定义:
一颗二叉查找树(BST)是一颗二叉树,其中每个结点都含有一个Comparable的键(及其相关的值),每个结点的键都大于左子树中任意结点的键且小于右子树任意结点的键。
基本实现:
我们定义一个私有类来表示二叉查找树上的一个结点,每个结点含有一个键,一个值,一条左链接,一条右链接和一个结点计数器(统计以该节点为跟的子树的结点的总数,空链接计为0).对于任意结点X,以下公式总是成立
size(X)=size(X.left)+size(X.right)+1;
内部类代码:


1 public class BST<T extends Comparable<T>,E> {//T代表key,E代表value 2 private class Node 3 { 4 private T t; 5 private E e; 6 private Node left,right; 7 private int N; 8 9 public Node(T t,E e,int N) 10 { 11 this.t=t; 12 this.e=e; 13 this.N=N; 14 } 15 } 16 public int size() 17 { 18 return size(root); 19 } 20 private int size(Node x) 21 { 22 if(x==null) return 0; 23 return x.N; 24 } 25 26 }
一颗二叉查找树代表了一组键(及值)的集合,而同一个集合可以用不同的二叉树表示,如图:
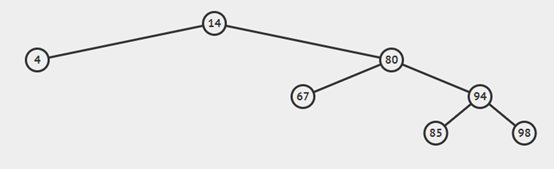
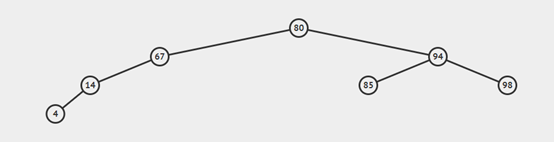
查找:
查找有两种情况,命中和未命中。具体算法为:如果树是空的,则未命中,如果被查找的键和根结点相等,命中,否则就递归的在子树中继续查找。如果被查找的键小于根结点的键就选择左子树,大于就选择右子树。
代码实现:
1 public E get(T t) 2 { 3 return get(root,t); 4 } 5 private E get(Node x,T t) 6 { 7 if(x==null) return null; 8 int cmp=t.compareTo(x.t); 9 if(cmp<0) return get(x.left,t); 10 else if(cmp>0) return get(x.right,t); 11 else return x.e; 12 13 }
插入:
二叉查找树的一个特征就是插入的实现操作和查找差不多,当查找一条不存在的结点并结束于一条空链时,我们要做的就是将这个链接直线被查找的这个新结点
代码实现:
1 public void put(T t,E e) 2 { 3 root=put(root,t,e); 4 } 5 private Node put(Node x,T t,E e) 6 { 7 if(x==null) return new Node(t,e,1); 8 int cmp=t.compareTo(x.t); 9 if(cmp<0) x.left=put(x.left,t,e); 10 else if(cmp>0) x.right=put(x.right,t,e); 11 else x.e=e; 12 x.N=size(x.left)+size(x.right)+1; 13 return x; 14 }
算法分析:
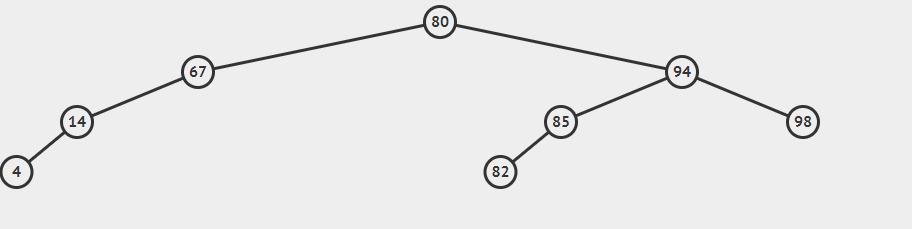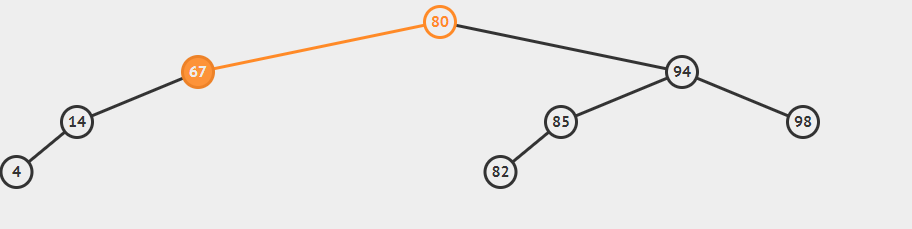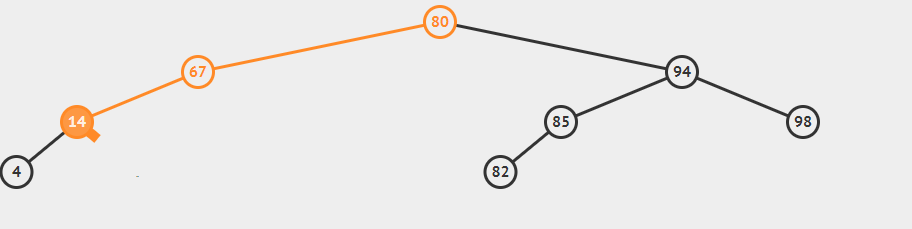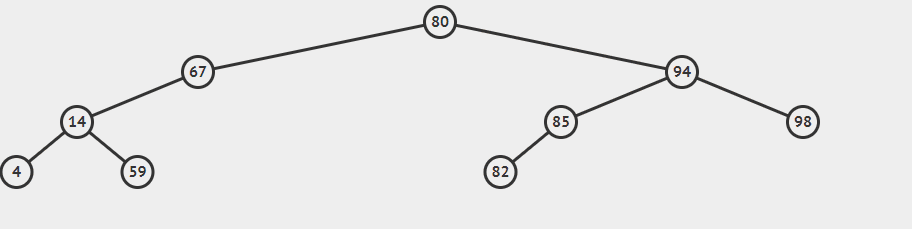
