一、定义
在训练数据集上的准确率很⾼,但是在测试集上的准确率⽐较低
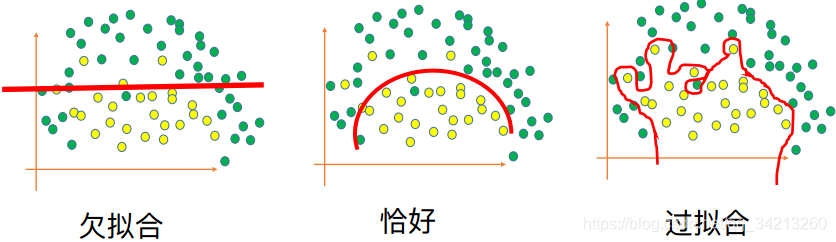
二、理解bias和variance
模型的偏差bias:简单来说训练出来的模型在训练集上的准确度。
模型的方差variance:就是模型在不同训练集上的效果差别很大。方差越大的模型越容易过拟合。假设有两个训练集A和B,经过A训练的模型Fa与经过B训练的模型Fb差异很大,这意味着Fa在类A的样本集合上有更好的性能,而Fb在类B的训练样本集合上有更好的性能,这样导致在不同的训练集样本的条件下,训练得到的模型的效果差异性很大,很不稳定,这便是模型的过拟合现象。
数学表达如下:
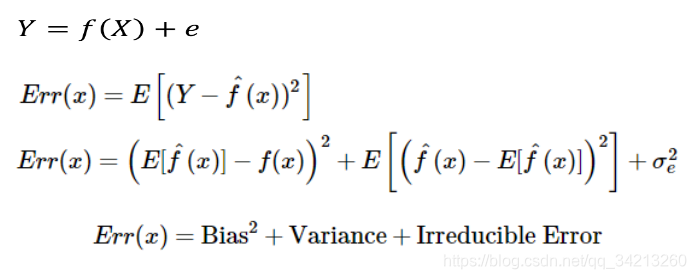
其中:
f(X)是整体数据的真值;
e为测量噪声;
Y为实际使用的label
f(x)^为在训练集x上预测的结果
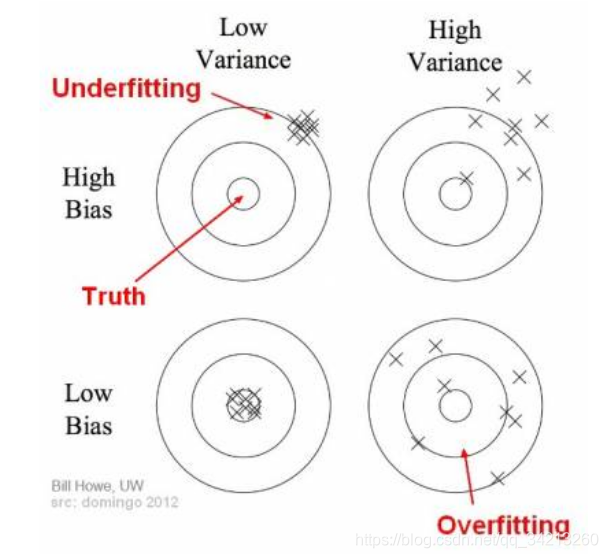
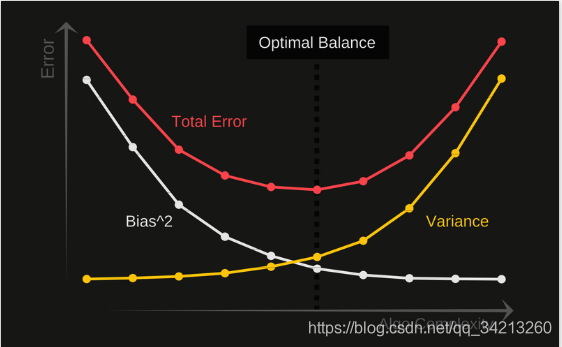
过拟合和欠拟合实际就是寻找Bias 和variance的平衡方案
三、判断欠拟合和过拟合的方法
查看loss曲线
四、 欠拟合的解决方按
4.1 欠拟合loss变化曲线(1)
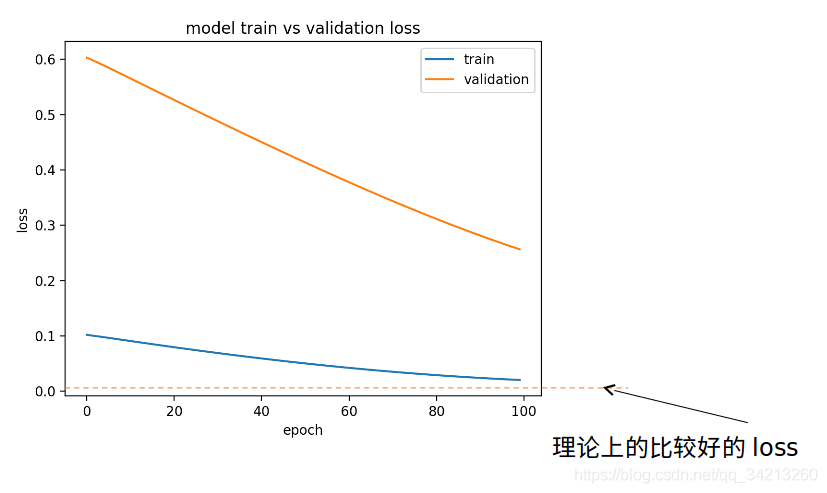
这种情况loss曲线还是在下降的,因此只需要进行更多更高效的训练即可:
- 增大batch-size
- 调整激活函数(使用relu)
