什么是Pandas?
Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了 高级数据结构 和 数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
-
一个强大的分析和操作大型结构化数据集所需的工具集
-
基础是NumPy,提供了高性能矩阵的运算
-
提供了大量能够快速便捷地处理数据的函数和方法
-
应用于数据挖掘,数据分析
-
提供数据清洗功能
Pandas的数据结构
import pandas as pd
Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame
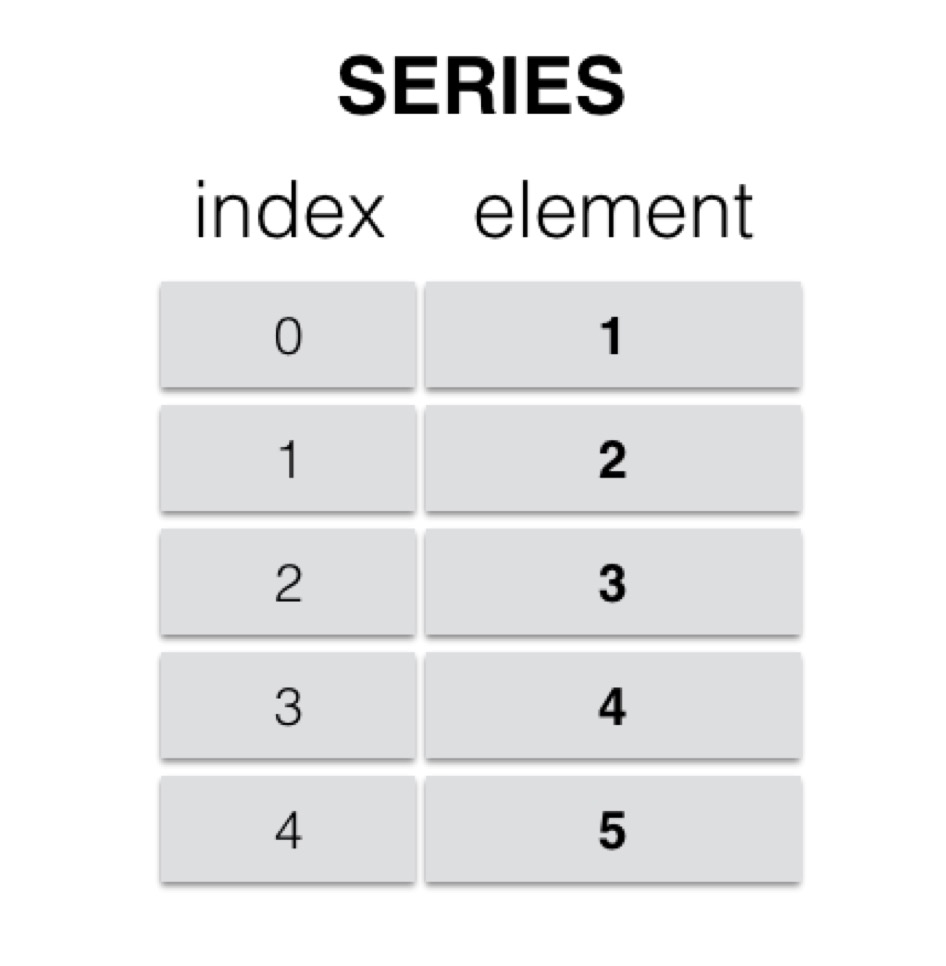
Series
Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成。
- 类似一维数组的对象
- 由数据和索引组成
- 索引(index)在左,数据(values)在右
- 索引是自动创建的
1. 通过list构建Series
ser_obj = pd.Series(range(10))
# 通过list构建Series
import pandas as pd
ser_obj = pd.Series(range(10, 20))
print(ser_obj.head(3))
print(ser_obj)
print(type(ser_obj))
效果:
0 10
1 11
2 12
dtype: int64
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
<class 'pandas.core.series.Series'>
2. 获取数据和索引
ser_obj.index 和 ser_obj.values
# 通过list构建Series
import pandas as pd
ser_obj = pd.Series(range(10, 20))
# 获取数据
print(ser_obj.values)
# 获取索引
print(ser_obj.index)
效果:
[10 11 12 13 14 15 16 17 18 19]
RangeIndex(start=0, stop=10, step=1)
3. 通过索引获取数据
ser_obj[idx]
# 通过list构建Series
import pandas as pd
ser_obj = pd.Series(range(10, 20))
#通过索引获取数据
print(ser_obj[0])
print(ser_obj[8])
效果:
10
18
4. 索引与数据的对应关系不被运算结果影响
# 通过list构建Series
import pandas as pd
ser_obj = pd.Series(range(10, 20))
# 索引与数据的对应关系不被运算结果影响
print(ser_obj * 2)
print(ser_obj > 15)
效果:
0 20
1 22
2 24
3 26
4 28
5 30
6 32
7 34
8 36
9 38
dtype: int64
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 True
8 True
9 True
dtype: bool
5. 通过dict构建Series
# 通过list构建Series
import pandas as pd
# 通过dict构建Series
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj2 = pd.Series(year_data)
print(ser_obj2.head())
print(ser_obj2.index)
效果:
2001 17.8
2002 20.1
2003 16.5
dtype: float64
Int64Index([2001, 2002, 2003], dtype='int64')
name属性
对象名:ser_obj.name
对象索引名:ser_obj.index.name
# 通过list构建Series
import pandas as pd
# 通过dict构建Series
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj2 = pd.Series(year_data)
# name属性
ser_obj2.name = 'temp'
