecognizer类的相关操作方法。对于其基本使用方法就不再赘述。
二、数据集准备
进行性别识别理所应当须要先准备一些性别识别方面的训练样本。须要强调的一点是。数据集的准备过程中也须要一些小的技巧,在之后我会专门写一篇博文来解释怎样制作一个简易的性别识别训练集。这里我们直接用我已经做好的训练集。下载地址:性别识别数据集
1、概况
我这里整理的性别识别训练集是取自中科院的人脸数据库CAS-PEAL的光照子集,包括400张男性人脸图片和400张女性人脸图片,剩余人脸图片作为測试样本
2、训练集基本结构
训练集包括三部分:男性样本、女性样本、測试样本:
这里我们通过CSV文件方法来批量读取训练样本。因此这里提前制作了一个txt文件来存储每个训练样本图片的路径:
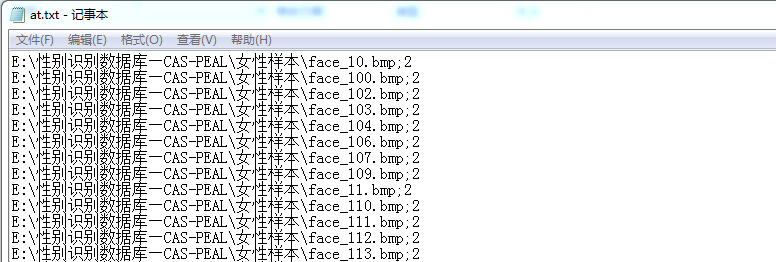
注意这里at.txt文件里的路径实际上是由两部分内容组成,即“路径。性别标号”。性别标号“1”代表男性,“2”代表女性。至于怎样通过csv文件方法来批量读取文件,參见:一种批量读取文件的方法—CSV文件。
同理,在測试样本中相同须要用txt文件来记录样本路径和标签:

三、识别算法的训练与測试
1、新建一个控制台project。配置OpenCv
这里不再赘述。建议加上预编译头就可以。这里project名暂定为GenderRecognition
2、编写批量读取文件函数read_csv()
首先。批量txt文件是典型的io操作。须要包括下面头文件:
#include <iostream> #include <sstream> #include <fstream>
然后開始编写read_csv函数。函数相对照较简单,这里直接给出代码:
void read_csv(string& fileName,vector<Mat>& images,vector<int>& labels,char separator = ';') { ifstream file(fileName.c_str(),ifstream::in); //以读入的方式打开文件 String line,path,label; while (getline(file,line)) //从文本文件里读取一行字符。未指定限定符默认限定符为“/n” { stringstream lines(line); getline(lines,path,separator); //依据指定切割符进行切割,分为“路径+标号” getline(lines,label); if (!path.empty()&&!label.empty()) //假设读取成功,则将图片和相应标签压入相应容器中 { images.push_back(imread(path,1)); //读取训练样本 labels.push_back(atoi(label.c_str())); //读取训练样本标号 } } }
read_csv()函数的主要功能就是读取指定文件夹下的路径文件(比如这里的at.txt),然后依据路径文件里的记录,逐行读入相应路径的训练样本路径及其标号,并放入相应容器(vector)中。至于为什么採用vector数据结构来存储训练样本。一是由于这样做简单直观。二是由于OpenCv的训练函数提供的是vector接口。当然这样做也存在一定弊端,就是必须一次性将训练样本所有读入到内存中,当训练样本数量庞大时这样的方法不但会消耗掉巨额内存,并且效率低下。
很多其它关于read_csv()批量读取的知识參见一种批量读取文件的方法—CSV文件。
3、读入训练样本
接下来在主函数中调用read_csv()函数,读取训练样本及标签。并放入相应容器中:
int _tmain(int argc, _TCHAR* argv[]) { String csvPath = "E:\性别识别数据库—CAS-PEAL\at.txt"; vector<Mat> images; vector<int> labels; read_csv(csvPath,images,labels); return 0; }
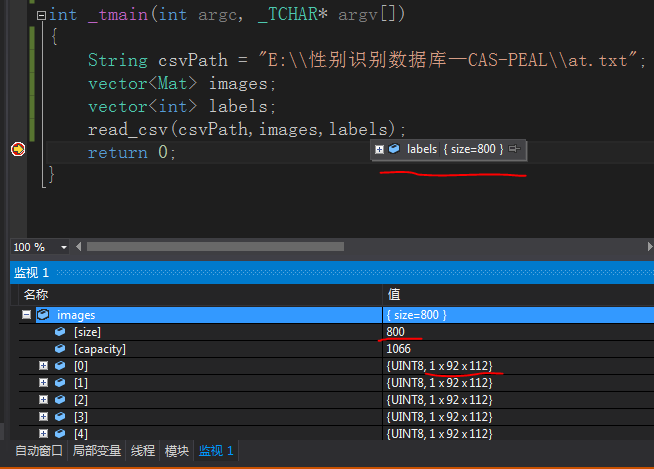
读取成功,images和labels两个容器都包括800个样本:
4、训练分类器
OpenCv中的FaceRecognizer类提供的分类器训练API函数很easy。仅仅需三句话,以EigenFaceRecognizer为例:
Ptr<FaceRecognizer> modelPCA = createEigenFaceRecognizer(); modelPCA->train(images,labels); modelPCA->save("E:\性别识别数据库—CAS-PEAL\PCA_Model.xml");
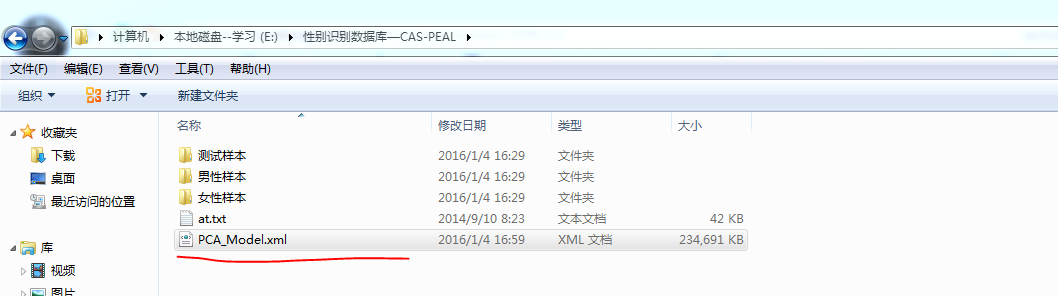
训练完毕后(大约五分钟左右),训练好的分类器已经以XML文件的形式保存在了指定路径下:
同理,训练FisherFaceRecognizer、LBPHFaceRecognizer两个分类器并保存:
Ptr<FaceRecognizer> modelFisher = createFisherFaceRecognizer(); modelFisher->train(images,labels); modelFisher->save("E:\性别识别数据库—CAS-PEAL\Fisher_Model.xml"); Ptr<FaceRecognizer> modelLBP = createLBPHFaceRecognizer(); modelLBP->train(images,labels); modelLBP->save("E:\性别识别数据库—CAS-PEAL\LBP_Model.xml");
得到另外两个分类器:
4、測试分类器
训练完分类器后,接下来我们介绍怎样使用这些训练好的分类器对測试样本进行分类。
首先载入三个分类器
Ptr<FaceRecognizer> modelPCA = createEigenFaceRecognizer(); Ptr<FaceRecognizer> modelFisher = createFisherFaceRecognizer(); Ptr<FaceRecognizer> modelLBP = createLBPHFaceRecognizer(); modelPCA->load("E:\性别识别数据库—CAS-PEAL\PCA_Model.xml"); modelFisher->load("E:\性别识别数据库—CAS-PEAL\Fisher_Model.xml"); modelLBP->load("E:\性别识别数据库—CAS-PEAL\LBP_Model.xml");
然后读入一张測试样本,通过三个分类器对其进行预測:
Mat testImage = imread("E:\性别识别数据库—CAS-PEAL\測试样本\男性測试样本\face_480.bmp",0); int predictPCA = modelPCA->predict(testImage); int predictLBP = modelLBP->predict(testImage); int predictFisher = modelFisher->predict(testImage);
预測结果如图:
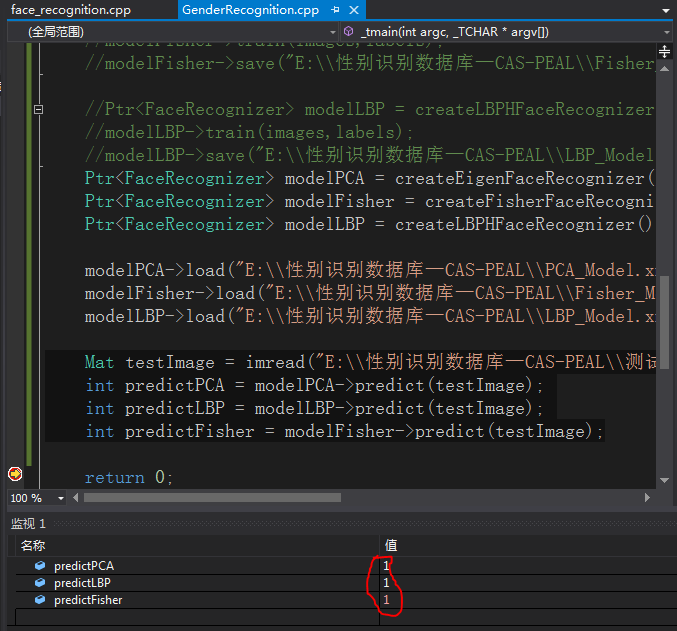
可见对于这张測试图片,三个分类器均给出了正确预測(数字“1”代表男性),正确率能够接受。
四、代码
这部分博客所涉及的代码相同较为简洁,因此在这里给出总体代码:
// GenderRecognition.cpp : 定义控制台应用程序的入口点。 // #include "stdafx.h" #include <opencv2opencv.hpp> #include <iostream> #include <sstream> #include <fstream> using namespace std; using namespace cv; void read_csv(string& fileName,vector<Mat>& images,vector<int>& labels,char separator = ';') { ifstream file(fileName.c_str(),ifstream::in); //以读入的方式打开文件 String line,path,label; while (getline(file,line)) //从文本文件里读取一行字符,未指定限定符默认限定符为“/n” { stringstream lines(line); getline(lines,path,separator); //依据指定切割符进行切割。分为“路径+标号” getline(lines,label); if (!path.empty()&&!label.empty()) //假设读取成功。则将图片和相应标签压入相应容器中 { images.push_back(imread(path,0)); //读取训练样本 labels.push_back(atoi(label.c_str())); //读取训练样本标号 } } } int _tmain(int argc, _TCHAR* argv[]) { String csvPath = "E:\性别识别数据库—CAS-PEAL\at.txt"; vector<Mat> images; vector<int> labels; read_csv(csvPath,images,labels); Ptr<FaceRecognizer> modelPCA = createEigenFaceRecognizer(); modelPCA->train(images,labels); modelPCA->save("E:\性别识别数据库—CAS-PEAL\PCA_Model.xml"); Ptr<FaceRecognizer> modelFisher = createFisherFaceRecognizer(); modelFisher->train(images,labels); modelFisher->save("E:\性别识别数据库—CAS-PEAL\Fisher_Model.xml"); Ptr<FaceRecognizer> modelLBP = createLBPHFaceRecognizer(); modelLBP->train(images,labels); modelLBP->save("E:\性别识别数据库—CAS-PEAL\LBP_Model.xml"); //Ptr<FaceRecognizer> modelPCA = createEigenFaceRecognizer(); //Ptr<FaceRecognizer> modelFisher = createFisherFaceRecognizer(); //Ptr<FaceRecognizer> modelLBP = createLBPHFaceRecognizer(); modelPCA->load("E:\性别识别数据库—CAS-PEAL\PCA_Model.xml"); modelFisher->load("E:\性别识别数据库—CAS-PEAL\Fisher_Model.xml"); modelLBP->load("E:\性别识别数据库—CAS-PEAL\LBP_Model.xml"); Mat testImage = imread("E:\性别识别数据库—CAS-PEAL\測试样本\男性測试样本\face_480.bmp",0); int predictPCA = modelPCA->predict(testImage); int predictLBP = modelLBP->predict(testImage); int predictFisher = modelFisher->predict(testImage); return 0; }
四、总结
这篇博客主要介绍了怎样使用OpenCv提供的人脸识别类FaceRecognizer来进行性别识别,并提供了一段win32控制台project下的简洁代码,同一时候,有下面几个方面须要特别注意一下。
1、人脸识别和性别识别的关系
在这篇博客的開始部分曾提到过性别识别和人脸识别的关系。在这里须要再次强调一下。性别识别本质上属于人脸识别。可是和人脸识别还是有非常多方面的差别。
性别识别是二分类问题,人脸识别是多分类问题,二者在算法上也有非常大差异。我们这里之所以简单的将性别识别看做简化的人脸识别。是由于在这套教程中我们主要注重实践,注重OpenCv的使用以及MFC框架编程方法。因此在算法方面会显得不够严谨。因此希望大家不要被这些简化的观点所误导。真正的性别识别算法也远比这些复杂,也和人脸识别方法大不同样,作为图像处理的行内人。我认为非常有必要把这点说清楚。
2、read_csv函数
这里对read_csv()批量读取函数介绍得相对简洁,大家能够參照我提供的博客来进行具体学习。同一时候考虑到这个函数相对简洁,能够凡在main()函数之前,从而避免提前声明。
3、数据集原始路径问题
这篇博文中并没有具体介绍怎样制作性别识别训练数据集。因此大家在使用网上下载的数据集时一定要注意路径的问题。
下载后数据集必须放在E盘根文件夹下,否则的话则须要又一次制作路径文件(at.txt)。只是这一步也并不复杂,參见一种批量读取文件的方法—CSV文件。
同一时候,这里在向路径文件后边加入类别标号时,当初我採用的是手动加入的方式,只是我相信大家可以找到更为简便的加入方式。
这里之所以没有介绍数据集的制作,是由于我计划将这部分内容作为程序的一个附加功能来单独进行介绍(也就是所谓的“人脸批量切割”),在之后进入到MFC编程部分时会进行专门的介绍。
4、关于性别识别的其它方法
在接下来的博文中我会介绍性别识别中的第二种基础方法——SVM方法。