写在前面的话:
该系列博文是我学习《 Hive源码解析与开发实战》视频课程的一个笔记,或者说总结,暂时没有对视频中的操作去做验证,只是纯粹的学习记录。
有兴趣看该视频的博友可以留言,我会共享出来,相互交流学习 ^.^。
*****************************************************************************************************
本文目录:
1、补充讲解上节课的Hive表操作;
2、Hive建表的其它方式;
3、Hive不同文件格式的读取方式:
4、Hive使用SerDe(即Hive使用序列化和反序列化);
5、Hive分区表;
6、Hive分区表的操作:
7、Hive分桶:
8、Hive分桶和分区的比较:
9、Hive查询:
10、总结记忆:
1、补充讲解上节课的Hive表操作:

上节课没有讲到show create table tablename 这条语句,因此针对该语句做实验:
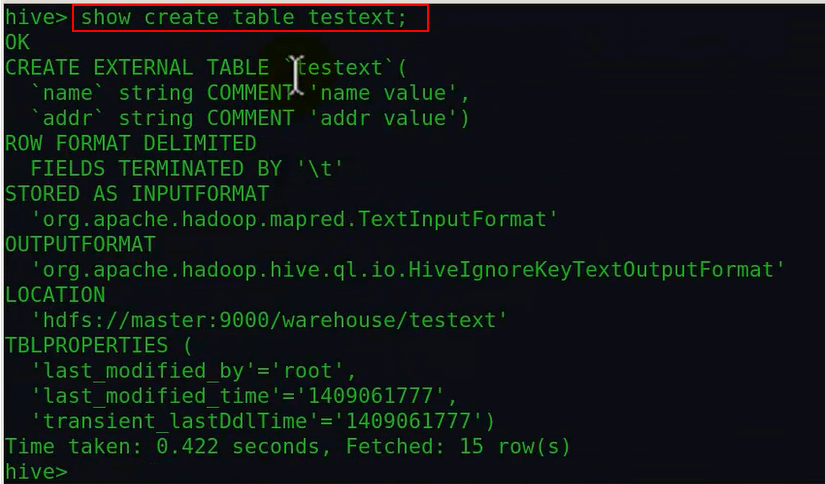
由上面可以看出,显示建表语句的作用是用来显示某一个已经创建好了的表 的 创建语句。
2、Hive建表的其它方式:

实验如下:
1、操作like创建方式:

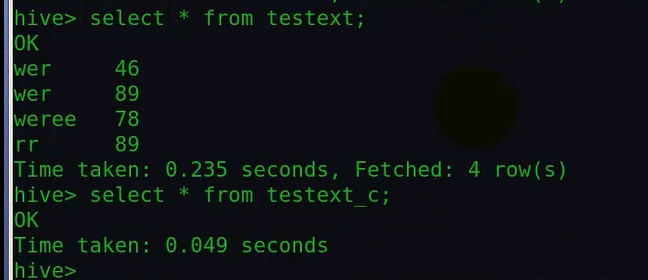
由上面的实验可以看出,like的方式只复制了表结构,没有复制数据。
并且上面的方式没有使用mapreduce,当然不会使用,因为只是复制了表结构,又没涉及到数据。
2、as的方式:
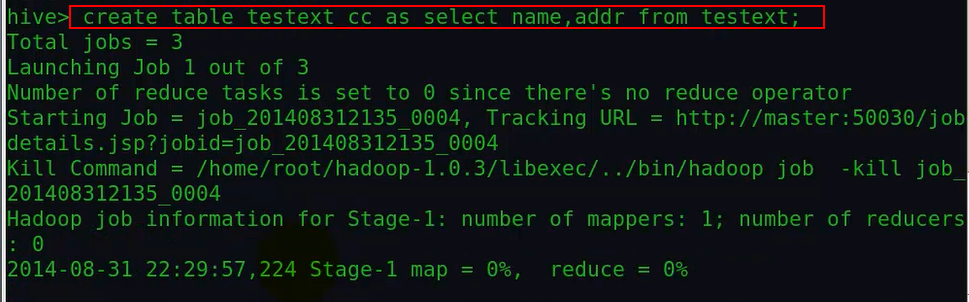
由上面可以看出,这种方式会使用mapreduce。
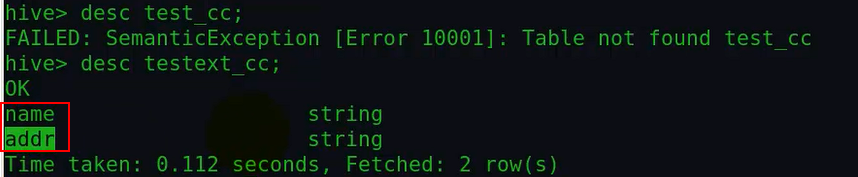
上面看到复制了查询的相应表结构。
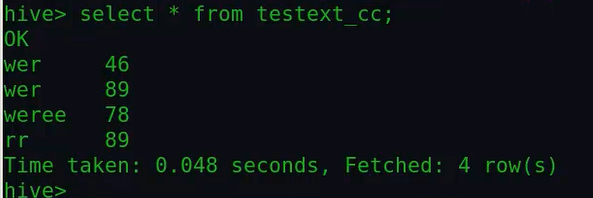
由上面看到同时还复制了相应的数据。
3、Hive不同文件格式的读取方式:

①对于textfile格式的文件:
可以直接查看hdfs或者用hadoop命令或者用hive的方式查看
②对于序列化格式的文件:
可以通过hadoop命令的方式来查看或者hive的方式查看
③对于列格式的文件:
需要通过hive命令来查看
④自定义的输入流inputformat:
需要通过outformat的自定义输出流来解析查看。这种方式的话,是首先写java类继承相应的input和output类,然后打成jar包放到linux上去,
如果只是某一次要使用该inputformat,那么只需要在一个hive中设置,这样只在单词hive会话中生效:

然后创建一个以该自定义inputformat格式存储的表:
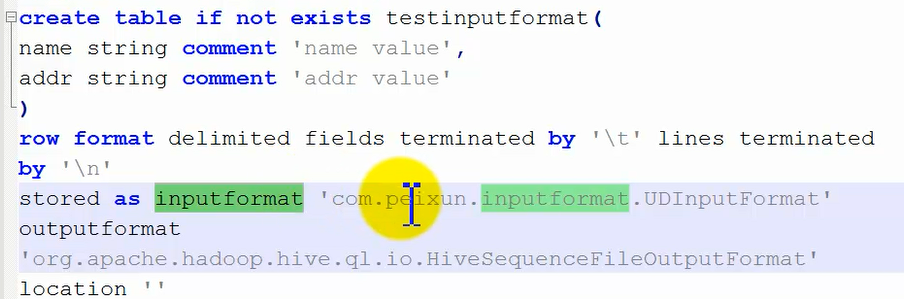
这种方式添加的inputformat只在当前hive终端中有效,如果重新启动hive后,再这样创建一个表,那么会报错:找不到这个inputformat自定义类。
如果要想hive全局使用,那么需要将该自定义inputformat的jar包拷贝到hive安装目录下的lib目录下面去,这个时候需要重启一个hive终端,这样才可以重新加载lib下的jar包,之前启动的hive,由于加载的是之前lib目录下的jar,所以是不可以成功找到该自定义类的。
4、Hive使用SerDe(即Hive使用序列化和反序列化):

