目录
作业①
(1):指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
单线程爬取
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/14
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err: print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
# 提取文件后缀扩展名
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)

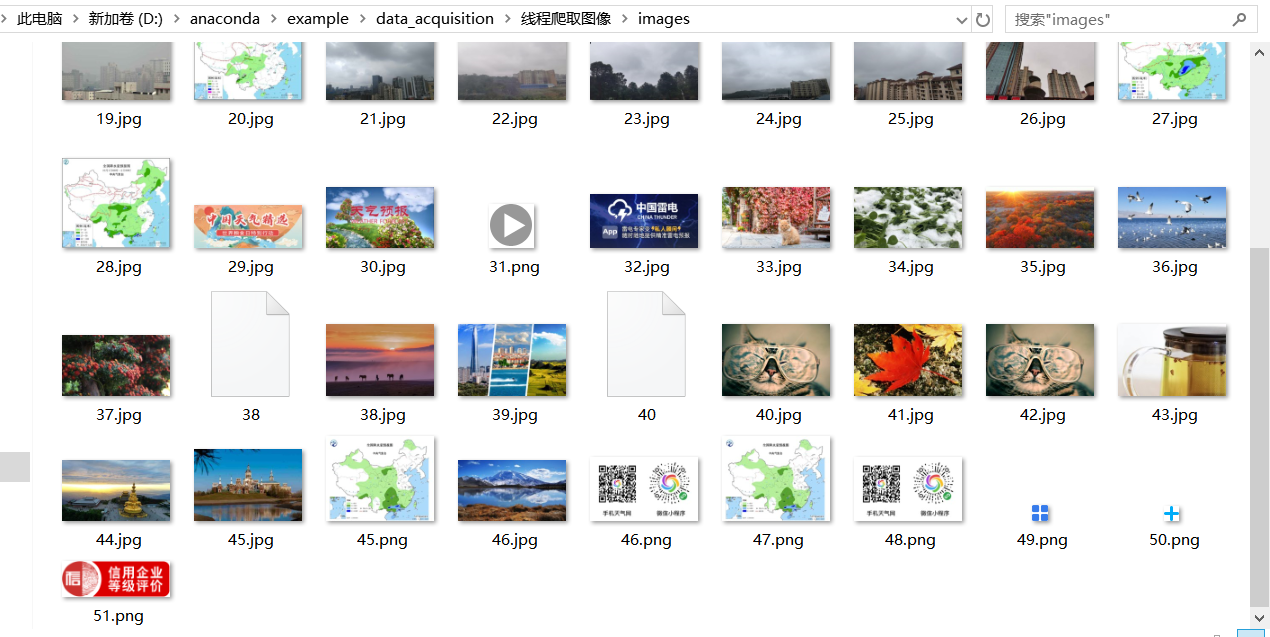
多线程爬取
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/15
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import time
def imageSpider(start_url):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url, count):
try:
if (url[len(url)-4] == "."):
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
print("More Threads Craw JPG Images")
start_url = "http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 0
threads = []
time_start = time.time()
imageSpider(start_url)
for t in threads:
t.join()
print("the End")
time_end = time.time()
time_using = time_end - time_start
print("More Threads Craw JPG Images Time Using:", time_using, 's')

(2):心得体会
尝试着实践了多线程的代码,中间也出现一些小问题,函数和参数的使用,thread.Thread的使用也查了一下,过程相对顺利
作业②
(1):使用scrapy框架复现作业①
思路流程:
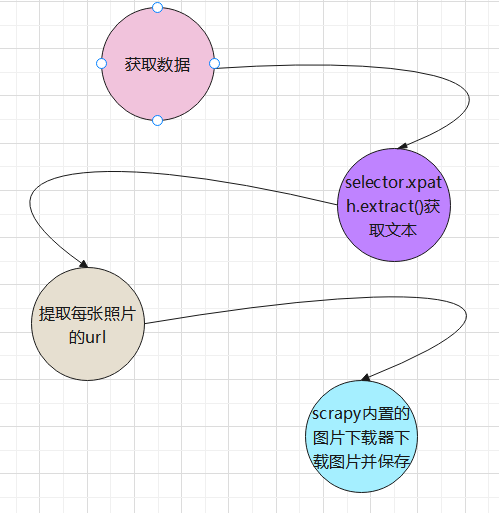
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/16
import scrapy
from ..items import WeatherPhotoItem
from scrapy.selector import Selector
class Spider_weatherphoto(scrapy.Spider):
name = "spiderweatherphoto"#给定爬虫的名字
start_urls=["http://www.weather.com.cn/"]
#执行爬虫的方法
def parse(self, response):
try:
data = response.body.decode()
selector = Selector(text=data)
s=selector.xpath("//img/@src").extract()#获得src元素的Selector对象对应的src元素的文本组成的列表,extract()获取属性值
for e in s:#循环提取
item=WeatherPhotoItem()
item["photo"] = [e]#photo要提取的数据项目,在items.py中
yield item#返回一个值等待被取走
except Exception as err:
print(err)
# print(response.url)
# item = WeatherPhotoItem()
# data = response.body.decode()
# print(data)
# selector=Selector(text=data)
# s=selector.xpath("//img/@src")
#
# print(s)
# print(s.extract())
# for e in s:
# print(e.extract())
# lis = response.xpath("//div/a/img")
# # print(lis)
# for li in lis:
# src = li.xpath("@src")
# print(src)
# item["image"] = response
# data=response.body.decode()
# print(data)
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WeatherPhotoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
photo = scrapy.Field()#要提取photo
# pass
ITEM_PIPELINES = {
#'weather_photo.pipelines.WeatherPhotoPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1#然后我们在添加这行代码就可以使用他scrapy内置的图片下载器
}
IMAGES_STORE=r'D:anacondaexampledata_acquisitiondown_images'
IMAGES_URLS_FIELD='photo'
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/16
from scrapy import cmdline
cmdline.execute("scrapy crawl spiderweatherphoto -s LOG_ENABLED=False".split())

(2):心得体会
初次使用scrapy框架确实有些不好弄,不过xpath确实很好用,全文档搜索标签很方便,可以在settings里面用scrapy
内置的图片下载器,不用自己在编一个download有点方便,items里面写入自己想要获取的数据名称
作业③
(1):使用scrapy框架爬取股票相关信息。
东方财富网:https://www.eastmoney.com/ 新浪股票:http://finance.sina.com.cn/stock/
思路流程:

#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/17
import scrapy
import json
import re
from ..items import GupiaodataItem
class spider_gupiao(scrapy.Spider):
name = "spidergupiao"
# for j in range(1,10):
start_urls=["http://75.push2.eastmoney.com/api/qt/clist/get?&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602901412583%20Request%20Method:%20GET"]
def parse(self, response):
try:
sites = json.loads(response.body_as_unicode())
data = sites["data"]
diff = data["diff"]
# pat =re.compile("[{.*?}]")
# data3 = pat.
# print(sites)
for i in range(len(diff)):
item=GupiaodataItem()
item["mount"]=str(i)
item["code"]=str(diff[i]["f12"])
item["name"]=str(diff[i]["f14"])
item["lately"]=str(diff[i]["f2"])
item["zhangdiefu"]=str(diff[i]["f3"])
item["zhangdiee"]=str(diff[i]["f4"])
item["chengjiaoliang"]=str(diff[i]["f5"])
item["chengjiaoe"]=str(diff[i]["f6"])
item["zhenfu"]=str(diff[i]["f7"])
item["zuigao"]=str(diff[i]["f15"])
item["zuidi"]=str(diff[i]["f16"])
item["jinkai"]=str(diff[i]["f17"])
item["zuoshou"]=str(diff[i]["f18"])
yield item
except Exception as err:
print(err)
# song_item=response.meta["item"]
# js = json.loads(response.text)["data"]
# song_item["data"] = data
# print(data)
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GupiaodataItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
mount = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
lately = scrapy.Field()
zhangdiefu = scrapy.Field()
zhangdiee = scrapy.Field()
chengjiaoliang = scrapy.Field()
chengjiaoe = scrapy.Field()
zhenfu = scrapy.Field()
zuigao = scrapy.Field()
zuidi = scrapy.Field()
jinkai = scrapy.Field()
zuoshou = scrapy.Field()
# pass
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class GupiaodataPipeline:
count = 0
def process_item(self, item, spider):
GupiaodataPipeline.count+=1
#控制输出格式对齐
tplt = "{0:^2} {1:^1} {2:{13}^4} {3:^5} {4:^6} {5:^6} {6:^6} {7:^10} {8:^10} {9:^10} {10:^10} {11:^10} {12:^10}"
try:
if GupiaodataPipeline.count==1:#count==1时,即第一次调用时新建一个txt文件,然后把item数据写到文件中
fobj=open("data.txt","wt")#写入data.txt中
fobj.write("序号" + " 股票代码" + " 股票名称 " + " 最新报价 " + " 涨跌幅 " + " 涨跌额 " +
" 成交量 " + " 成交额 " + " 振幅 " + " 最高 " + " 最低 " + " 今开 "+ " 昨收 " + "
")
else:#如果不是第一次调用count>1就打开已经存在的文件,把item的数据追加到文件中
fobj=open("data.txt","at")
# fobj.write("序号"+" 股票代码 "+" 股票名称 "+" 最新报价 "+"涨跌幅"+"涨跌额"+
# "成交量"+"成交额"+"振幅"+"最高"+"最低"+"今开"+"昨收"+"
")
fobj.write(
tplt.format(item["mount"], item["code"], item["name"], item['lately'], item['zhangdiefu'],
item['zhangdiee'], item['chengjiaoliang'],item['chengjiaoe'],item['zhenfu'],
item['zuigao'],item['zuidi'],item['jinkai'],item['zuoshou'],chr(12288)))
fobj.write("
")
fobj.close()
except Exception as err:
print(err)
return item
ITEM_PIPELINES = {
'gupiaodata.pipelines.GupiaodataPipeline': 300,
}
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/17
from scrapy import cmdline
cmdline.execute("scrapy crawl spidergupiao -s LOG_ENABLED=False".split())
部分截图:

(2):心得体会
和实验二的大体相似,但是因为获取的是json格式的数据,没办法使用xpath,换了json.loads(),用js[i]["f12"]获取数据值,
字典形式的也很好。接着就是存储的时候的格式问题,如果直接拼接,就要str(),但是很难对齐,所以还是用format,中文用
chr(12288),用管道类的进行数据的写入存储,过程稍有困难