ser_obj2.index.name = 'year'
print(ser_obj2.head())
效果:
year
2001 17.8
2002 20.1
2003 16.5
Name: temp, dtype: float64
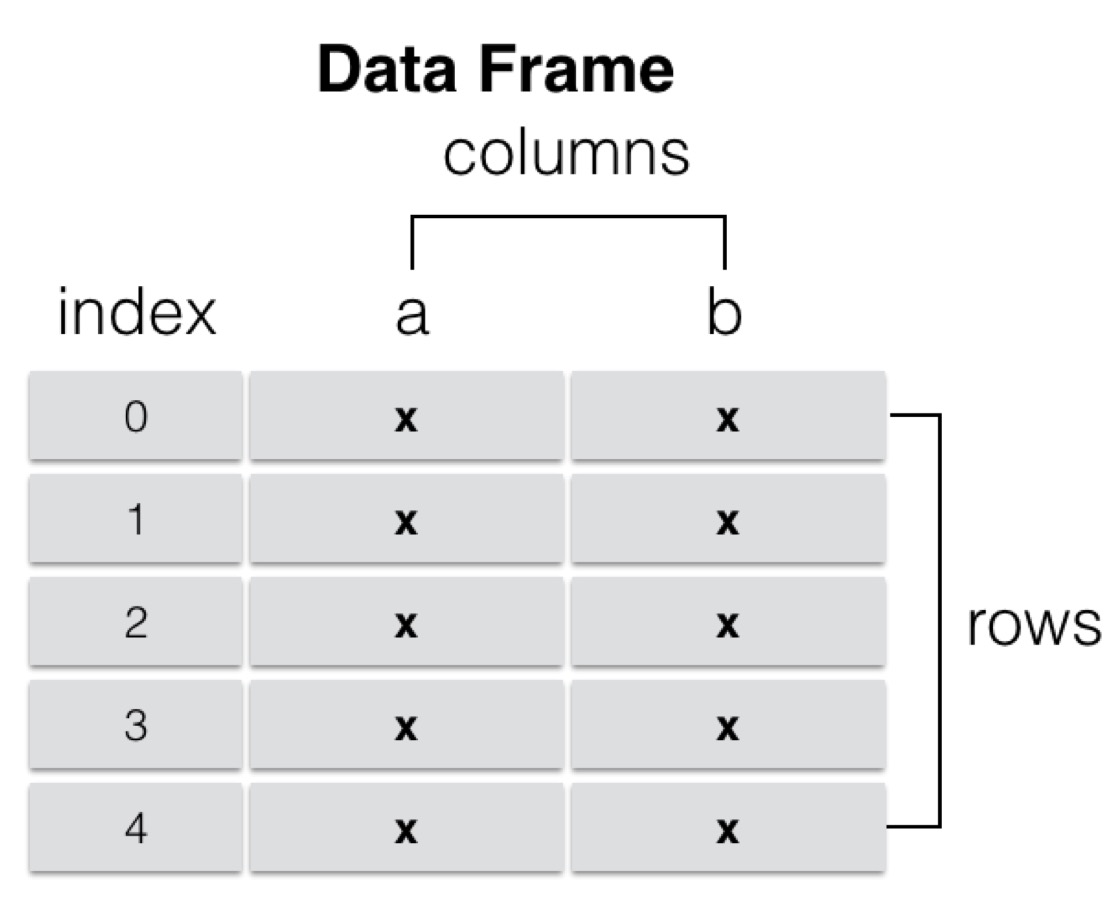
DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
- 类似多维数组/表格数据 (如,excel, R中的data.frame)
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
1. 通过ndarray构建DataFrame
import numpy as np
# 通过ndarray构建DataFrame
import pandas as pd
array = np.random.randn(5,4)
print(array)
print("----------")
df_obj = pd.DataFrame(array)
print(df_obj.head())
效果:
[[ 0.44137761 0.13408736 -1.59408949 -0.1010183 ]
[-0.31168161 0.24322197 -0.1602419 -1.42392738]
[ 1.57426004 0.31490818 -0.22182099 -0.67538973]
[ 0.22735072 0.02080081 -0.74327977 0.89156492]
[-0.15163684 -0.72034151 0.07189318 0.8673076 ]]
----------
0 1 2 3
0 0.441378 0.134087 -1.594089 -0.101018
1 -0.311682 0.243222 -0.160242 -1.423927
2 1.574260 0.314908 -0.221821 -0.675390
3 0.227351 0.020801 -0.743280 0.891565
4 -0.151637 -0.720342 0.071893 0.867308
2. 通过dict构建DataFrame
import numpy as np
# 通过ndarray构建DataFrame
import pandas as pd
# 通过dict构建DataFrame
dict_data = {'A': 1,
'B': pd.Timestamp('20191210'),
'C': pd.Series(1, index=list(range(4)),dtype='float32'),
'D': np.array([3] * 4,dtype='int32'),
'E': ["Python","Java","Android++","C"],
'F': 'loaderman' }
#print dict_data
df_obj2 = pd.DataFrame(dict_data)
print(df_obj2)
效果:
A B C D E F
0 1 2019-12-10 1.0 3 Python loaderman
1 1 2019-12-10 1.0 3 Java loaderman
2 1 2019-12-10 1.0 3 Android++ loaderman
3 1 2019-12-10 1.0 3 C loaderman
3. 通过列索引获取列数据(Series类型)
df_obj[col_idx] 或 df_obj.col_idx
import numpy as np
# 通过ndarray构建DataFrame
import pandas as pd
# 通过dict构建DataFrame
dict_data = {'A': 1,
'B': pd.Timestamp('20191210'),
'C': pd.Series(1, index=list(range(4)),dtype='float32'),
'D': np.array([3] * 4,dtype='int32'),
'E': ["Python","Java","Android++","C"],
'F': 'loaderman' }
#print dict_data
df_obj2 = pd.DataFrame(dict_data)
print(df_obj2)
# 通过列索引获取列数据
print(df_obj2['A'])
print(type(df_obj2['A']))
print(df_obj2.A)
