DNS中的ACL机制介绍

试想一下,如果允许递归(或查询)的客户端太多,而且它们不在同一网段中,那么如何实现配置呢?
如:allow-query { 192.168.241.0/16;127.0.0.0/8;10.0.0.0/8 };,如果allow-recursion {}、allow-transfer{}也都写一遍相同的内容,非常麻烦。而我们在写脚本时,可以使用变量、函数等结构化的方式来解决此类问题。而在named.conf中也可以使用这种机制,这就是ACL(访问控制列表,即若都用到定义这些相同的客户端,可以讲这些客户端总结放在前头,并给它取一个名字,以后用到随时使用即可)。
acl定义方法:(必须先定义才能使用)
定义:
acl ACL_NAME{
IP列表
};
使用如下所示:
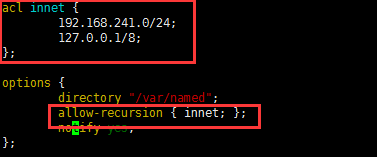
acl innet{
192.168.241.0/24;
127.0.0.0/8;
};
allow-query { innet; };
named内置的两个常用列表:
none;
any;(表示任意)
配置文件中使用:
智能 DNS
中国有两大网络运营商:telecom、unicom,电信和联通两个网络有各自独立的接口。它们彼此之间的网络没有结合起来,而是两个独立的网络。而在某个机房中有一个总接口将两个网络连接起来了。总贷款大约只有100G。
因此两个网络之间的交互会变得非常慢,但在网内的速度会比较快。
若建立一个网站放在联通机房,那么来自于电信的客户端访问速度会很慢。而如果在联通、电信各放一台服务器,在它们数据同步时仍然会占据很多带宽,效率很慢。由此可以想到的解决办法是双线接入,电信有一根、网通有一根,而后在它们内部使用协议实现路由,因此我们可以在机房中只放一台服务器,只不过可以给它配一个或两个IP地址,只要服务器或机房本身能够实现双线接入那么使用一个IP地址就能连接两个网络了。
此时在假设一种极端情况,向淘宝这样的站点在双11的时候服务器的压力是非常大的。有一种缓解服务器压力的办法是把全国分成几个大区,在每一个大区中,不论用户来自于哪个网络,假如都是双线机房放置一组服务器,用户直接在离自己最近的服务器交易,将来统计有多少笔交易时,可以在最后进行汇总。而交易只需要在离用户最近的服务器完成即可。
那么回到我们的DNS服务器来说,DNS服务器能够实现这种每一个用户访问的时候都访问离自己最近的那台服务器的功能吗?
DNS服务器能够根据客户端来源所属的网络进行判断并且返回给用户一个我们实现定义好的IP地址,这种机制称为智能DNS。
智能DNS实现机制:DNS在自己的服务器内部可以做视图(View)。
例:DNS服务器解析域名www.test.com
将所有客户端来源分成两类,一类是联通网的,一类来自电信网的。现在服务器期望来自联通网的用户解析www.test.com结果是位于联通机房服务器的地址,而来自于电信网络的用户返回来自电信网络的IP地址。
实现方法:可以将数据文件切割成两部分,如果客户端来自联通,查找对应联通的数据文件,电信同理。像这样使用两个数据文件分别对应来自不同网络的请求,由此,可以将一个域名的解析结果一分为二,这种结果称为(split prain)脑链。而只要能够把客户端分成几类,就能提供对应不同的数据文件,如全国可区分成不同地域(湖南联通、湖南电信、浙江联通、浙江电信、河南联通、河南电信...)。
web对象缓存:
在用户访问Web页面请求Web资源的情景之下,当公司内部双线机房中放置服务器组,在各地网络中各自放了一个缓存服务器,当用户第一次访问离它最近的缓存服务器时,缓存中没有相关内容,缓存服务器会联系相应的服务器取得内容并缓存web对象(或页面)至本地,当同一个网络当中的第二个用户来访问的时候,若访问的是同一个缓存服务器,则直接从缓存服务器返回结果即可。将来若需要修改直接从原始服务器修改即可。因此虽然第一次请求时可能较慢,但运行一段时间之后,内容都会被缓存到离用户最近的缓存服务器
而像这种能够判断客户端来源并且返回离用户最近的服务器并且能够根据原始服务器取得内容后缓存到本地的这种网络就称为CDN(内容分发网络,Content Delivery Network)。对于Web服务器而言,仅能获取静态内容(图片等),动态内容才需要从原始服务器获取,而且动态内容绝大部分也能通过策略设定进行静态化并缓存至本地,所以这种结果速度要快得多了。
CDN有一个重要的前提是:能够判断客户端来源,而且能够根据客户端来源返回离它最近服务器地址。而智能DNS就可以实现这样的功能,因此智能DNS对于现代网络运营来讲是一个比较重要的功能。
模拟实现智能DNS:
假设有两个网络:
假定电信网络地址为:192.168.241.0/24,127.0.0.0、8
其它为电信网络
那么来自不同客户端用户请求同一个域名解析结果,结果是否能够实现不同呢?
1、安装配置DNS(需要三台主机模拟实现功能,(一个为DNS服务器,两台模拟位于不同网络的客户端))
2、配置DNS智能解析功能
view VIEW_NAME{
};
注意:一旦使用了视图,所有的区域都必须定义在视图中,zone "." IN 只需要定义在需要递归的视图中。
定义两个视图,分别表示电信、网通:

