作业:
1. 支持向量机(Support Vector Machines)
在这节,我们将使用支持向量机来处理二维数据。通过实验将会帮助我们获得一个直观感受SVM是怎样工作的。以及如何使用高斯核(Gaussian kernel )。下一节我们将使用SVM建立一个垃圾邮件分类器。
1.1 样本数据1
以二维线性可分数据开始。下面代码部分将会可视化此数据集如图1所示。在这个数据集中,正样本使签为1使用+表示,负样本标签为0使用o表示,由一条间隙隔开。注意有一个异常正样本,在(0.1,4.1)的位置。在这部分练习我们会看到这个异常正样本是如何影响SVM分类器的。
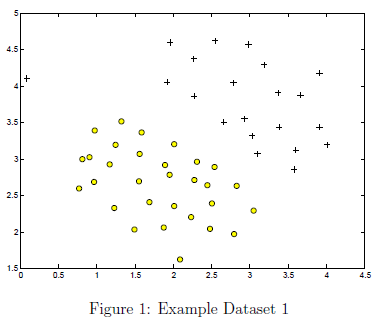
在这一部分,我们将尝试使用SVM的C参数的不同值。具体来说,C参数是一个正值,可以控制对错误分类点的惩罚力度。C越大惩罚力度越小。一个很大的C告诉SVM尝试将所有的样本点分类正确。C跟1/λ非常类似
,λ是之前逻辑回归的正则化参数。下面代码将会使用svmTrain.m中的入门代码,通过SVM包执行SVM训练。
大多数的SVM包都会自动添加额外的特征x0=1,
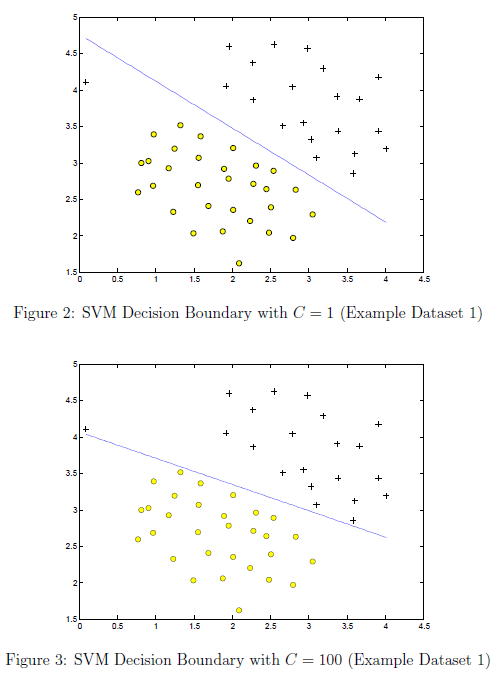
当C=100时我们可以发现,SVM将会把每一样本分类正确。但是这样一个决策边界有很差的泛化性。
1.2 应用高斯核的SVM
在这一部分练习,我们将使用SVM处理非线性可分问题。
1.2.1 高斯核
来寻找SVM的非线性的决策边界,我们首先需要实现高斯核,我们可以把高斯核作为一个相似函数函数,可以衡量两个样本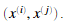 间的距离。高斯核函数同样被参数σ参数化。决定相似度减少的速度。
间的距离。高斯核函数同样被参数σ参数化。决定相似度减少的速度。
我们需要完成 gaussianKernel.m文件中的代码来完成两个样本的高斯核函数,高斯核函数的定义为:
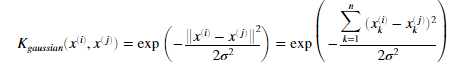
完成代码后,运行下面代码提供的两个样本,我们应该看到结果为 0.324652.
gaussianKernel.m代码
sim = exp(-(x1-x2)'*(x1-x2)/2/sigma^2);
1.2.2 样本数据2
下面部分代码将会加载数据并绘制数据集2,通过图4我们可以看到有一个非线性可分的决策边界将正负样本分开

如果我们正确完成高斯核函数,下面代码将会在这个数据集上执行带高斯核的SVM,结果如图5所示:

1.2.3 样本数据3
在这一部分,我们将获得更多技巧如何使用带高斯核的SVM,下面代码将会加载并可视化数据集3如图6所示

我们将使用带高斯核的SVM处理数据集,ex6data3.mat文件提供我们数据集,包括变量X, y, Xval, yval。作业在dataset3Params.m提供的代码将会帮我们选择SVM分类器的参数,C与σ。
我们的任务是使用交叉验证集,Xval,yval,决定最好的的参数C与σ。我们应该补充一些必要的代码来帮助我们选择最合适的C和σ。比如我们尝试每个参数遍历8个值,我们一共有84个组合。然后我们从这些组合中选出最合适的C和σ,我们应该完成dataset3Params.m中的代码,找到最佳参数。
当我们实现交叉验证集选择最好的参数C和σ,我们应该估计交叉验证集的错误率。在Matlab中我们可以使用mean(double(predictions ~= yval))来计算错误率。 其中predictions 时一个向量,包含所有使用SVM计算的预测值。yval是交叉验证集的正确的标签,我们可以使用svmPredict函数来产生交叉验证集的的预测值。
dataset3Params.m文件中的代码:
k = 1; for i = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30] for j = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30] model = svmTrain(X, y, i, @(x1, x2)gaussianKernel(x1, x2, j)); predictions = svmPredict(model, Xval); k1 = mean(double(predictions ~= yval)); if k>k1 C = i; sigma = j; k = k1; end end end
2.垃圾邮件分类
徐迪邮件服务商提供邮件过滤器,可以用来将邮件分成正常邮件和垃圾邮件,而且有很好的准确率。在这一节的练习中。我们将使用SVM来建立我们自己的垃圾邮件过滤其。我们将训练一个分类器来确定一个邮件x,
是正常邮件(y=1)还是一个垃圾邮件(y=0)。具体来说我们应该将一封邮件转化成特征向量。下面的部分的练习中将会引导我们如何将一封邮件转化成一个这样的特征向量。
2.1 处理邮件
一封邮件的格式如图8所示,包含URL,邮件地址,数字和美元金额。虽然很多邮件包含类似类型的内容,比如数字,URL和邮件地址等。但是这些具体内容对一封邮件几乎都不相同。

因而,经常采用的一种处理邮件的方法是标准化这些值,将所有的URL值,数字值,视为内容都是相同的。比如的邮件中所有的URL替换成独特的字符串“httpaddr“来表示URL是存在的。这让垃圾邮件分类器具有基于是否存在任何URL来做出分类决定。而不是一个特定的URL存在。这通常会提升垃圾邮件分类器的形成。因为垃圾邮件提供者通常会随机使用URL,因此在一封新的邮件中再次看到一个特定的URL的概率非常低。
在processEmail.m中,我们需要实现下面的邮件处理和规范化步骤。

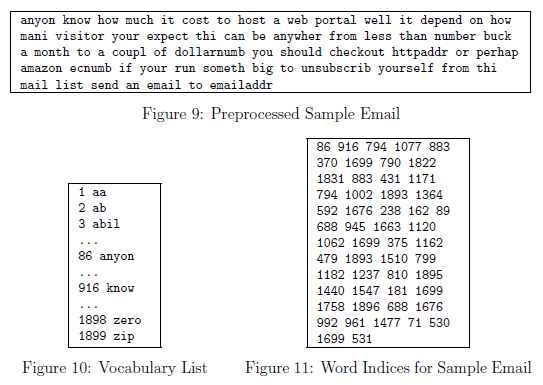
根据上面要求处理后的结果如图9所示,虽然预处理留下了单词和非单词,但是这种形式更容易进行特征提取。
2.11 词汇表
在处理了这些邮件后,我们为每一封邮件列出了一些列的单词。下一步是选择哪个单词在我们的分类器中可能被使用。在这节练习中我们选择使用最经常使用的单词作为我们考虑的单词集合(词汇表).因为一些单词出现在很少一部分邮件,这会造成我们训练集过拟合的情况。词汇表出现在vocab.txt 文件中,如图10所示。我们的词汇表的单词是至少在垃圾邮件中出现了100此的单词。结果是1899个单词。在实际情况中,一般使用10000到50000个单词。
给定词汇表,我先现在可以将处理后的邮件的单词映射成单词索引列表,内容为词汇表的单词的索引。图11展示了映射后的邮件。具体来说,一封简单的邮件,单词‘anyone'首先被被规范化成‘anyon’接着映射成词汇表的索引86.
我们的任务是完成processEmail.m的代码来完成映射。在代码中,我们给定一个字符str表示处理过邮件中的一个单独的单词。我们应该寻找这个单词是否在词汇表中存在,如果存在,我们应该将索引添加到单词索引变量中。如果不存在,跳过这个单词。
我们一旦实现了processEmail.m。下面的代码将会执行我们完成的代码,应该看到结果如图9与图11所示。
在MATLAB中我们可以使用strcmp函数比较两个单词是否相同。如果相同则会返回1。在提供的代码中vocabList是一个cell数组,在MATLAB中,cell数组就与正常数组在相同,除了元素可以是字符串外。使用花括号而不是方括号标注它们。具体来说,得到第i个单词,我们可以使用{i},我们同样可以使用length(vocabList)来得到词汇表单词的数量。
processEmail.m中添加代码
for i = 1:size(vocabList) if strcmp(str,vocabList{i}) word_indices(m) = i; m = m+1; end end
2.2 从邮件中提取特征
现在我们将实现特征提取,将每一封邮件转化为一个向量。在这部分练习中,我们将使用词汇表中的单词。具体来说,特征一封邮件的的特征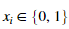 对应是否词汇表中第i个单词出现在这封邮件中。若果等于1表示出现,反之没有出现。
对应是否词汇表中第i个单词出现在这封邮件中。若果等于1表示出现,反之没有出现。
因此一封典型的邮件的特征像下面这样:
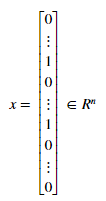
我们现在应该完成emailFeatures.m文件中的代码,来产生每一封邮件的特征向量。完成后执行下面代码,我们会看到特征向量长度为1899,有45个非0元素。
emailFeatures.m中的代码:
for i = 1:length(word_indices) x(word_indices(i)) = 1; end
2.3 使用SVM训练垃圾邮件分类器
在我们完成特征提取函数后,这一部分的代码将会加载处理后的训练集来训练SVM分类器。spamTrain.mat包括4000个垃圾邮件和正常邮件样本。 spamTest.mat 包括1000个测试时用例,每一封原始邮件都被 processEmail 和 emailFeatures 函数处理成一个特征向量。在加载数据集后,代码将训练SVM分类器。训练完成后,我们将看到分类器获得训练精度大约为99.8%。测试精度为98.5%。
% Load the Spam Email dataset % You will have X, y in your environment load('spamTrain.mat'); C = 0.1; model = svmTrain(X, y, C, @linearKernel); p = svmPredict(model, X); fprintf('Training Accuracy: %f ', mean(double(p == y)) * 100); % Load the test dataset % You will have Xtest, ytest in your environment load('spamTest.mat'); p = svmPredict(model, Xtest); fprintf('Test Accuracy: %f ', mean(double(p == ytest)) * 100);
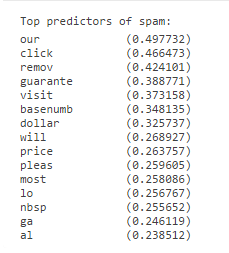
2.4 垃圾邮件的主要预测因子
为了更好理解垃圾邮件分类器是如何工作的,我们可以检查参数,看分类器认为哪个单词最可能是垃圾邮件。下面代码将会找到分类器中有最大正值的参数并显示相应的单词,如图12所示。因此如果一封邮件包含单词比如 'guarantee', 'remove', 'dollar'和 'price'等,它很可能被分类成垃圾邮件。
% Sort the weights and obtin the vocabulary list [weight, idx] = sort(model.w, 'descend'); vocabList = getVocabList(); for i = 1:15 if i == 1 fprintf('Top predictors of spam: '); end fprintf('%-15s (%f) ', vocabList{idx(i)}, weight(i)); end
结果:
2.5 使用自己的邮件
2.6 建立自己的数据集
这次练习作业为我们提供了,训练集与测试集。使用了processEmail.m 和 emailFeatures.m两个函数。现在我们可以使用 SpamAssassin Public Corpus.中的数据集来训练分类器。我们还可以建立自己词汇表(选择最长出现的单词),还可以使用高度优化的SVM工具比如LIBSVM或者 SVM functionality。
processEmail.m and emailFeatures.m