效果:
A B C D E F
0 1 2019-12-10 1.0 3 Python loaderman
1 1 2019-12-10 1.0 3 Java loaderman
2 1 2019-12-10 1.0 3 Android++ loaderman
3 1 2019-12-10 1.0 3 C loaderman
0 1
1 1
2 1
3 1
Name: A, dtype: int64
<class 'pandas.core.series.Series'>
0 1
1 1
2 1
3 1
Name: A, dtype: int64
4. 增加列数据
df_obj[new_col_idx] = data
类似Python的 dict添加key-value
import numpy as np
# 通过ndarray构建DataFrame
import pandas as pd
# 通过dict构建DataFrame
dict_data = {'A': 1,
'B': pd.Timestamp('20191210'),
'C': pd.Series(1, index=list(range(4)),dtype='float32'),
'D': np.array([3] * 4,dtype='int32'),
'E': ["Python","Java","Android++","C"],
'F': 'loaderman' }
df_obj2 = pd.DataFrame(dict_data)
# 增加列
df_obj2['G'] = df_obj2['D'] + 4
print(df_obj2.head())
效果:
A B C D E F G
0 1 2019-12-10 1.0 3 Python loaderman 7
1 1 2019-12-10 1.0 3 Java loaderman 7
2 1 2019-12-10 1.0 3 Android++ loaderman 7
3 1 2019-12-10 1.0 3 C loaderman 7
5. 删除列
del df_obj[col_idx]
import numpy as np
# 通过ndarray构建DataFrame
import pandas as pd
# 通过dict构建DataFrame
dict_data = {'A': 1,
'B': pd.Timestamp('20191210'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': ["Python", "Java", "Android++", "C"],
'F': 'loaderman'}
df_obj2 = pd.DataFrame(dict_data)
# 增加列
df_obj2['G'] = df_obj2['D'] + 4
print(df_obj2.head())
# 删除列
del (df_obj2['G'])
print(df_obj2.head())
效果:
A B C D E F G
0 1 2019-12-10 1.0 3 Python loaderman 7
1 1 2019-12-10 1.0 3 Java loaderman 7
2 1 2019-12-10 1.0 3 Android++ loaderman 7
3 1 2019-12-10 1.0 3 C loaderman 7
A B C D E F
0 1 2019-12-10 1.0 3 Python loaderman
1 1 2019-12-10 1.0 3 Java loaderman
2 1 2019-12-10 1.0 3 Android++ loaderman
3 1 2019-12-10 1.0 3 C loaderman
Pandas的索引操作
索引对象Index
1. Series和DataFrame中的索引都是Index对象
import numpy as np
# 通过ndarray构建DataFrame
import pandas as pd
# 通过dict构建DataFrame
dict_data = {'A': 1,
'B': pd.Timestamp('20191210'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': ["Python", "Java", "Android++", "C"],
'F': 'loaderman'}
df_obj2 = pd.DataFrame(dict_data)
