今天阅读了一下大型网络技术架构这本苏中的分布式缓存一致性hash算法这一节,针对大型分布式系统来说,缓存在该系统中必不可少,分布式集群环境中,会出现添加缓存节点的需求,这样需要保障缓存服务器中对缓存的命中率,就有很大的要求了:
采用普通方法,将key值进行取hash后对分布式缓存机器数目进行取余,以集群3台分布式缓存为例子:
对于数据进行取hash值然后对3其进行取余,余数为0则进入node 0,余数位1则进入node1,余数位2则进入node2.
如果增加一个节点则对4进行取余,则会将node0中的部分,node1中的部分,node2中的部分分割到node3中,则出现了命中率为75%
如果增加2个节点的话则对5进行取余,则只有3/5的机器被命中
普通方法的设计会导致当你的节点添加的数目越多,导致你的命中率越低导致对数据库的操作压力就越大
采用一致性Hash算法:
构造一个0~2^32的整数环,然后将节点的名称比如说node0对其进行取hash值将其分布在该店上,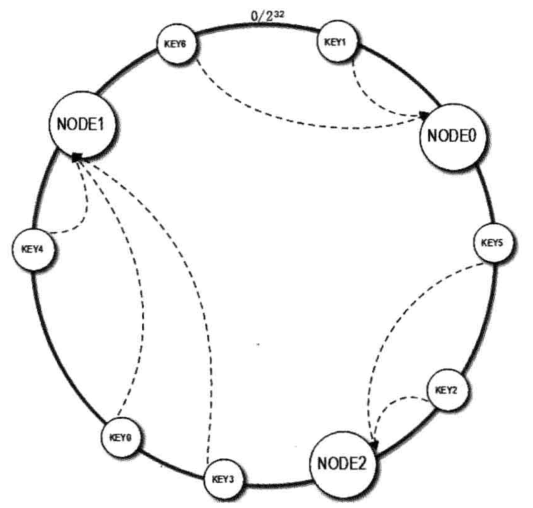
然后将key值取hash值后进行比较:
举例:node0的hash值为432323232;node1 hash值为879798098,则如果key1的hash值为559798098,则其大于node0的hashi值,则顺时针旋转,找到了node1则将其存放在node1中的缓存中。
扩容后,将三个变成4个
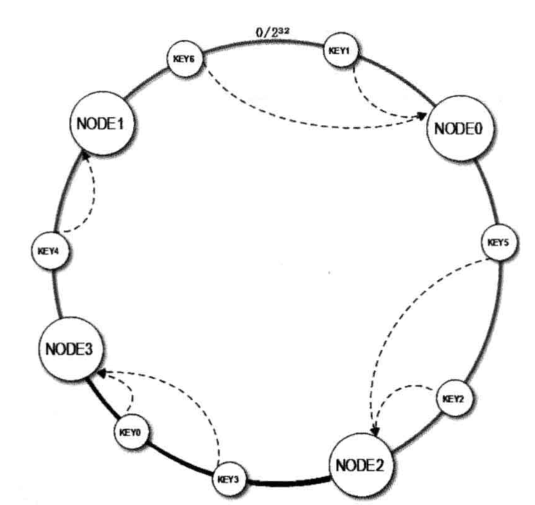
在node2和node0中插入一个node3,则导致node2到node1中中原先存放在node1中的数据分成两半,node2-node3部分存放在node3中,node3和node1的存放在node1中,则可以看出node0-node2以及node0-node1中这段没有改变。则也是75%但是还有问题就是node2和node0的负载数是node2的一倍,所以还是得出现解决办法
引用虚拟的方式:将一个物理分布式缓存服务器分层n个虚拟机,分布在这个圆环周围,由于hash散列的不规则性,他会分布于不同的区域,见下图,如果再次插入新服务器之后,他会在器分布的虚拟机器上不规则的分布于各个点中,则会比较均匀的分布在各个环中,这样影响的可以将上面的问题解决了。

根据该书说明,在实践中,一台物理服务器虚拟成150个虚拟服务器节点合适。