作业一
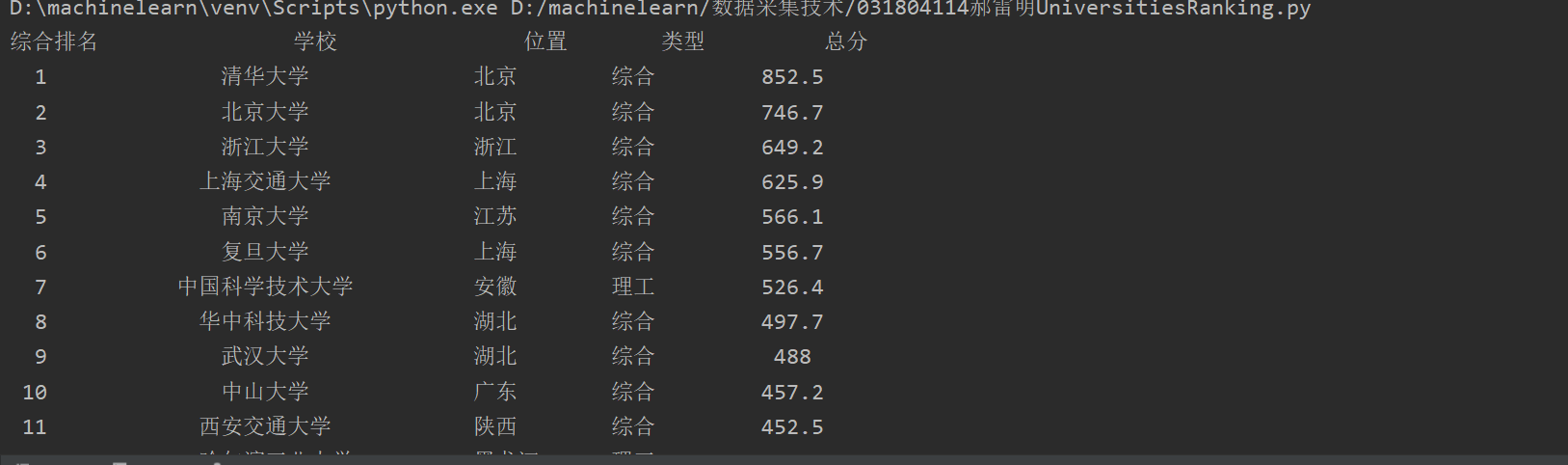
(1)用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "lxml")
for tr in soup.find('tbody').children:#子节点
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].text.strip(), tds[1].text.strip(), tds[2].text.strip(), tds[3].text.strip(),
tds[4].text.strip()])
def printUnivList(ulist, num):
tplt='{0:^5} {1:{5}^15} {2:^5} {3:^10} {4:^5}'
print(tplt.format('综合排名','学校','位置','类型','总分',chr(12288)))#chr(12288)是中文空格填充字符
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],u[3],u[4],chr(12288)))
def main():
unifo=[]
url='http://www.shanghairanking.cn/rankings/bcur/2020'
html=getHTMLText(url)
fillUnivList(unifo, html)
printUnivList(unifo, 40)
#爬40所学校
main()
(2)心得体会
网址的变动带来一些小麻烦,又去百度了一些新知识点,都是知识点
作业二
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm031804114 time:2020/9/22
import requests
from bs4 import BeautifulSoup
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("来了来了")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页滴源码
return html #获取成功后返回
else:
print("获取网站信息失败!")
if __name__ == '__main__':
#关键字,可以直接更改,不用再去重新复制新的网址
keyword = '书包'
# 搜索地址,官网地址加keyword
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
html = get_html(search_url)
# 初始化BeautifulSoup库,并设置lxml解析器
soup = BeautifulSoup(html, 'lxml')
# 找到所有的商品所在的li
goods_list = soup.find_all('li', class_='gl-item')
number=0
for li in goods_list: # 遍历父节点
# 商品名称
name = li.find(class_='p-name p-name-type-2').find('em').get_text()
# 价格
price = li.find(class_='p-price').find('i').get_text()
# 将商品信息放入数组中
number+=1
goods = [number,price,name]
print(goods)

(2)心得体会
淘宝属实比京东难爬,真的要加headers!,还有正则确实要学很多知识点,下面的就很明显
作业三
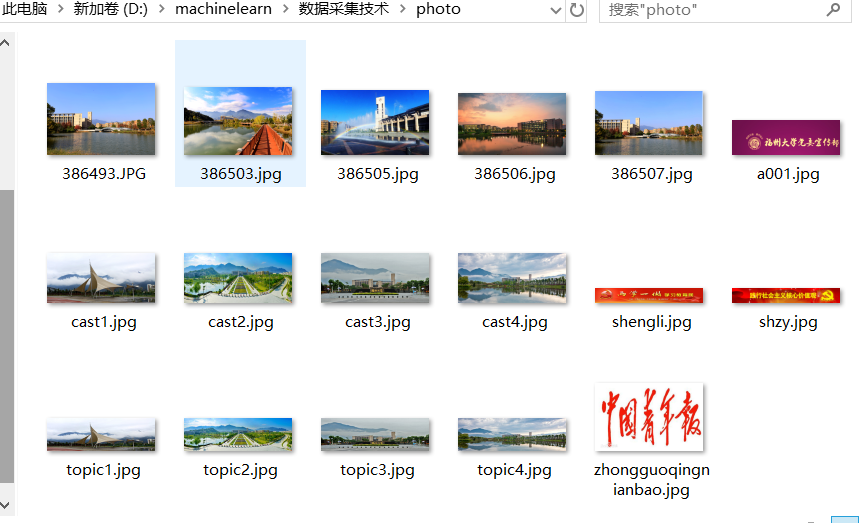
爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm031804114 time:2020/9/23
import urllib.request
import os
import re
targetPath = "D:machinelearn数据采集技术photo"
def saveFile(path):
# 设置每个图片的路径
pos = path.rindex('/') #rindex() 返回子字符串 str 在字符串中最后出现的位置
ans = os.path.join(targetPath,path[pos+1:])
return ans
url = "http://xcb.fzu.edu.cn/"
#请求
req = urllib.request.Request(url)
#爬取的结果
res = urllib.request.urlopen(req)
#显示结果
data = str(res.read())
urla = "http://xcb.fzu.edu.cn/"
pattern = r'([w./]+.(jpg|JPG))'#只取JPG格式的照片
imgurl = re.findall(pattern, data)
for link,value in imgurl:
url = urla+str(link)
print(url) #打印图片链接
try:
urllib.request.urlretrieve(url,saveFile(url))#urlretrieve() 方法直接将远程数据下载到本地
except:
print("爬取失败")
(2)心得体会
此处接上面就是正则进行筛选就很优秀,需要多百度正则使用方法,os的用法也有点多,又收藏夹里堆着了