# 通过dict构建Series
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5}
ser_obj = pd.Series(year_data)
print(type(ser_obj.index))
print(type(df_obj2.index))
print(df_obj2.index)
效果:
<class 'pandas.core.indexes.numeric.Int64Index'>
<class 'pandas.core.indexes.numeric.Int64Index'>
Int64Index([0, 1, 2, 3], dtype='int64')
2. 索引对象不可变,保证了数据的安全
# 索引对象不可变
df_obj2.index[0] = 2
效果:
raise TypeError("Index does not support mutable operations")
TypeError: Index does not support mutable operations
常见的Index种类
- Index,索引
- Int64Index,整数索引
- MultiIndex,层级索引
- DatetimeIndex,时间戳类型
Series索引
1. index 指定行索引名
import pandas as pd
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
print(ser_obj.head())
效果:
a 0
b 1
c 2
d 3
e 4
dtype: int64
2. 行索引
ser_obj[‘label’], ser_obj[pos]
import pandas as pd
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
# 行索引
print(ser_obj['b'])
print(ser_obj[2])
效果
1
2
3. 切片索引
ser_obj[2:4], ser_obj[‘label1’: ’label3’]
注意,按索引名切片操作时,是包含终止索引的。
import pandas as pd
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
# 切片索引
print(ser_obj[1:3])
print(ser_obj['b':'d'])
效果:
b 1
c 2
dtype: int64
b 1
c 2
d 3
dtype: int64
4. 不连续索引
ser_obj[[‘label1’, ’label2’, ‘label3’]]
import pandas as pd
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
# 不连续索引
print(ser_obj[[0, 2, 4]])
print(ser_obj[['a', 'e']])
效果:
a 0
c 2
e 4
dtype: int64
a 0
e 4
dtype: int64
5. 布尔索引
import pandas as pd
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
# 布尔索引
ser_bool = ser_obj > 2
print(ser_bool)
print(ser_obj[ser_bool])
print(ser_obj[ser_obj > 2])
效果
a False
b False
c False
d True
e True
dtype: bool
d 3
e 4
dtype: int64
d 3
e 4
dtype: int64
DataFrame索引
1. columns 指定列索引名
import pandas as pd
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj.head())
效果
a b c d
0 0.768207 -0.828292 0.050348 -0.737844
1 -1.532876 0.261017 1.191702 0.661960
2 0.736359 1.902244 -0.475106 0.554105
3 0.096775 0.487364 -0.875836 -1.011496
4 -1.723229 0.483649 -0.139809 1.968255
2. 列索引
df_obj[[‘label’]]
import pandas as pd