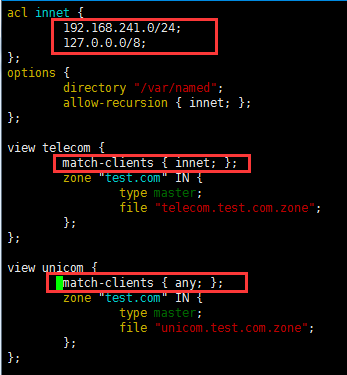
#match-clients { any; }; #定义匹配来自什么地方的客户端

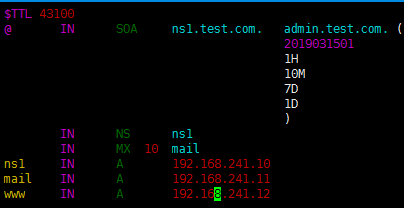



在属于不同网络的不同主机上进行测试,查看结果。
实现一台DNS服务器解析多个域,如解析test.com.和a.net.并且a.net.不区分客户端来源,实现如下:

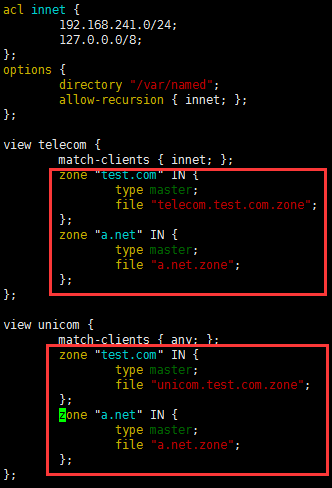




测试:
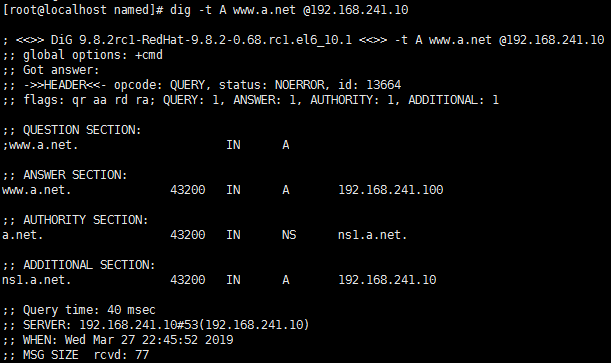
DNS服务器启动完成之后,它会将数据文件直接载入内存,所以其解析过程、查找过程是在内存中完成的,所以其速度非常快。
如果数据文件改动重新启动需要重新分析并加载数据文件,但若数据文件非常大,速度会非常慢,由此,我们可以把区域的定义不再写入到配置文件中,而是存放到数据库的数据表中,DNS启动时,会将表中的数据抽取出来,存到内存中去,而且新加的内容不用每次都去重启直接添加即可。哪一个域用到了,临时去查数据库得到的结果,而不是直接载入内存;随时改,随时生效,不用重新读取;但每一次读取都需要查询数据库,在内存中可能通过0.0001秒就能完成,而通过数据库需要10秒才能完成。
所以使用数据库固然使得管理方便了,但效率降低了,但对于某些公用服务器来讲,这是比较常见的做法,如:互联网上较著名的两个项目:
- dnspod:中国著名的免费智能DNS提供商。将来注册域名时,可以将域名服务器指向dnspod服务器,在dnspod上建立记录实现智能解析,不但能分网,还能分省和分网,如:教育网,联通,电信,国外;甚至于付费可解析全国各地网络(在数据库中建立区域,实时查找);
- www.dns.la;
dlz:
实现数据文件放在MySQL数据库的一种机制。
DNS日志系统
启用DNS日志:

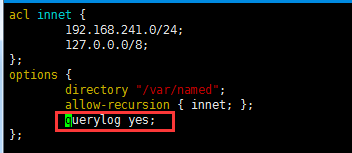

测试:
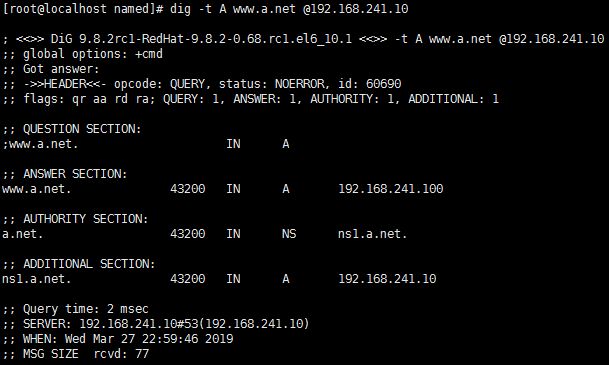
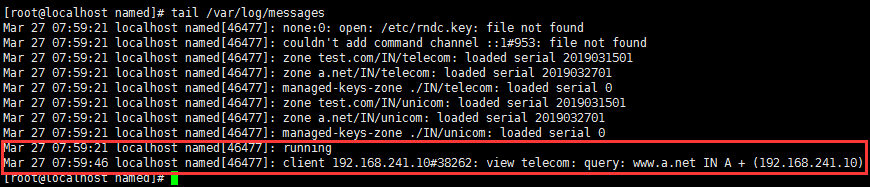
使用日志记录BIND的工作机制:

category:日志源
可选项:
- 查询
- 区域传送
可以通过category自定义日志来源
channel:日志保存位置
发给syslog:记录至/var/log/message
file:自定义保存日志信息的文件
定义channel:

需要注意的是,一个日志类别产生的多个不同类别的信息可以发往不同的位置,但每一个位置只能保存来自于一个category的信息(一个category可以被定向到多个channel,但一个channel只能属于一个category)
定义DNS BIND日志的格式:
示例:

实现在/var/log/下新建一个文件夹bind用于记录查询日志:


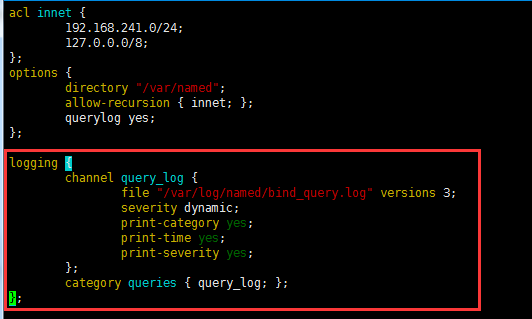

测试:


记录传输日志:

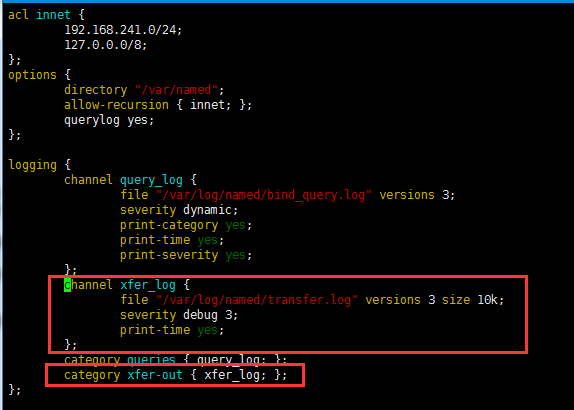

测试:
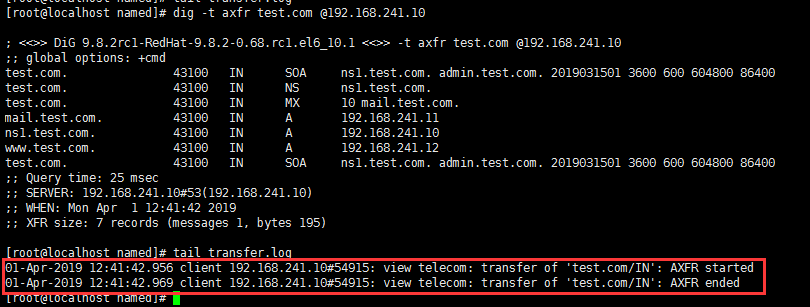
这是一个非常具有弹性的日志系统,可以自己定义哪一种信息放置在什么位置。一般来讲,查询日志和安全日志最好不要开启,因为它们所面临的日志信息太多,而跟更新相关的信息应该开启。
日志编写格式参照:

推荐书籍:
《Bind97 Manual》
《OReilly DNS and BIND 5th(2006)》(学习DNS最经典的一本书)
DNS服务器性能
软件:
- dnstop
用于监控DNS服务器在每秒钟能够接受多少个查询,而且都是对应哪个域名发起的查询请求的。
- queryperf
用于对DNS做压力测试,测试每秒钟能够做多少次域名请求。
queryperf使用示例:
安装开发环境:





至此可使用queryperf命令了;
使用示例:


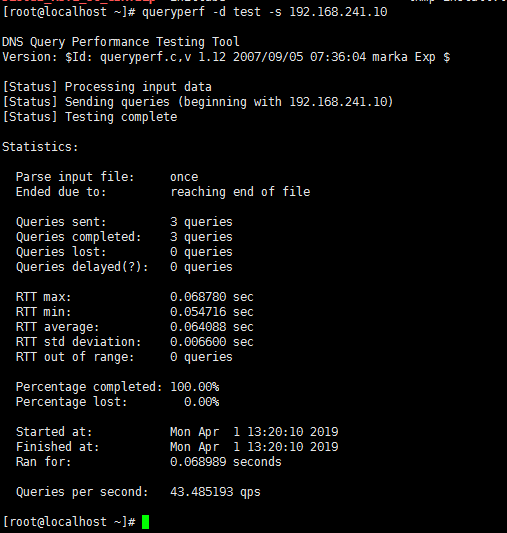

复制将test文件中的内容若干次(10万行+)

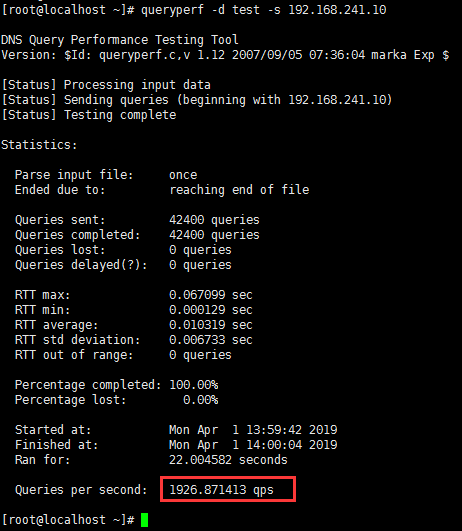
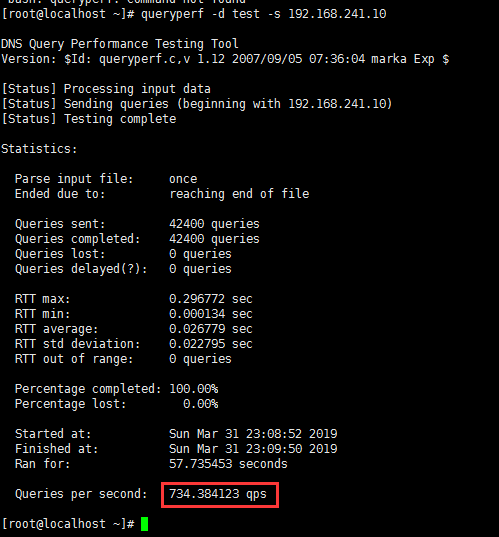
在另一台虚拟机上测试:
拷贝至测试机:

测试机测试:
dnstop使用示例:

libcap-devel:抓包工具