插入59的gif
对于put方法,当创建新链接时,新链接就是在最底层指向新节点的链接,我们需要将路径上的每个结点的计数器+1,很多时候get和put方法都是非递归的。
非递归代码:
1 public E get0(T t) 2 { 3 Node x=root; 4 while(x!=null) 5 { 6 int cmp=t.compareTo(x.t); 7 if(cmp<0) x=x.left; 8 else if(cmp>0) x=x.right; 9 else return x.e; 10 11 } 12 return null; 13 14 }
对于非递归的put()方法,实现起来有点复杂,因为它需要保存一个指向底层结点的链接,以便使之称为新节点的父节点。还需要额外遍历一遍查找路径来更新所有结点计数器来保证正确性。为方便起见,我们这里暂时不考虑计数器问题。
同时,Node类有一个新的构造方法
public Node(T t,E e)
{
this.e=e;
this.t=t;
}
代码实现:
1 public void put0(T t,E e) 2 { 3 Node node=new Node(t,e); 4 if(root==null) 5 { 6 root=node; 7 return; 8 } 9 10 Node parent=null,x=root; 11 while(x!=null) 12 { 13 parent=x; 14 int cmp=t.compareTo(parent.t); 15 if(cmp>0) x=x.right; 16 else if(cmp<0) x=x.left; 17 else 18 { 19 x.e=e; 20 return; 21 } 22 } 23 int cmpkey=t.compareTo(parent.t); 24 if(cmpkey<0) 25 parent.left=node; 26 else parent.right=node; 27 28 }
因为在实际操作中,查找次数远远多于插入次数,所以这两段非递归代码,get()可以使用,至于put则无关紧要。
分析:
使用二叉查找树的运行时间主要取决于树的形状,而树的形状又取决于键的插入顺序。
如图,
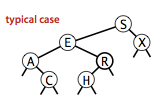
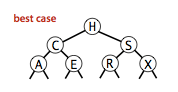
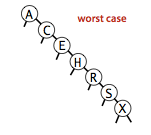
依次为一般情况,最好情况和最坏情况
有序性相关方法及删除操作:
最大结点和最小结点
如果根结点的左链接为空,那么一颗二叉查找树的最小键就是根结点;如果左链接非空,那么最小键就是左子树的最小键找最大键的方法也是类似的,只不过是换成右子树而已。
代码实现:
1 public T min() 2 { 3 return min(root).t; 4 } 5 private Node min(Node x) 6 { 7 if(x==null) return null; 8 return min(x.left); 9 }
向上取整和向下取整
如果给定的键key小于二叉查找树的根节点,那么小于等于key的最大键floor(key)一定存在在根结点的左子树中;如果给定的键key大于根结点那么只有当根结点的右子树中存在小于等于key的结点时,小于等于key的最大键才会出现在右子树中,否则根结点就是小于等于key的最大键,对于ceiling(),只需要将左变为右,小于变为大于即可。
代码实现:
1 public T floor(T t) 2 { 3 Node x=floor(root,t); 4 if(x==null) return null; 5 return x.t; 6 } 7 8 private Node floor(Node x,T t) 9 { 10 if(x==null) return null; 11 int cmp=t.compareTo(x.t); 12 if(cmp==0) return x; 13 if(cmp<0) 14 return floor(x.left,t); 15 Node node=floor(x.right,t); 16 if(node!=null) return node; 17 else return x; 18 19 }
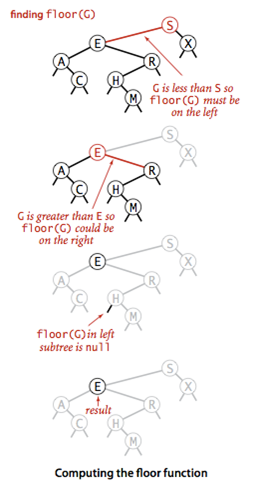
对这段代码做一个说明,首先,对于一个二叉搜查找树,我们能很方便的将它转为一个有序列,例如上图可化为A、C、E、H、M、R、S、X。当执行floor(g)时,发现G在E和H之间,所以此时返回E,如果是ceiling(G),则返回H。
(1) floor(S,G),跳过if(x==null)语句,发现cmp<0,
(2) 执行floor(E,G)跳过if(x==null)语句,发现cmp>0
(3) 继续执行Node node=floor(x.right,G),
(4)对于floor(x.right,G),跳过if(x==null)语句,发现cmp<0
(5) 执行floor(H,G)跳过if(x==null)语句,发现cmp<0
(6) 执行floor(H.left,G)if(x==null)语句执行,返回null;
(7)node为空,继续执行else return x;此时x为E,返回E,结束。
选择操作:
如果我们想查找排名为K的键(数树中正好有k个小于他的键),如果左子树的结点数t>k,那么就在左子树中继续寻找,如果等于k,那么就返回根结点,如果t<k,那么就在右子树中寻找排名为(k-t-1)的键。
代码实现:
1 public E select(int k) 2 { 3 return select(root,k).e; 4 } 5 private Node select(Node x,int k) 6 { 7 if(x==null) return null; 8 int num=size(x.left); 9 if(num>k) return select(x.left,k); 10 else if(num<k) return select(x.right,k-num-1); 11 else return x; 12 13 14 }
排名:
这是select的逆方法,他会返回给定键的排名
1 public int rank(T t) 2 { 3 return rank(root,t); 4 } 5 private int rank(Node x,T t) 6 { 7 if(x==null) return 0; 8 int cmp=t.compareTo(x.t); 9 if(cmp<0) 10 return rank(x.left,t); 11 else if(cmp>0) 12 return size(x.left)+1+rank(x.right,t); 13 else 14 return size(x.left); 15 16 }
删除方法:
上面介绍的方法都相对简单,而将要介绍的delete()方法是最难的一个,我们先来学习一下deleteMIn(),即删除最小键对应的值。我们要不断深入根结点的左子树直至遇到一个空连接,然后将指向该结点的链接指向指向该节点的右子树,此时已经没有任何链接指向要被删除的结点,因此它会被垃圾回收处理掉。如图
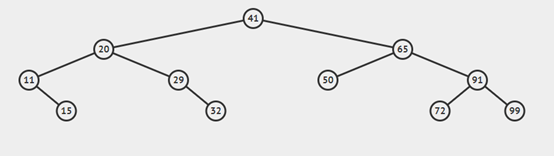