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5, 4), columns=['a', 'b', 'c', 'd'])
# 列索引
print(df_obj['a']) # 返回Series类型
print(df_obj[['a']]) # 返回DataFrame类型
print(type(df_obj[['a']])) # 返回DataFrame类型
效果
0 1.060989
1 -1.693514
2 -0.315455
3 0.679558
4 1.108019
Name: a, dtype: float64
a
0 1.060989
1 -1.693514
2 -0.315455
3 0.679558
4 1.108019
<class 'pandas.core.frame.DataFrame'>
3. 不连续索引
df_obj[[‘label1’, ‘label2’]]
import pandas as pd
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5, 4), columns=['a', 'b', 'c', 'd'])
# 不连续索引
print(df_obj[['a','c']])
效果:
a c
0 -0.059479 -0.639038
1 1.222235 -0.508763
2 -1.030170 1.424272
3 0.116193 1.714186
4 0.900865 1.545013
高级索引:标签、位置和混合
Pandas的高级索引有3种
1. loc 标签索引
DataFrame 不能直接切片,可以通过loc来做切片
loc是基于标签名的索引,也就是我们自定义的索引名
import pandas as pd
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5, 4), columns=['a', 'b', 'c', 'd'])
# 通过list构建Series
ser_data = {"a": 17.8, "b": 20.1, "c": 16.5,"d":12}
ser_obj = pd.Series(ser_data)
# 标签索引 loc
# Series
print(ser_obj['b':'d'])
print(ser_obj.loc['b':'d'])
# DataFrame
print(df_obj['a'])
# 第一个参数索引行,第二个参数是列
print(df_obj.loc[0:2, 'a'])
效果:
b 20.1
c 16.5
d 12.0
dtype: float64
b 20.1
c 16.5
d 12.0
dtype: float64
0 1.110840
1 -0.629939
2 0.012856
3 2.038906
4 -2.497636
Name: a, dtype: float64
0 1.110840
1 -0.629939
2 0.012856
Name: a, dtype: float64
2. iloc 位置索引
作用和loc一样,不过是基于索引编号来索引
import pandas as pd
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5, 4), columns=['a', 'b', 'c', 'd'])
# 通过list构建Series
ser_data = {"a": 17.8, "b": 20.1, "c": 16.5,"d":12}
ser_obj = pd.Series(ser_data)
# 整型位置索引 iloc
# Series
print(ser_obj[1:3])
print(ser_obj.iloc[1:3])
# DataFrame
print(df_obj.iloc[0:2, 0]) # 注意和df_obj.loc[0:2, 'a']的区别
效果:
b 20.1
c 16.5
dtype: float64
b 20.1
c 16.5
dtype: float64
0 -1.554571
1 -0.307958
Name: a, dtype: float64
3. ix 标签与位置混合索引
ix是以上二者的综合,既可以使用索引编号,又可以使用自定义索引,要视情况不同来使用,
如果索引既有数字又有英文,那么这种方式是不建议使用的,容易导致定位的混乱。
目前显示已过时不再推荐使用!
注意
DataFrame索引操作,可将其看作ndarray的索引操作
标签的切片索引是包含末尾位置的