@
目录
一、REGION CNN
1.1 原理
滑窗法是一种行之有效的暴力方法,先生成大量的候选框,对每个框进行分类,可以大概的检测出类

- 一张图像生成1K~2K个候选区域
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
1.2 候选区域生成方法
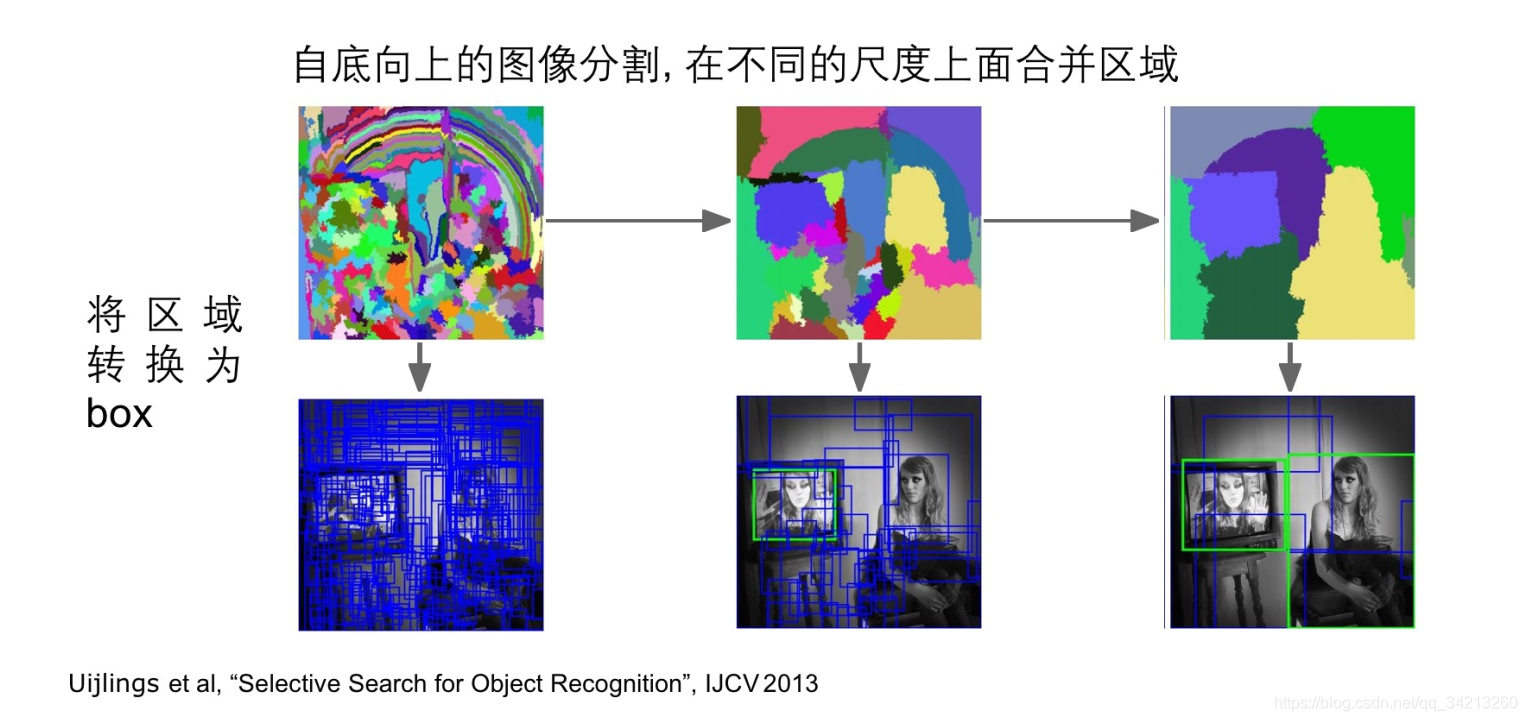
使用了Selective Search方法从一张图像生成约2000-3000个候选区域。基本思路:
- 传统分割算法(如像素点聚合),将图像分割成小区域
- 使用贪心算法合并候选区域:计算所有相邻区域的相似度。将最相似的两个区域合并为一个区域。重复直到整张图像合并成一个区域位置
- 输出所有曾经存在过的区域,生成候选区域
1.3 训练过程
- 预训练:在lmageNet上面训练一个分类神经网络
- 使用Selective Search找出候选区域
- 将候选区域resize成CNN输入的尺寸
- fine-tuning:在自己的训练数据集中fine-tune CNN,作为一个识别K+1种类别的分类问题,K为感兴趣的目标种类数,1为背景类别.Fine-tune使用比较小的learning-rate,在正样本上面oversample (selective search出来的候选区域大多为背景)
- 去掉fine-tune后的CNN的最后一个分类层,将每一个候选区域通过CNN,输出为一个特征向量,
- 使用特征向量为每一个类别训练一个二元SVM分类器(正样本为候选区域和真实区域loU大于等于0.3的区域,其它为负样本)
- 为了减少Selective Search候选区域定位误差,使用regression模型预测新的定位
 di是和ti一样的转换后的比例值
di是和ti一样的转换后的比例值

1.4 R-CNN的计算瓶颈
· 对于每一幅图,使用Selective Search选择2000个候选区域,这个过程本身比较慢
. 2000个区域都要使用CNN网络预测图像特征,这些区域还会有重叠的部分
· 4个分离的部件没有重用计算:
- Selective Search:选择候选区域
- CNN:提取图像特征
- SVM:目标分类识别 Regression模型:定位
二、Fast RCNN

2.1 改进点
- 将R-CNN中下面3个独立模块整合在一起,减少计算量:
- CNN:提取图像特征
- SVM:目标分类识别
- Regression模型:定位
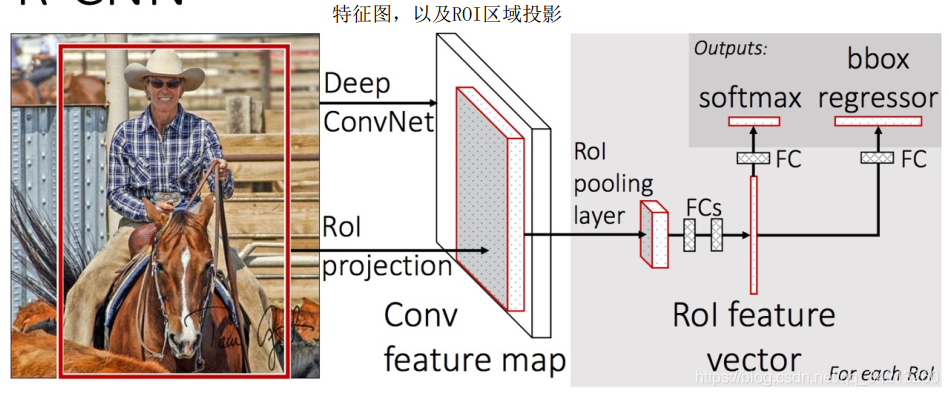
- 不对每个候选区域独立通过CNN提取特征,将整个图像通过CNN提取特征,然后从CNN的特征图中根据Selection Search的候选区域通过Rol Pooling层提取区域特征
2.2 网络结构


2.3 ROI Pooling
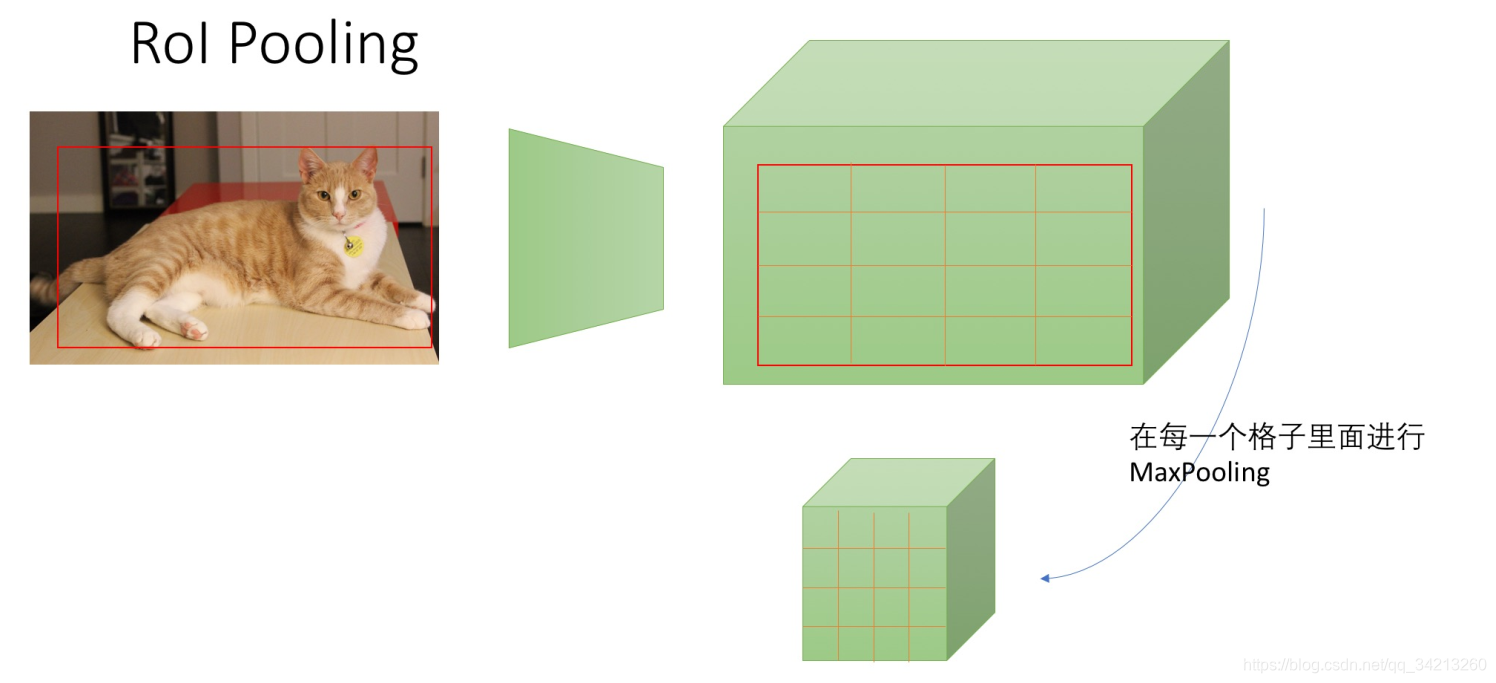
- 将任意大小的特征图(CNN的输出)使用Max Pooling转换为固定大小的特征图.
- 假设Rol Pooling的输入为H1* W1像素,输出为H2W2像素(H2<H1; W2< W1),那么输入特征图会被平均分为H2 W2个格子(每一个格子包含H1/H2 * W1/W2个像素).然后对每一个格子做MaxPooling.
2.4 损失函数

2.5 总结
优点:
- 由于图像只通过CNN一次,而不是让每一个候选区独立通过CNN,减少了运算量
- 将R-CNN中的多个SVM的分类合并为一个DNN,让分类和定位可以同时训练
缺点:
- 但是任然依靠Selective Search选择候选区域
三、Faster R-CNN
去掉selective Search,将候选区域的选择整合到深度学习网络模型中(Region Proposal Network: RPN和fast R-CNN结合)
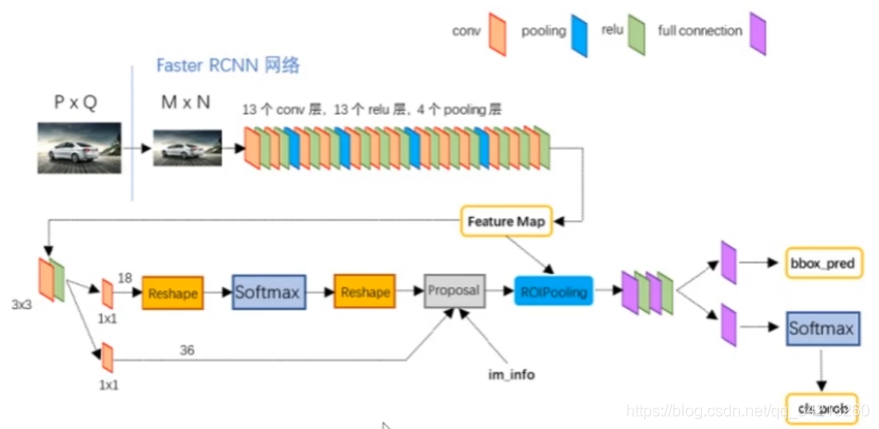
3.1 RPN网络
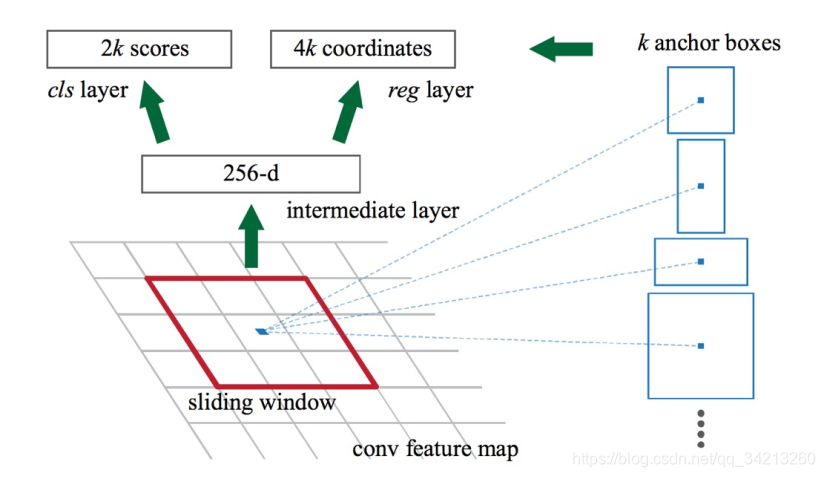
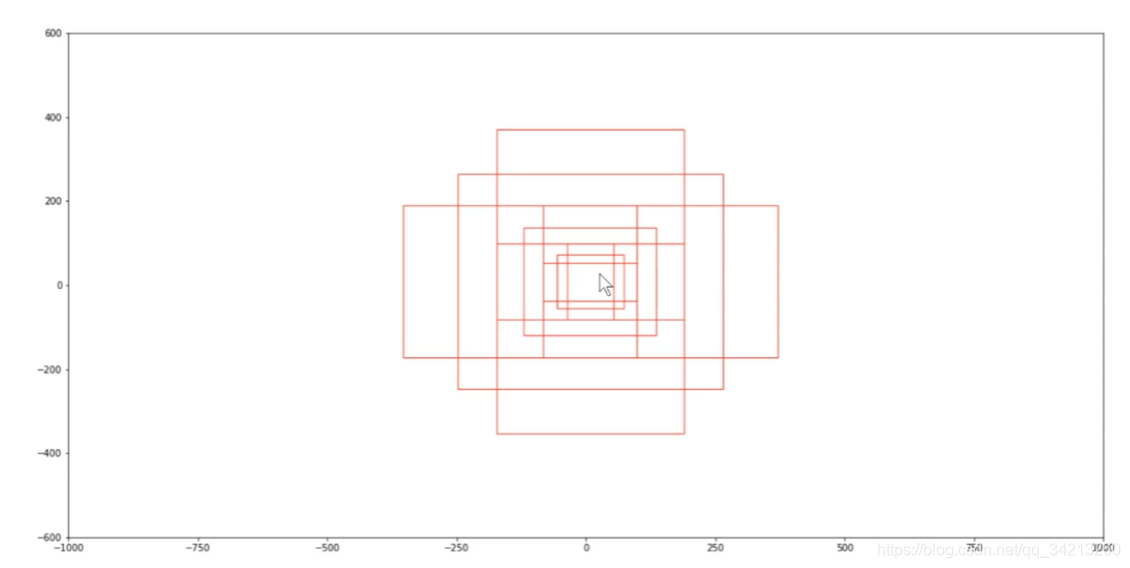
3*3的滑窗。在每个中心生成k(k=9)个anchor boxes。每个anchor boxes需要判断里面是否有需要识别的物体(前景和背景),所以有2k个得分。每个anchor boxes还有四个坐标,所以有4k个坐标
- 一个点处的anchor boxes
3.2 损失函数

3.3 训练步骤