比如说通过java代码使用Hive读取hdfs上的文件数据,然后会经过hive的反序列化成一个对象;当通过java代码把一个对象写到hive中去的时候,
hive会首先将该对象序列化,然后写到hdfs的文件中。
实际操作实验如下:
①首先创建一个指定使用某个序列化和反序列化的表:
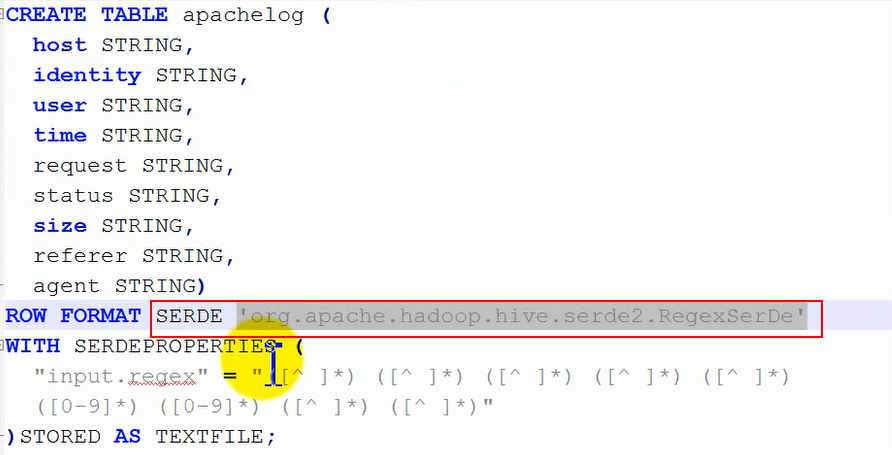
这里row format后面就没有之前的指定如何分割的语句了,取而代之的是指定用于序列化和反序列化的类:

5、Hive分区表:
Hive的分区和mapreduce中所说的分区是两回事,这里的分区是为了查询上的效率。
分区表和内部表和外部表的区别是:
分区表相当于是表目录的一个子目录,它和内部/外部表分类的标准就不同,可以说分区表是内部表和外部表的表目录下的子目录。
为什么会用到分区(分区表的作用):
分区表是通过创建表时,通过partitioned by 来进行指定按照那个或者那几个字段进行分区,比如说指定时间字段作为分区,按照一天进行分为一个区,那么每一天的数据
会存放在表目录下的一个子文件夹中,这样便于查询某一天的数据(只需要指定某一个分区的名字),而不用扫描整个表,从而提高效率。
具体分区表的创建语法如下:

Hive分区表样例:

另外注意分区 下面可以继续建分区,也就是说可以有多级的结构。就相当于一个目录下面建了一个子目录,在子目录下面还可以继续建子目录。
实验——创建分区表以及创建多级分区(分区下再创建分区):
①首先把下面的创建命令写到hive终端,进行执行:
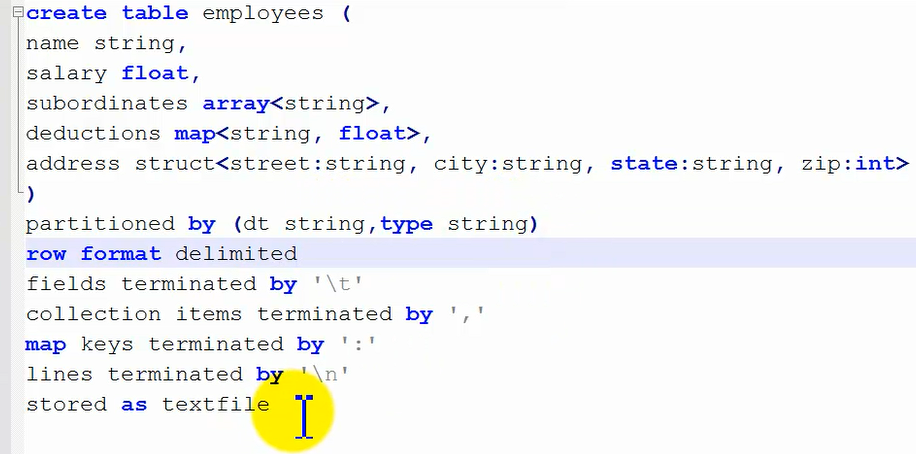
输入创建命令执行,这里是创建多级分区,也就是在一级分区子目录下面创建了二级分区子目录:
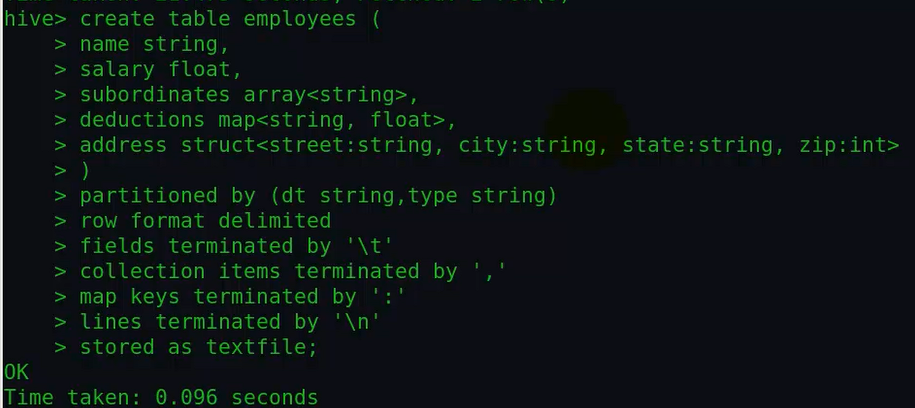
通过desc formatted tabelnam查看表详细的描述信息发现创建的分区表和普通表的区别在于:
分区表多了个分区描述信息,查看分区表和普通表详细信息进行对比如下:
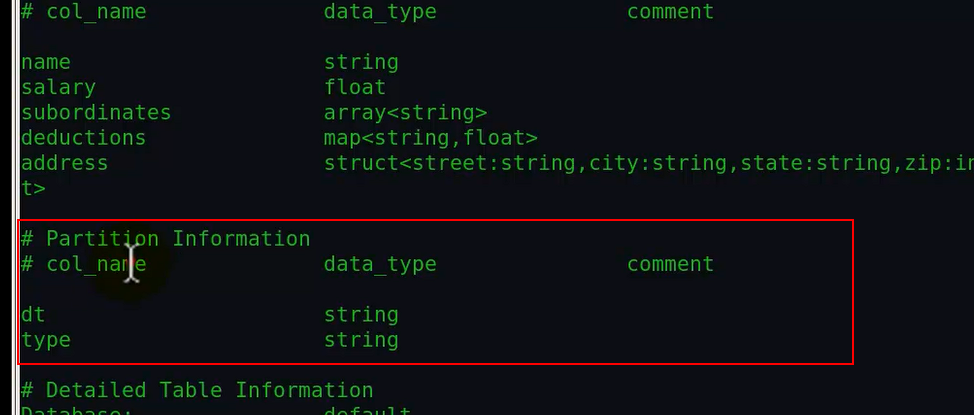

