MapReduce
一种分布式计算框架,负责离线计算,输入就是HDFS文件系统的数据块。
优:处理大量数据,隐藏细节,自动化并行,负载均衡和容错机制,可以增加集群中的机器
劣:实时性差,响应缓慢
一个典型的MapReduce往往由几千台机器组成,处理以TB计算的数据。
编程模型
利用输入的key/value 集合产生一个输出的key/value 集合
一共两个函数表达这个计算:Map 和 Reduce
用户自定义的Map函数接受一个输入的 key/value 值,然后产生一个中间key/value 集合。MapReduce库把所有相同的key值的中间value值放到一个集合传给reduce函数
用户自定义的reduce函数接受一个中间key值,和相关value值的集合。Reduce函数合并这些value,形成较小的value值的集合。这样就可以把无法全部存入内存的value减少
map(k1,v1)->list(k2,v2). k1:文件名,v1:文件下的内容。 k2:单词,v2:出现次数
reduce(k2, list(v2))->list(v2). k2:单词 ,list(v2)同个单词不同位置出现的次数 list(v2)再次合并
例如:要处理一个文件中每个单词个数
Map函数:把每个单词取出来,产生一个个key/value对为:单词/1
Reduce函数:对于同是一个单词,个数相加即可
实现
执行概括
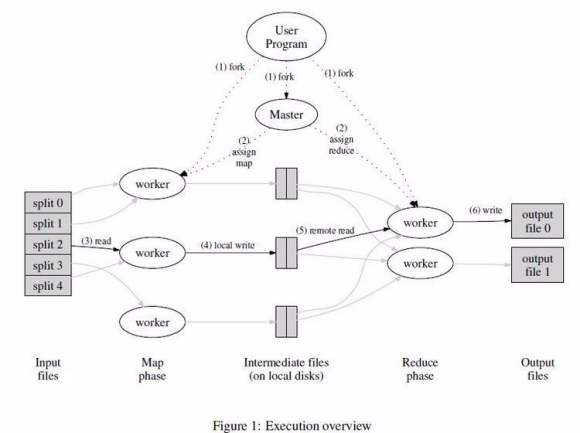
通过Map调用的输入数据自动分为M个数据片段的集合,Map调用被分布在堕胎机器上执行。输入的数据片段能够在不同的机器上并行处理。使用分区函数将Map调用产生的中间key值分成R个不同分区,Reduce调用也被分布到多个机器上执行。书去数量R和分区函数也是用户指定的。
1.用户程序调用MapReduce库将输入文件分成M个数据片段,数据片段大小一般从16MB到64MB(可以通过参数更改)。然后用户程序中机群中创建大量的程序副本。
2.这些程序副本中有一个特殊程序-master。其他都是worker,由master分配任务,有M个Map任务和R个Reduce任务将被分配,master将每个Map任务或Reduce任务分配给一个空闲的worker。
3.被分配map任务的worker程序读取相关的输入数据片段,从中解析出key/value,然后把key/value传递给用户自定义的Map函数,由Map函数生成并输出中间的key/value缓存到内存。
4.缓存中的key/value 通过分区函数分成R个区,之后周期性写入到本地磁盘上,缓存的key/value 在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置传给Reduce worker
5.当Reduce worker程序接受到master程序发来的数据位置后,使用RPC从Map worker所在主机的磁盘上读取这些存储数据。读取结束以后通过对key的排序,是相同key值聚合在一起。(若内部无法排序,就要在外部排序)
6.Reduce worke程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce worker程序将这个key值和它相关的中间value值的集合传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区到输出文件。
7.当所有Map和Reduce任务都完成以后,master唤醒用户程序。在这个时候,在用户程序里的对MapReduce调用才返回。
任务完成以后,MapReduce的输出会存在在R个输出文件。一般情况下,用户不需要将这R个输出文件合并成一个文件(通常作为另一个MapReduce的输入,或在另一个能处理多个分割文件的分布式应用中使用)
Master数据结构
Master持有一些数据结构,它存储每个Map和Reduce任务的状态,以及Worker机器(非空闲)的标识。
Master如同数据管道,中间文件存储区域的位置信息通过这个管道从Map传递到Reduce。master存储来Map任务产生的R个文件区域的大小和位置,每当Map完成,Master就会跟新位置和大小信息
容错
由于MapReduce设计初衷就是用成百上千的集群来处理超大规模数据,所以这个库必须能很好的处理机器故障。
worker故障
master会周期性的ping每个worker.如果一个约定时间内没收到worker返回的信息,master将把这个worker标记为失效。所有由这个worker完成的Map任务被重设为初始状态,之后就可以安排给其他worker。同样的,worker失效时正在运行的Map和Reduce任务也被重置为空闲状态
当worker故障时,由于完成的Map任务的输出(3)存储在这台机器上,所以必须重新执行,但Reduce任务的输出(5)在全局文件系统,所以不需要重新执行
当一个Map任务首先被worker A执行,之后A失效以后被worker B执行,这个重新执行的动作会被通知给所有执行Reduce任务的worker。任何还没有从A读取数据的Reduce任务都将从B读取数据
master失败
简单的方法是让master周期性将上面的数据结构写入磁盘,即检查点。一旦master任务失效,可以从最后一个检查点启动另一个master进程。通常来说重启很麻烦,我们都会中止MapReduce,让客户根据需要重新执行MapReduce
在错误面前的处理机制
当用户提供的map和reduce操作对它的输出值是确定的函数时,我们的分布式实现产生,和全部程序没有错误的顺序执行一样,具有相同输出
存储位置