我们删除最小结点
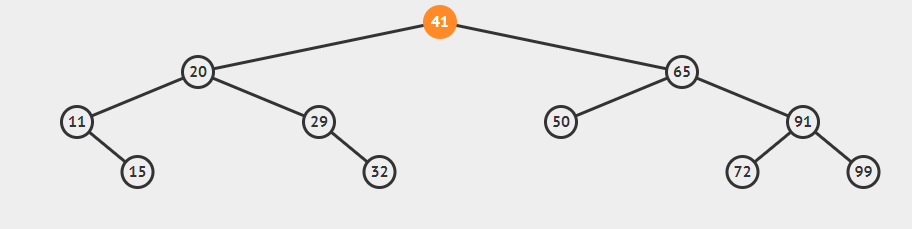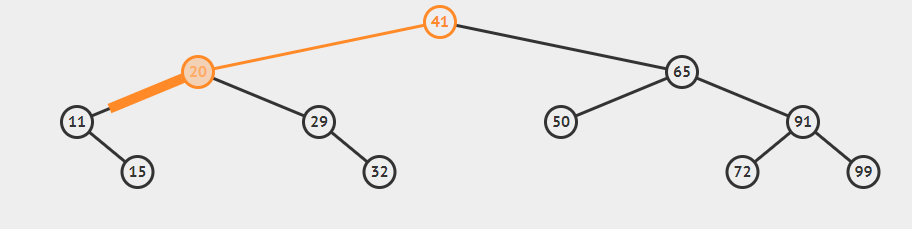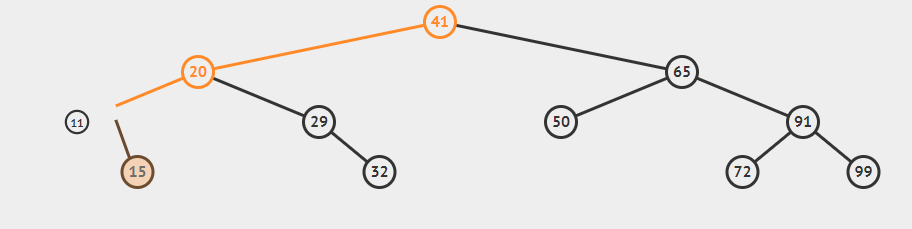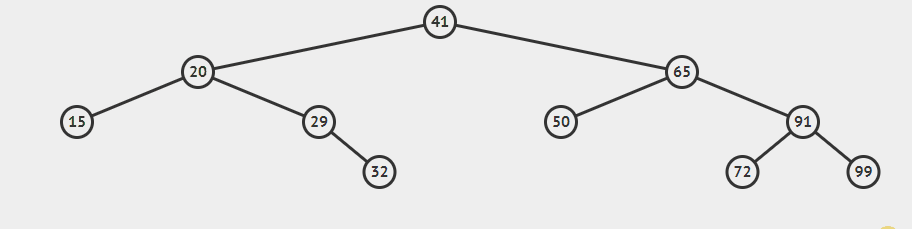
算法轨迹分析
(1)、deleteMin(41),x.left为20,if(x.left==null)不成立,跳过
(2)x.left=deleteMin(20),对于deleteMin(20),x.left=11(与前面不是同一个),if(x.left==null)不成立,跳过
(3)x.left=delete(11),对于delete(11),x.left==null,返回x.right(即15)。x.left=15,这里的x指的是20。
利用这种方法也可以删除任意一个只有一个子结点或没有子结点的结点
删除操作:(重点)
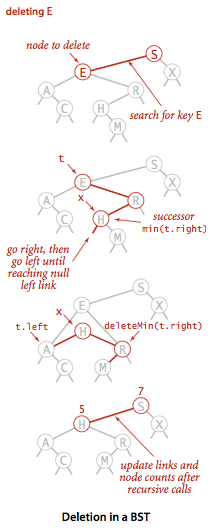
在删除结点X后用他的后继结点来填补他的位置,它的后继结点其实就是他的右子树中的最小结点,这样的替换能保证树的有序性,因为X和它的后继结点之间没有其他结点。
(1):将指向即将被删除的结点的链接保存为t;
(2): 将X指向它的后继结点,即min(t.right);
(3):将x的右链接指向deleteMIn(t.right)
(4):将X的左链接设为t.left
代码实现:
1 private Node deleteMin(Node x) 2 { 3 if(x.left==null) return x.right; 4 x.left=deleteMin(x.left); 5 x.N=size(x.left)+size(x.right)+1; 6 return x; 7 } 8 9 public void delete(T t) 10 { 11 root=delete(root,t); 12 } 13 private Node delete(Node x,T t) 14 { 15 if(x==null) return null; 16 int cmp=t.compareTo(x.t); 17 18 if(cmp<0) x.left=delete(x.left,t); 19 else if(cmp>0) x.right=delete(x.right,t); 20 else 21 { 22 if(x.right==null) return x.left; 23 if(x.left==null) return x.right; 24 Node node=x; 25 x=min(x.right); 26 x.right=deleteMin(node.right); 27 x.left=node.left; 28 29 30 } 31 x.N=size(x.left)+size(x.right)+1; 32 return x; 33 }
算法轨迹
分析
分析算法:
主要分析else里的代码块
对于一个将要被删除的结点,
如果它的左链接为空,那么它的位置将被右链接代替,反之亦然。如果都为空就变成了deleteMin()类似的了。对于上图,我们要删除E结点,我们在排序的时候已经了解到,对于一个结点,要先取值(或则说保存原有结点的引用),在赋值,这样才不会破坏完整性。我们先将X的原有引用保存起来(t),接着利用min()方法找出t的右子树中的最小结点,用这个代替X,其实右子树中还存在这个结点,我们需要将这个结点删除掉,即调用deleteMin(),然后将新节点的右子树指向删除了最小结点的新的右子树。最后将原来的左子树(由t保存着引用关系)连接到新节点。