一:group_concat函数详解
1.语法如下:
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
2.基本查询:
select * from aa;
结果:
+------+------+ | id| name | +------+------+ |1 | 10| |1 | 20| |1 | 20| |2 | 20| |3 | 200 | |3 | 500 | +------+------+ 6 rows in set (0.00 sec)
3. 以id分组,把name字段的值打印在一行,逗号分隔(默认)
select id,group_concat(name) from aa group by id;
结果:
+------+--------------------+
| id| group_concat(name) |
+------+--------------------+
|1 | 10,20,20|
|2 | 20 |
|3 | 200,500|
+------+--------------------+
3 rows in set (0.00 sec)
4. 以id分组,把name字段的值打印在一行,分号分隔
select id,group_concat(name separator ';') from aa group by id;
结果:
+------+----------------------------------+
| id| group_concat(name separator ';') |
+------+----------------------------------+
|1 | 10;20;20 |
|2 | 20|
|3 | 200;500 |
+------+----------------------------------+
3 rows in set (0.00 sec)
5. 以id分组,把去冗余的name字段的值打印在一行
select id,group_concat(distinct name) from aa group by id;
结果:
+------+-----------------------------+
| id| group_concat(distinct name) |
+------+-----------------------------+
|1 | 10,20|
|2 | 20 |
|3 | 200,500 |
+------+-----------------------------+
3 rows in set (0.00 sec)
6. 以id分组,把name字段的值打印在一行,逗号分隔,以name排倒序
select id,group_concat(name order by name desc) from aa group by id;
结果:
+------+---------------------------------------+
| id| group_concat(name order by name desc) |
+------+---------------------------------------+
|1 | 20,20,10 |
|2 | 20|
|3 | 500,200|
+------+---------------------------------------+
3 rows in set (0.00 sec)
二:group_concat函数与find_in_set()
1.直接看例子明了,首先看表的内容
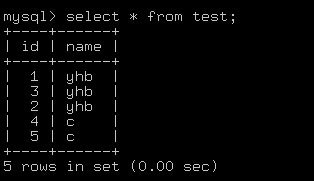
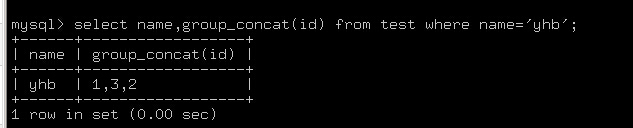
2.选出name='yhb'的记录
select name,group_concat(id) id from test where name='yhb';
结果为:
3.使用find_in_set筛选出name='yhb'的记录,当然这只是为了演示函数有什么效果
select a.* from test a join ( select name,group_concat(id) id from test where name='yhb') b on find_in_set(a.id,b.id) order by a.id;
结果为:

4.使用!find_in_set筛选出name!='yhb'的记录
select a.* from test a join ( select name,group_concat(id) id from test where name='yhb') b on !find_in_set(a.id,b.id) order by a.id;
结果为:
