一、fsimage,edits和datanode的block在本地文件系统中位置的配置
fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:///opt/software/hadoop/data/nn/image
edits:hdfs-site.xml中的dfs.namenode.edits.dir
datanode block:hdfs-site.xml中的dfs.datanode.data.dir
secondarynanode的fsimage:hdfs-site.xml中的dfs.namenode.checkpoint.dir
secondarynanode的edits:hdfs-site.xml中的dfs.namenode.checkpoint.edits.dir
一个配置项需要多个文件路径时,用英文的逗号隔开。
修改了fsimage和edits后,需要格式化namenode,或者把旧目录中的文件拷贝过来。否则会因为元数据文件缺失,导致集群无法正常启动。
二、MapReduce程序相关日志路径的配置
MapReduce程序相关日志分为历史作业日志和Container日志。
历史作业日志包括一个作业用了多少个Map,用了多少个Reduce,作业提交时间,作业启动时间,作业完成时间等。
Container日志包括ApplicationMaster日志和普通Task的日志等。
相关的配置在mapred-site.xml中,如下
历史作业日志,默认为HDFS路径,mapreduce.jobhistory.done-dir和mapreduce.jobhistory.intermediate-done-dir,默认为hdfs的tmp目录下
App Master运行的数据目录,yarn.app.mapreduce.am.staging-dir,client将application定义以及需要的jar包文件等上传到hdfs的指定目录,默认为hdfs的tmp目录下
Container日志目录路径,yarn.nodemanager.log-dirs,默认为本地目录${HADOOP_HOME}/logs/userlogs
三、复制或者克隆方式新建虚拟机,建立Hadoop集群
NameNode和DataNode可以位于一个机器上,ResourceManager和NodeManager也可以位于一个机器上。
可以先做好机器规划,主机名,IP,上面所运行的服务等,在一个机器上做好配置,其他的机器以复制或者克隆的方式来直接创建,然后修改mac,IP,主机名等,配置主节点到各从节点的SSH免密码登录。
复制虚拟机文件夹方式可以创建新的虚拟机,创建好后,查看ifconfig中的mac地址,修改ifcfg-eth0的mac配置。修改IP,hostname。
克隆方式创建新的虚拟机时,需要在虚拟机属性中重新生成新的mac地址,修改etc/udev/rules.d/70-persistent-net.rules中,注释掉eth0的行,将eth1改为eth0,并修改mac地址,然后修改ifcfg-eth0的mac配置。修改IP,hostname。
以非root的普通用户启动Hadoop时,需要集群中拥有相同的用户名和密码,并且该用户要有无密码sudo权限。
四、复制方式建立集群时的一些事项
DataNode和NodeManager的配置都在slave.xml中。
可以以tar包形式复制,也可以以scp直接复制scp -rp /opt/software/hadoop/* cyhp@hadoop-nn.cloudy.com:/opt/software/hadoop。cyhp为共同的用户名。
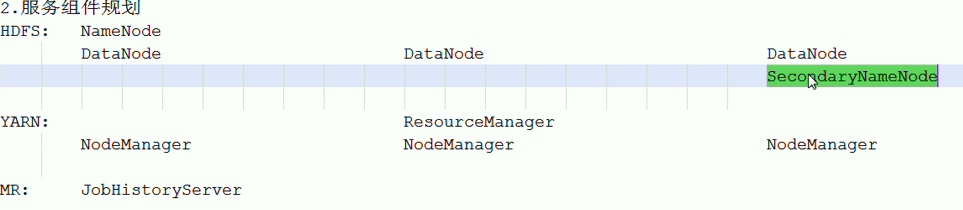
在node1,node2,node3上建立如下的集群时,需要依次启动各组件:
在node1,node2,node3上依次启动NameNode,DataNode,SecondaryNameNode,ResourceManager,NodeManager,JobHistoryServer。
HDFS的监控在Namenode节点的50070端口,YARN的监控在ResourceManager节点的8088端口。JobHistoryServer默认端口为19888.
五、Hadoop基准测试
集群环境安装好了之后,还需要对环境做基准测试,测试dfs的读写速度,网卡的读写速度,mr压力测试等。
查看测试程序的帮助信息:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar
测试写速度:向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO/io_data中
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
查看写入结果cat TestDFSIO_results.log
测试读速度:在HDFS文件系统中读入10个文件,每个文件10M
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
查看结果cat TestDFSIO_results.log
删除临时文件:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar TestDFSIO -clean
六、无密钥SSH登录的配置
使用start-dfs.sh启动dfs时,需要配置namenode节点到其他datanode节点的无密钥登录。
使用start-yarn.sh启动yarn时,需要配置resourcemanager节点到其他nodemanager节点的无密钥登录。
先使用kengen生成公钥和秘钥后,使用scp拷贝到其他机器,也可以简单地使用ssh-copy-id otherhostname的方式。
本地即是namenode又是datanode时,也需要拷贝公钥到本机。
使用hadoop-demons.sh stop datanode可以依次停止多个节点上的datanode进程。