-·

请求方法:


名词:
HTML:
 长沙市:
长沙市:
CSS:

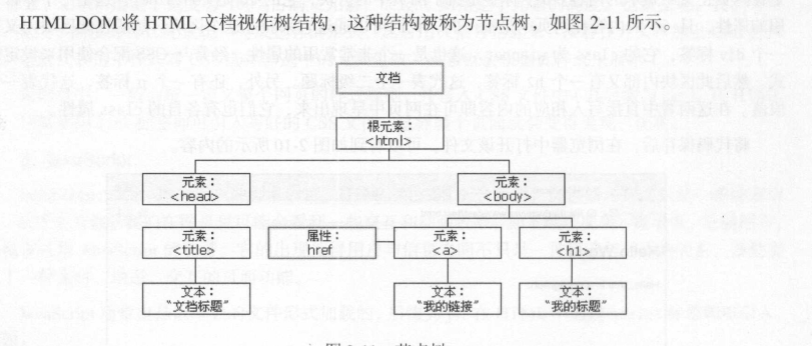
DOM:
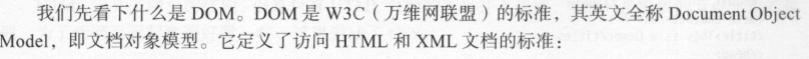
JSON:
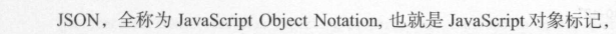
AJAX:

爬虫方法:
1:获取网页
2:提取信息
3:保存数据
静态网页:

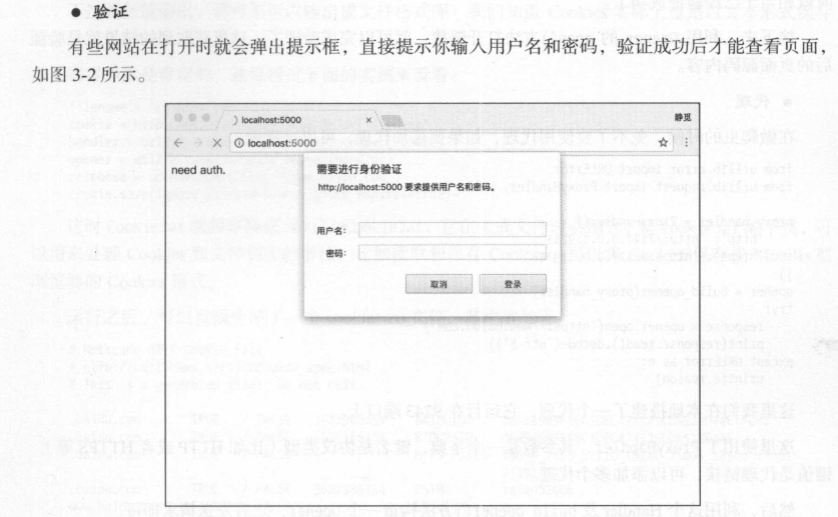
登陆时框,爬虫登陆代码:


文件上传:

其中favicon.ioc相当于一个文件:
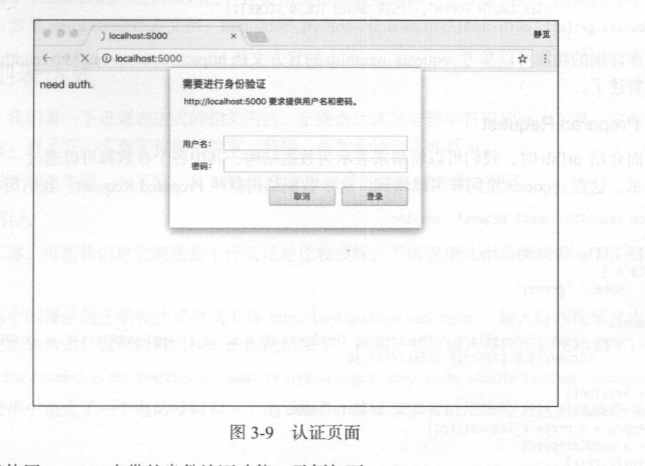
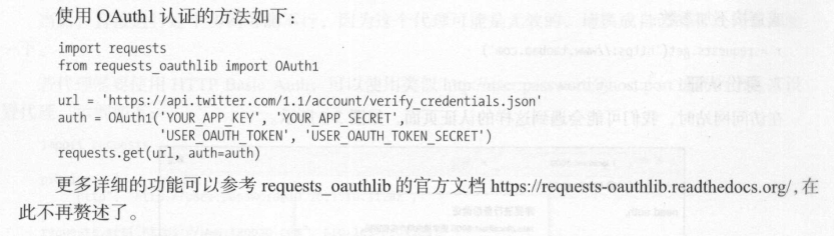
登陆认证:

seach()——在匹配时扫描字符串,然后返回第一个成功匹配的结果
match()——从字符串的头部开始匹配,一旦开头不匹配则匹配失败返回none
findall()——匹配正则表达式的所有内容。
sub()——去掉不想要的内容
compile()——将正则表达式编译成正则表达式对象,以后在后面的匹配中复用





beautiful soup4







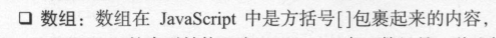
读取JSON:

关于ensure_ascii = False:
CSV文件的写入行:


数据库MySQL操作:
1创建表:CREATE
2:插入数据:INSERT
3:更新数据:UPDATE
4:-删除数据:DELETE
5:查询数据:SELECT

数据库MongoDB操作:
连接mongoDB:

指定数据库:

指定集合:

插入数据:

查询数据:

关于selenium:
单节点:

多节点:


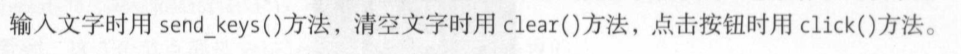
关于动态链:
对于鼠标拖拽,键盘按键等这些动作得使用动态链来实现
关于下拉进度条:
execute_script()可以将进度条下拉到最底部
获取源代码:
page_source
获取文本值:
webElement——text
beautifulSoup——get_text()
pyquery——text()
获取属性:
get_attribute()——获取节点属性
获取id,位置,标签名和大小:

切换Frame(相当于子页面)

延时等待:
隐式等待: implicitly——wait()
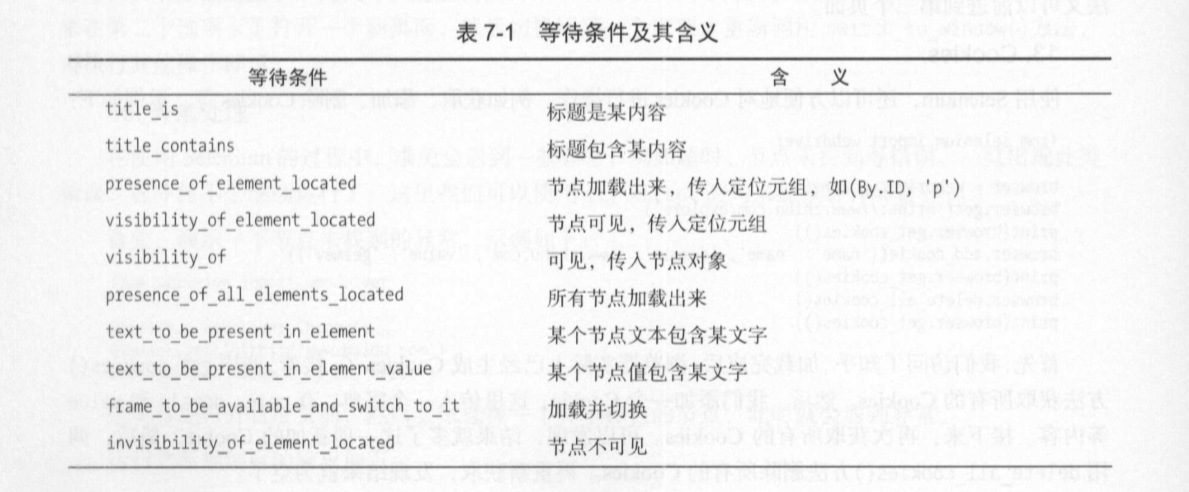
显式等待: