1. Java垃圾回收机制
1.1. Java垃圾的判断
- 引用计数法
- 可达性分析
1.2. 回收算法
1.2.1. 标记清除
先标记再清除,会有很多碎片,连续空间不足,不足以分配大对象,从而直接gc
1.2.2. 复制算法
将内存分为两块,存活的复制到另外区域,剩余被视为垃圾的一并回收
1.2.3. 标记整理算法
和标记清除类似,加上了整理,腾出连续空间
1.2.4. 分代垃圾回收
商业垃圾回收器都是用这种算法。根据对象存活周期的不同将内存划分为几块并采用不用的垃圾收集算法
1.3. 垃圾回收器
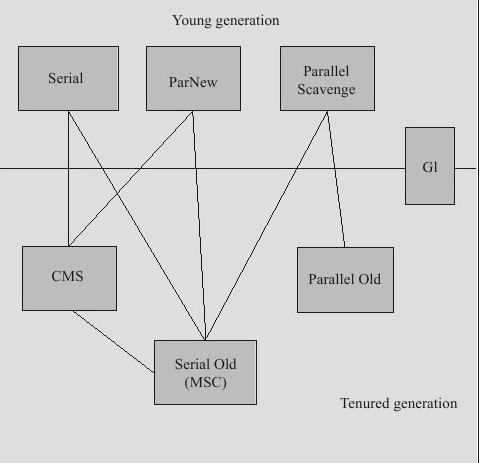
1.3.1. Serial(串行垃圾回收器)
虚拟机运行在 Client 模式下的默认新生代收集器,高效,极短的停顿,需要stop the
Word
1.3.2. Parnew
ParNew 收集器其实就是 Serial 收集器的多线程版本
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个 CPU 上。
1.3.3. Parallel scavenge垃圾回收器
新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器特殊之处在于:标则是达到一个可控制的吞吐量。
最大垃圾收集停顿时间的-XX:MaxGCPauseMillis
设置吞吐量大小的-XX:GCTimeRatio
如果把此参数设置为 19,那允许的最大 GC 时间就占总时间的 5%(即 1/(1+19)),默认值为 99 ,就是允许最大 1%
-XX:+UseAdaptiveSizePolicy 打开之后态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为 GC 自适应的调节策略(GC Ergonomics)。
拟机总共运行了 100 分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%
1.3.4. CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。特点:并发收集、低停顿
整个过程分为4个步骤,包括:
- 初始标记(CMS initial mark)
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark)
- 并发清除(CMS concurrent sweep)
初始标记、重新标记这两个步骤仍然需要"Stop The World",整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作。这个是一下导致缺点的原因(浮动垃圾)
缺点:
导致吞吐量降低(低停顿追求)、CMS 收集器无法处理浮动垃圾、产生空间碎片(追求低停顿,不整理)
1.3.5. G1垃圾回收(garbege first)
定位取代cms,收集器是当今收集器技术发展的最前沿成果之一
特点:
- 并行与并发
- 分代收集
- 空间整合(整体,标记整理,局部 复制)
- 可预测的停顿
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记(Initial Marking)
- 并发标记(Concurrent Marking)
- 最终标记(Final Marking)
- 筛选回收(Live Data Counting and Evacuation)
1.4. Gc日志
1.4.1. Gc日志
开启gc日志
title subway:8206 java -jar -Xms8192M -Xmx8192M -Dserver.port=8206 -Dcsp.sentinel.dashboard.server=127.0.0.1:8206 -Dproject.name=sentinel-dashboard -Dfile.encoding=utf-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:D:subway.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps blade-subway.jar
为了方便用户阅读,将各个收集器的日志都维持一定的共性,例如以下两段典型的 GC 日志:

最前面的数字33.125: 和 100.667: 代表了 GC 发生的时间,这个数字的含义是从 Java 虚拟机启动以来经过的秒数。
GC 日志开头的 [GC 和 [Full GC 说明了这次垃圾收集的停顿类型,而不是用来区分新生代 GC 还是老年代 GC 的。
如果有 Full ,说明这次 GC 是发生了 Stop-The-World 的,例如下面这段新生代收集器 ParNew 的日志也会出现 [Full GC(这一般是因为出现了分配担保失败之类的问题,所以才导致 STW)。如果是调用 System.gc() 方法所触发的收集,那么在这里将显示 [Full GC(System)。

接下来的 [DefNew、[Tenured、[Perm 表示 GC 发生的区域,这里显示的区域名称与使用的 GC 收集器是密切相关的,例如上面样例所使用的 Serial 收集器中的新生代名为 "Default New Generation",所以显示的是 [DefNew。如果是 ParNew 收集器,新生代名称就会变为 [ParNew,意为 "Parallel New Generation"。如果采用 Parallel Scavenge 收集器,那它配套的新生代称为 PSYoungGen,老年代和永久代同理,名称也是由收集器决定的。
后面方括号内部的 3324K->152K(3712K)含义是GC 前该内存区域已使用容量 -> GC 后该内存区域已使用容量 (该内存区域总容量)。而在方括号之外的 3324K->152K(11904K) 表示 GC 前 Java 堆已使用容量 -> GC 后 Java 堆已使用容量 (Java 堆总容量)。
再往后,0.0025925 secs 表示该内存区域 GC 所占用的时间,单位是秒。有的收集器会给出更具体的时间数据,如 [Times:user=0.01 sys=0.00,real=0.02 secs] ,这里面的 user、sys 和 real 与 Linux 的 time 命令所输出的时间含义一致,分别代表用户态消耗的 CPU 时间、内核态消耗的 CPU 事件和操作从开始到结束所经过的墙钟时间(Wall Clock Time)。
CPU 时间与墙钟时间的区别是,墙钟时间包括各种非运算的等待耗时,例如等待磁盘 I/O、等待线程阻塞,而 CPU 时间不包括这些耗时,但当系统有多 CPU 或者多核的话,多线程操作会叠加这些 CPU 时间,所以读者看到 user 或 sys 时间超过 real 时间是完全正常的。
1.4.2. 垃圾回收逻辑
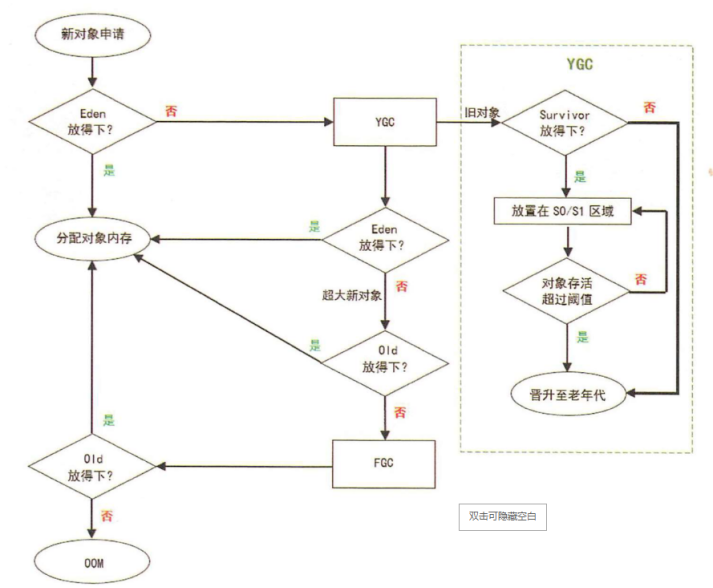

来自:
https://www.cnblogs.com/czwbig/p/11127159.html (垃圾回收日志部分很不错)