为了节省网络带宽,通常把输入数据存在多个机器的本地磁盘,GFS把每个文件按64MB一个Block,每个Block保存在多台机器上(一般是3个)。master在调度Map任务时会考虑输入文件的位置信息,尽量将一个Map任务调度在包含相关数据的机器执行,如果失败也会尝试在含有数据附近的机器执行。对于足够大的cluster集群,大部分都能在本地读取,仅消耗很少的带宽。
任务粒度
对于Map我们拆成M个片段,Reduce拆分成R个片段。理想情况下,M和R应当比worker机器多得多。这样的话,能动态均衡每个机器的负载,加快故障恢复的速度。
实际上,M和R的取值有一定的限制,因为master必须执行O(M+R)次调度,在内存保存O(M*R)个状态(内存因素较小,O(M*R)块状态,大概每次对Map/Reduce 任务1个字节即可)
R值通常都会由用户指定,因为每个Reduce任务最终都会生成一个独立的输出文件。因此通常我们倾向于选择合适的M值,R值通常用worker数量较小的倍数。例如M=2000000,R=5000,2000台worker。
备用任务
由于MapReduce的总执行时间通常的因素时落伍者(一个机器出现了问题,例如硬盘读取速度变慢等),导致一台机器花了很多时间去执行最后几个Map或Reduce任务。
处理办法:在MapReudce操作接近完成时,master调度备用任务执行剩下的,处于处理中状态的任务。无论是原始还是备用任务谁先完成,我们都将这个任务标记成已经完成。
技巧
虽然Map和Reduce函数提供的基本功能已经满足大部分需要,但我们还是可以增加一些扩展
分区函数
可以用hash方法,例如hash(key)mod R 产生均衡的分区。
顺序保证
我们保证给定的粪污中,中间key/value 对 数据的处理顺序是按照key递增处理的。这样能生成一个有序的输出文件。
Combiner函数
由于Map函数产生的中间key值重复率很大,而且用户自定义的Reduce函数满足结合律和交换律(例如:之前的单词记数),那我们可以现在本地将这些记录合并一次,也就是允许用户指定一个可选择的combiner函数,将合并以后的再通过网络发送出去。
Combiner函数会在每台Map任务的机器上都执行一次。一般来说Combiner和Reduce函数是一样的。唯一区别就是如何控制函数输出,Reduce的输出保存在最终的输出文件里。Combiner被写在中间文件。
输入输出的类型
MapReduce库支持几种不同格式的输入数据。例如:文本数据的每一行被视为一个key/value 对。key是文件的偏移量,value是那一行的内容。另一种是以key进行排序来存储的key/value 对的序列。但每种谁让类型都必须能把数据分割为数据片段,该数据片段能够由单股的Map任务来进行后续处理。对于某些使用者可以提供一个Reader接口来支持一个新的输入类型。Reader并非从文件读取,也可以从数据库或者内存读取
同理,我们提供了预定义的输出数据类型,也可以用户自己添加(类似于Reader的输出类型
跳过损坏的记录
有时候,用户程序的bug会导致Map/Reduce函数崩溃。通常会找到bug然后修复它,但有时候bug会在第三方数据里,而且很多时候忽略一些有问题的记录也是可以接受的,因此我们为了保证整个处理可以继续,MapReduce会记录那些记录导致崩溃,并且跳过他们。
每个worker都设置了信号处理函数捕获一场,当触发了异常,小心函数会用“最后一口气“通过UDP包向master发型处理的最后一条记录。当maste看到某个记录失败很多次,master就标记这条记录需要被跳过。
状态信息
master使用嵌入式的HTTP服务器显示一组状态信息页面,用户可以监控各种执行状态。例如:计算执行速度,完成多少任务,有多少任务正在处理,输入的字节数.......胡同可以根据这些数据预测计算需要执行大约多久,是否增加额外的计算资源,
另外,最顶层的状态页面显示了哪些worker失效了,以及他们失效时候运行的Map和Reduce,这些信息对于调试用户代码中的bug很有帮助。
计数器
MapReduce库 使用计数器统计不同事件发生的次数。比如,已经统计多少单词,或者索引的多少篇文档
性能
衡量MapReduce的性能的两个计算。一个是计算大约1TB数据中进行特定的模式匹配,另一个是对大约1TB的数据进行排序。
在实际应用中。一个是对数据格式进行转换,另一个是从海量数据中抽取少部分的用户感兴趣的数据。
GREP(强大的文本搜索工具,输出匹配行)
这个分布式的grep程序需要扫描大概10的10次方个由100个字节组成的记录,查找出现概率较小的3个字符模式。输入的数据被拆分成大约64M的Block,整个输出数据存放在一个文件中。
上图显示:Y轴为处理速度,处理速度随着参与MapReduce计算的机器数量的增加而增加,当1764台worker参与计算时,速度达到30GB/s。当计算到80秒以后,输入的处理速度降为0.整个计算大约150秒,其中还包括了大约1分钟的初始启动阶段。
排序
排序程序处理10点10次方个100字节组成的记录(大概1TB的数据)
排序程序由不到50行代码组成。
图三(a)显示了这个排序的正常执行过程
磁盘写入速度中2-4GB/s持续一段时间。输出数据写入磁盘大约持续850秒。整个运算大约891秒。
高效的backup任务
图三(b)显示关闭了备用任务后排序程序执行情况。与a基本相似,但输出数据写磁盘的时候拖了很长时间,最后960秒只有5个Reduce任务没有完成。这些拖后腿的任务耽误了300多秒。
失效的机器
图三(c)演示的是,程序开始后几分钟kill了1746个worker中200个。集群底层的调度立即重新开始新的worker处理进程
显得的负的输入读取速度,是因为一些完成的Map任务丢失了,需要重新执行。但整个运算时间在933秒完成,仅仅多了5%