- 调整优化算法
- 增加训练epoch
- 使用Adam
- 增大learning rate
4.1 欠拟合loss变化曲线(2)
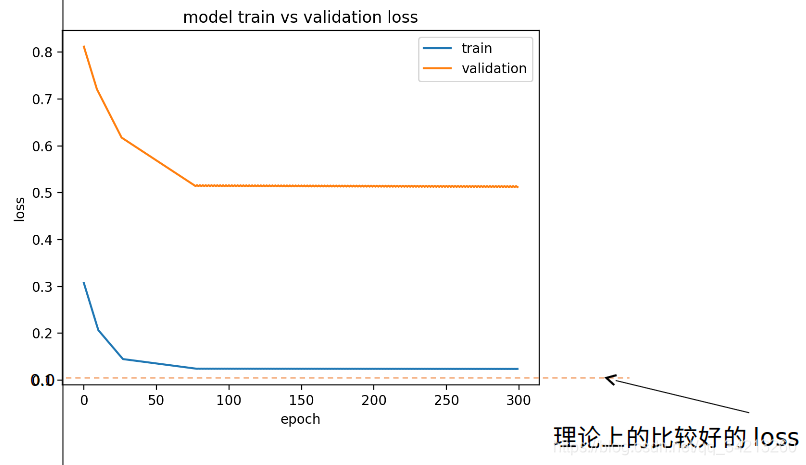
这种情况loss曲线已经不再下降因此必须优化模型:
-
增加网络复杂度
- 增加层数
- 增加卷积层输出的通道数
- 增加全连接层的节点数
-
检测训练数据集和测试数据是否有相对应的特征
- 增加训练数据的种类, 使得训练数据覆盖所有测试数据的特性
- 使用数据增强
五、过拟合的解决方案
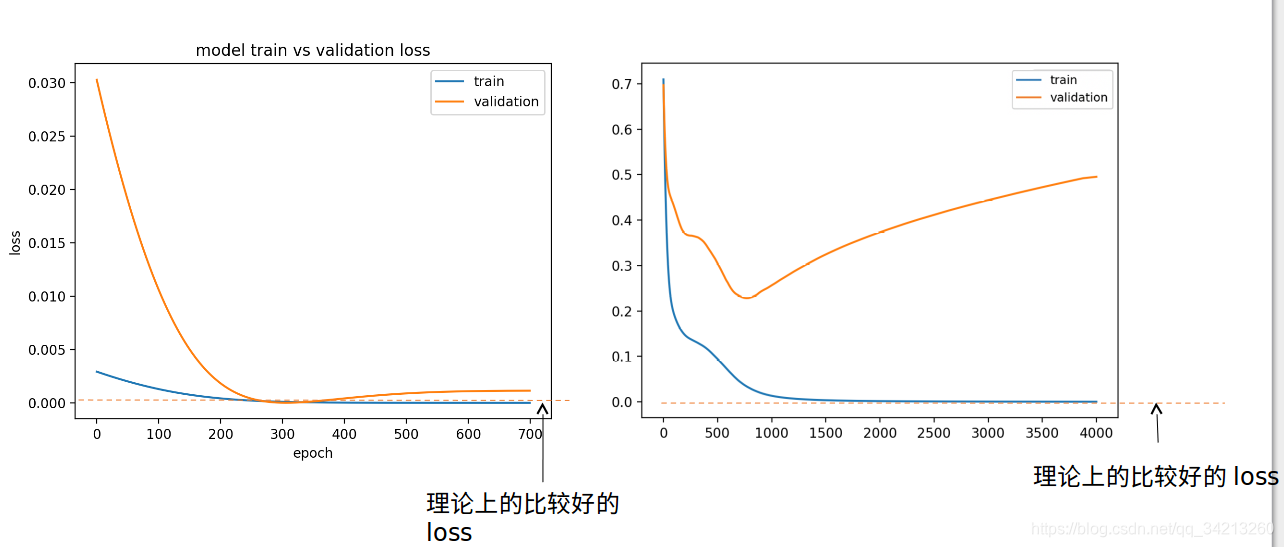
5.1 DropOut
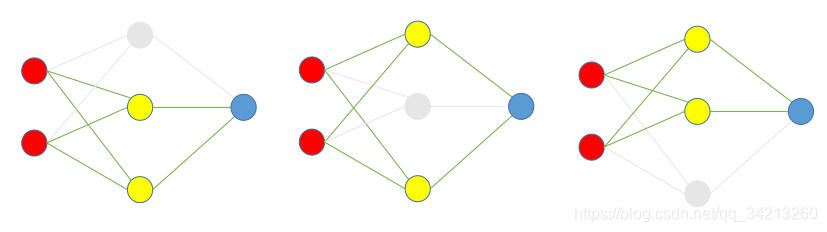
假设有一个过拟合的神经网络如下:
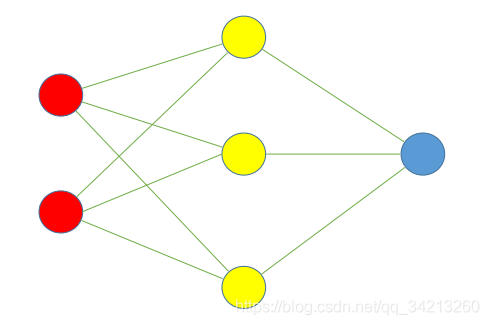
DropOut步骤:
- 根据DropOut rate(这里假设为 1/3),在每组数据训练时,随机选择每一隐藏层的1/3的节点去除,并训练。如下图是三次训练的过程:
 2. 使用时,把神经网络还原成原来没有去除过节点的样子,如下图。但是系数~(w,b)~需要乘以(1-DropOut rate)
2. 使用时,把神经网络还原成原来没有去除过节点的样子,如下图。但是系数~(w,b)~需要乘以(1-DropOut rate)

5.2 L2 正则化
5.2.1 方法
对损失函数(loss function) f(θ) 中的每一个系数θ~i~,都对损失函数加上1/2λθ~i~^2^,其中λ是正则化的强度。
- 相当于,在训练的每一次更新系数的时候都额外加上这一步:
θ~i~= θ~i~ - λθ~i~
5.2.2 目的
L2正则化的目的是使系数的绝对值减小,对绝对值越大的系数,减小的程度越强。L2正则化使得大多数系数的值都不为零,但是绝对值都比较小。
5.3 L1 正则化
5.3.1 方法
对损失函数(lossfunction)f(θ)中的每一个系数θ~i~,都对损失函数
加上λ|θ~i~|,其中λ是正则化的强度。
- 相当于,在训练的每一次更新系数的时候都额外加上这一步:
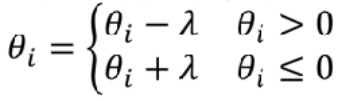
5.3.2 目的
L1正则化的目的是使得许多系数的绝对值接近0,其它那些系数不接近于0的系数对应的特征就是对输出有影响的特征。所以L1正则化甚至可以用于作为特征选择的工具。
5.4 最⼤范数约束 (Max Norm)
5.4.1 方法
对每一个神经元对应的系数向量,设置一个最大第二范数值c,这个值通常设为3。如果一个神经元的第二范数值大于c,那么就将每一个系数值按比例缩小,使得第二范式值等于c。
-
相当于在训练的每一次更新系数的时候都额外加上这一步:
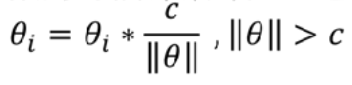
注意:只有当||θ||>c才执行
5.4.2 目的
由于最大范数的约束,可以防止由于训练步长较大引发的过拟合。
5.5 模型太复杂
模型太复杂,减少模型每一层的节点
打赏
如果对您有帮助,就打赏一下吧O(∩_∩)O