很明显可以看到分区表的详细信息(上面那幅图)中比普通表多了红色框里面的内容。
6、Hive分区表的操作:

实验——增加分区和删除分区:
①首先看下,没加分区之前的目录结构:
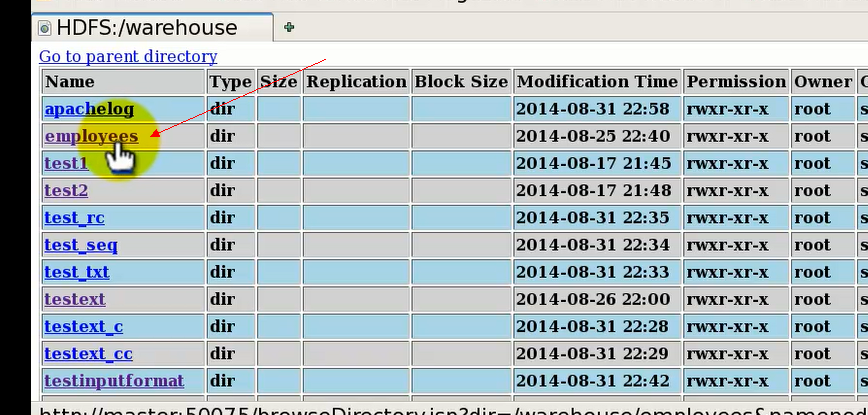
点开该表目录,目前为空,也就是说这是一个空表,并且未分区:
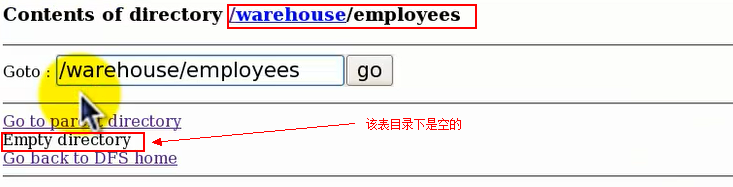
那么现在我们给这个表来添加一个分区:

然后我们在命令行中通过show partitions tablename命令查看分区:

我们再通过web,查看hdfs上这些分区的目录结构:
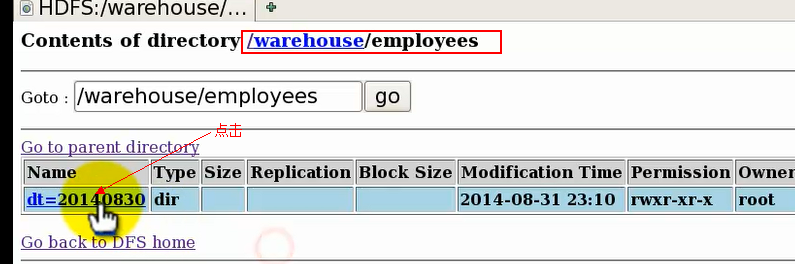
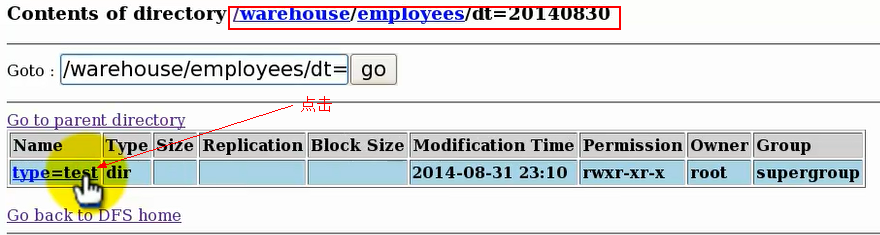
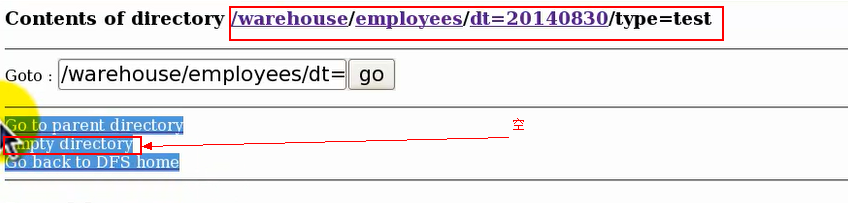
点击表目录进入发现有一个dt目录,然后点dt目录进入,发现有一个type子目录,再点进入,发现type目录为空。
由此看出Hive表的表明对应Hdfs文件结构上的表目录文件夹名,第一个分区字段,对应表目录下的一级子目录文件夹名,第二个分区字段对应二级子目录文件夹名,依次类推。
②我们再添加一个31号的分区:

上面这个创建分区命令的意思是:如果不存在30号的分区那么创建,如果不存在31号的分区,那么也创建,存在的话就不创建了。
创建好后,web上查看hdfs上的目录结构如下:
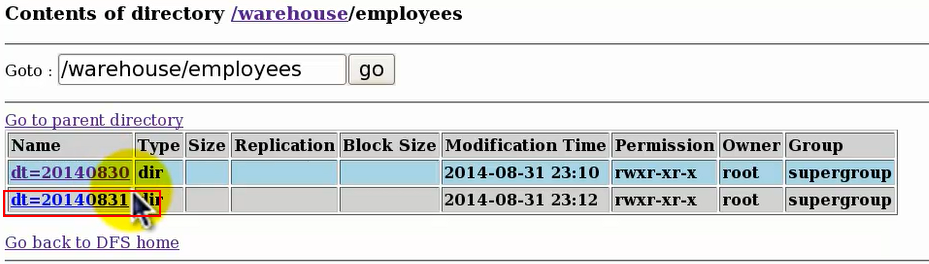
③删除操作也基本一样。
7、Hive分桶:

Hive分桶操作和分区操作的区别和相同之处:
区别:
1、分桶是比分区划分力度更细的一种划分,比如,可以在分区下面进行分桶,按照某些字段进行分桶,那么就可以根据这些字段的 hash值来进行划分桶,
每一个hash值通过计算,然后对应到一个桶里,这样再一个分区目录下面,就会产生很多的桶文件。
2、注意桶是一个文件,不是目录,而分区是目录。
3、分桶可以在表目录下分桶,也可以在分区下分桶。而分区可以在表目录下分,也可以进行多级分区,即:在分区下进行分区,因为分区对应的是目录,
而分桶对应的是文件,所以分桶不能在分桶下面继续分桶。
4、假如在一个表目录下进行分区,分为两个区,然后再到这两个分区下进行分区,那么这两个分区下的子分区个数可以是不一样的,
比如说一个分区下有两个子分区,另外一个分区下只有一个分区;
但对于分桶来说,不管是在哪个分区进行分桶,桶的数据都是一样的,因为桶的数量是在创建表的时候就指定了的,Hive没有分别去指定哪个分区多少个桶的机制;
相同之处:
1、都是为了优化,降低访问的数据量,提高效率。
分桶的基本语法:

Hive分桶默认是不开启的,所有在执行分桶操作的时候,也就是在创建分桶表之前或者创建表后在插入数据之前,需要在hive终端设置开启分桶,这样分桶才有效:
Set hive.enforce.bucketing=true;
实验——演示创建分桶:
①把下面设置了分桶的创建表命令输入hive终端:
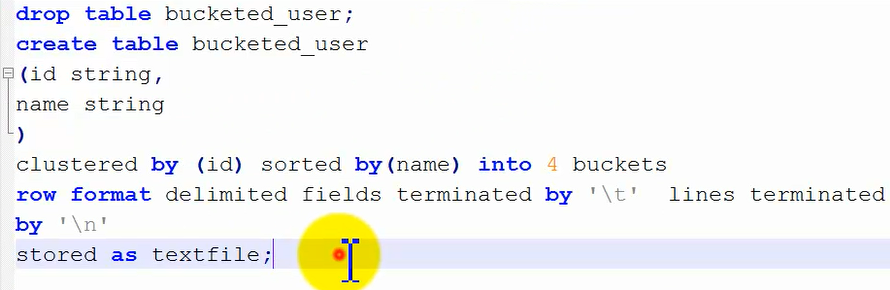
这个时候这个表里面是没有内容的,查看hdfs的目录结构,可以看到在该表目录下面是空,目前还没有数据也就没有桶文件。
②然后我们从其它表里面查询数据然后插入到该表中,注意不要直接进行拷贝数据:

注意:这个命令也是需要执行mapreduce的。
③通过web,查看hdfs上的目录结构变化:
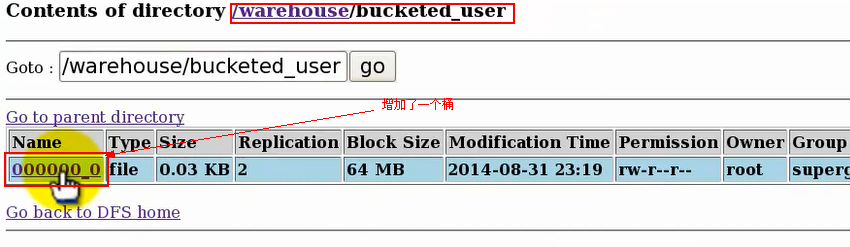
之前我们创建表的时候指定的是4个桶,然后创建后并未生成一个桶文件,这里插入数据后只生成一个桶文件,这是因为我们创建表后未开启hive分桶。
④插入值后,在该桶文件中会存放相应的数据:
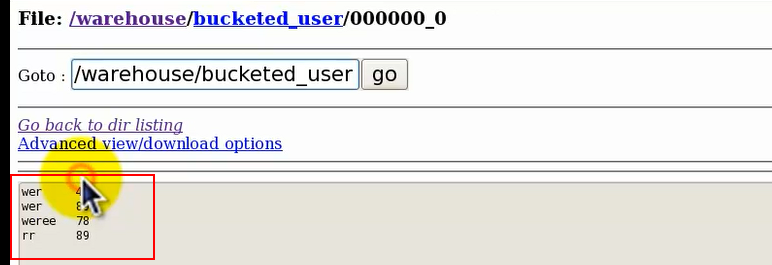
⑤开启hive分桶:

当然这种方式的设置只在该hive终端中有效,关闭后重启hive又会失效。
⑥然后再来执行下插入的语句,注意这里是覆盖插入:

⑦然后再看下hdfs上的目录结构变化:

由上可以看出,此时分桶已经生效了,产生了四个文件,在这里数据都分到了第一个桶里,其余三个桶没有数据,但还是创建出来了。
在查询数据的时候,比如我查id=‘’wer‘’的数据,它会首先对其求hash值,然后模除以桶的个数4,这样就可以定位到具体的桶,然后到该桶文件中去查询数据,这样就保证数据查询的高效。
⑧执行插入语句的时候,注意到的细节:

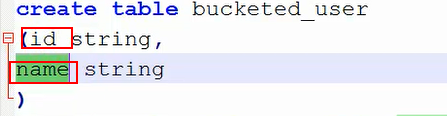
我们注意到在插入数据到表的时候,我们从testext表中查询的字段是name和addr,但我们创建的表bucketed_user中时id和name两个字段,也就是说名字上并不匹配,
那么既然名字上都不匹配,这数据是如何对应插入进来的呢?是按照什么样的对应方式呢?其实hive在这里并没有去检查判断两个的名字是否相同,hive是按照slect查询字段的顺序依次插入到该表的第一列、第二列。。。依次类推。
8、Hive分桶和分区的比较:
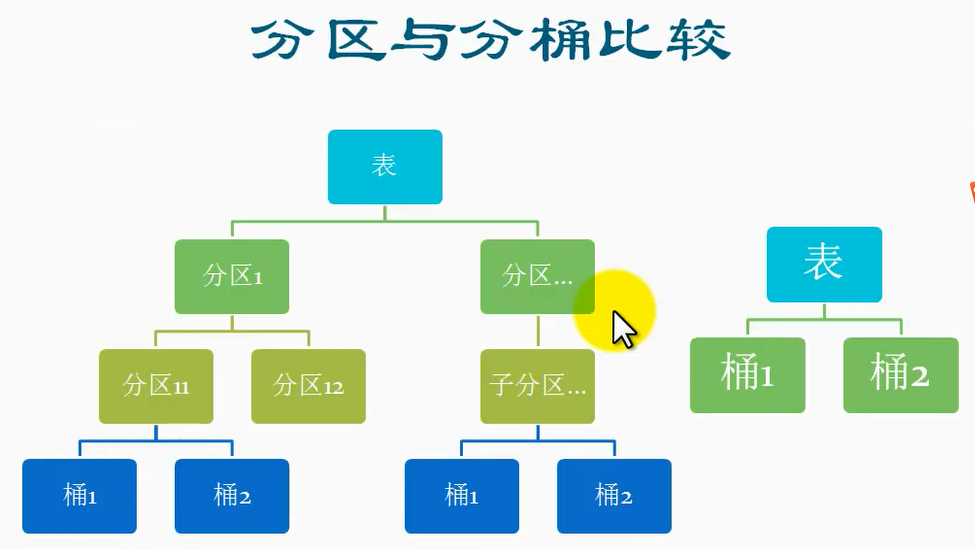
假如在一个表目录下进行分区,分为两个区,然后再到这两个分区下进行分区,那么这两个分区下的子分区个数可以是不一样的,比如说一个分区下有两个子分区,另外一个分区下只有一个分区;但对于分桶来说,不管是在哪个分区进行分桶,桶的数据都是一样的,因为桶的数量是在创建表的时候就指定了的,Hive没有分别去指定哪个分区多少个桶的机制;
9、Hive查询:

总结记忆:
如果不理解参考上面博文相应部分。
1、显示表的创建语句:
show create table tablename;
2、Hive创建表的其它两种方式:
①由一个表创建另外一个表:
Create table test2 like test1;
这种方式只会创建一个字段和test1相同的,但不会把test1的数据插入到test2中。
这种方式相当于复制表结构但不复制数据;
②从其它表查询创建表:
Create table test3 as select name,addr from test4;
这种方式不但会创建对应select后面的字段属性,而且会插入后面select查询出的数据到test3表中。
这种方式相当于复制select查询指定的表字段,同时也复制该查询结果数据。
3、Hive不同文件格式的读取方式:
①对于textfile格式的文件:
可以直接查看hdfs或者用hadoop命令或者用hive的方式查看
②对于序列化格式的文件:
可以通过hadoop命令的方式来查看或者hive的方式查看
③对于列格式的文件:
需要通过hive命令来查看
④自定义的输入流inputformat:
需要通过outformat的自定义输出流来解析查看。
具体的命令参考上面的博文。
4、Hive读写数据的顺序:
①读文件数据过程:
HDFS文件=》inputFileFormat流=》<key,value>=>反序列化Deserializer=>Row对象;
②往文件写数据的过程:
Row对象=》序列化Serializer=》<key,value>=>outputFiLeFormat输出流=》HDFS文件;
5、分区表和内部表和外部表的区别和联系:
分区表相当于是表目录的一个子目录,它和内部/外部表分类的标准就不同,可以说分区表是内部表和外部表的表目录下的子目录。
6、为什么会用到分区(分区表的作用):
分区表是通过创建表时,通过partitioned by 来进行指定按照那个或者那几个字段进行分区,比如说指定时间字段作为分区,
按照一天进行分为一个区,那么每一天的数据会存放在表目录下的一个子文件夹中,这样便于查询某一天的数据(只需要指定某一个分区的名字),而不用扫描整个表,从而提高效率。
7、分区下面还可以创建分区:
分区下面可以继续建分区,也就是说可以有多级的结构。就相当于一个目录下面建了一个子目录,在子目录下面还可以继续建子目录。
8、创建多级分区目录的方法是:
partitioned by(id string,type string) 这样就创建了两级目录,一级分区子目录是按照id进行分区,然后在该分区下再按照type进行分区。
也就是说分区的顺序使按照小括号里面的字段书写顺序来进行创建的。
9、分区表和普通表详细描述信息的不同:
通过desc formatted tabelnam查看表详细的描述信息发现创建的分区表和普通表的区别在于:
分区表多了个分区描述信。
具体参考博文上hive分区表的内容。
10、Hive分区表的操作:
增加分区:
Alter table tablename add if not exists partition(country='xxx',state='yyyy',....);
后面小括号里写的字段是对应的分区级。
删除分区:
Alter table tablename drop if not exists partition(country='xxx',state='yyy',....);
Hive表的表明对应Hdfs文件结构上的表目录文件夹名,第一个分区字段,对应表目录下的一级子目录文件夹名,第二个分区字段对应二级子目录文件夹名,依次类推。
11、Hive分桶操作和分区操作的区别和相同点:
区别:
1、分桶是比分区划分力度更细的一种划分,比如,可以在分区下面进行分桶,按照某些字段进行分桶,那么就可以根据这些字段的 hash值来进行划分桶,
每一个hash值通过计算,然后对应到一个桶里,这样再一个分区目录下面,就会产生很多的桶文件。
2、注意桶是一个文件,不是目录,而分区是目录。
3、分桶可以在表目录下分桶,也可以在分区下分桶。而分区可以在表目录下分,也可以进行多级分区,即:在分区下进行分区,因为分区对应的是目录,
而分桶对应的是文件,所以分桶不能在分桶下面继续分桶。
4、假如在一个表目录下进行分区,分为两个区,然后再到这两个分区下进行分区,那么这两个分区下的子分区个数可以是不一样的,
比如说一个分区下有两个子分区,另外一个分区下只有一个分区;
但对于分桶来说,不管是在哪个分区进行分桶,桶的数据都是一样的,因为桶的数量是在创建表的时候就指定了的,Hive没有分别去指定哪个分区多少个桶的机制;
相同之处:
1、都是为了优化,降低访问的数据量,提高效率。
12、hive插入数据到分桶的表的时候,不是按照名字进行对应插入的,而是按照slect查询字段的顺序,将这些字段数据依次插入到该表的第一列、第二列。。。依次类推:
insert overwrite table bucketed_user select addr,name from testext;
13、不涉及mapreduce的查询操作:
①select * from 表名;
②select * from 表名 limit 多少行;
③slect * 查询某个区;
另外再说下,下面创建表的方式也不涉及mapreduce,因为没有涉及到任何数据的拷贝:
Create table test2 like test1;