1、模型评估方法
1)试验测试法:一个测试集去测试模型,以测试集上的"测试误差" (testing error)作为泛化误差的近似
注意:测试集应该尽可能与训练集互斥, 即测试样本尽量不在训练集中出现、未在训练过程中使用过.
1)留出法
"留出法" (hold-out)直接将数据集 D 划分为两个互斥的集集合作为训练集S,另一个作为测试集 T,
即 D=S∪T , S∩T=Φ,在S上练出模型后,用 T 来评估其测试误差,作为对泛化误差的估计.
常见做法是将大约 2/3~ 4/5 的样本用于训练,剩余样本用于测试.
2)交叉验证法
"交叉验证法" (cross validation)先将数据集 D 划分为 k 个大小相似的互斥子集, 即 D = D1 U D2υ... U D k, Di n Dj = ø (í ≠ j ) .
每个子集 Di 都尽可 能保持数据分布的一致性,即从 D 中 通过分层采样得到. 然后,每次用k-1 个子集的并集作为训练集,其余
的那个子集作为测试集;这样就可获得 k组训练/测试集,从而可进行 k 次训练和测试,最终返回的是这 k 个测试结果的均值。
3)自助法(外包估计)给定包含 m 个样本的数据集 D , 我们对它进行采样产生数据集 D': 每次随机从 D 中挑选一个样本,将其拷贝放入 D' 然后再
将该样本放回初始数据集 D 中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行 m 次后,我们就得到了包含 m个样
本的数据集 D‘,这就是自助采样的结果.自助法会引入估计误差,因此在初始数据量足够时,留出法和交叉验证法更常用一些.
2、性能度量

1)错误率与精度
2)查准率和查全率

2)F1度量
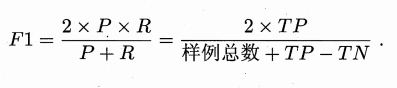

3)ROC与AUC
ROC 曲线的纵轴是"真正例率" (True Positive Rate,简称 TPR),横轴是"假正例率" (False Positive
Rate,简称 FPR) ,基于表 2.1 中的符号,两者分别定义为
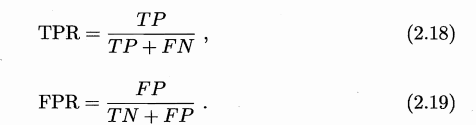
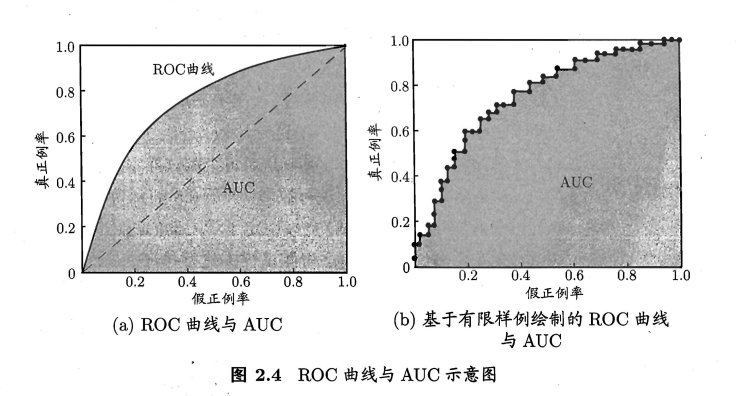
进行学习器的比较时, 与 P-R 图相似, 若一个学习器的 ROC 曲线被另 一个学习器的曲线完全"包住", 则可断言后者的性能优于前者;若两个学习器
的 ROC 曲线发生交叉,则难以-般性地断言两者孰优孰劣 . 此时如果一定要进行比较, 则较为合理的判据是 比较 ROC 曲线下 的面积,即 AUC (Area Under
ROC Curve) ,如图 2.4 所示
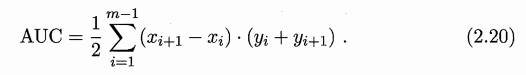 AUC是灰色部分的面积
AUC是灰色部分的面积

4)代价敏感错误率与代价曲线


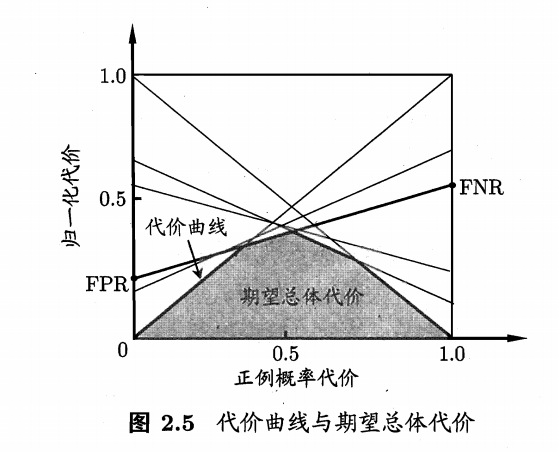
3、比较检验