什么是集群?
集群是一组(>2)相互独立的,通过高速网络互联的计算机组成的集合。群集一般可以分为科学集群,负载均衡集群,高可用性集群三大类。
科学集群是并行计算的基础。它对外就好象一个超级计算机,这种计算机内部由十至上万个独立处理器组成,并且在公共消息传递层上进行通信以运行并发应用程序,像中国的银河,曙光超级计算机。
高可用性集群,当集群中的一个系统发生故障时,集群软件迅速作出反应,将该系统的任务分配至集群中其它正在工作的系统上执行,通过消除单一故障点和节点故障转移功能来提供高可用性,次节点通常是主节点的镜像。
负责均衡集群将服务请求分摊处理到集群中的多个节点上。如软件型LVS,硬件型F5。
在实际生产环境中,这三种集群相互交融,如高可用性集群也可以在节点之间均衡用户负载。
什么是RHCS?
RHCS即REDHAT CLUSTER SUITE,中文意思即红帽集群套件。它是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足你的对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。
RED HAT公司在2007年发布RHEL5时,就将原本作为独立软件发售的用于构建企业级集群的集群套件redhat cluster suite(RHCS)集成到了操作系统中一同发布。
RHCS提供如下两种不同类型的集群:
1、应用/服务故障切换----通过创建N个节点的服务器集群来实现关键应用和服务的故障切换
2、IP负载均衡----对一群服务器上收到的IP网络请求进行负载均衡
RHCS技术要点:
1、最多支持128个节点(红帽3和4支持16个节点)
2、可同时为多个应用提供高可用性
3、NFS/CIFS故障切换:支持UNIX和WINDOWS环境下使用的高可用性文件
4、完全共享的存储子系统:所有集群成员都可以访问同一个存储子系统
5、综合数据完整性:使用最新的I/O屏障(barrier)技术,如可编辑的嵌入式和外部电源开关装置(power switches)。
6、服务故障切换:它可以确保及时发现硬件停止运行或故障的发生并自动恢复系统,同时,它还可以通过监控应用来确保应用的正确运行并在其发生故障时进行自动重启。
RHCS组件说明:
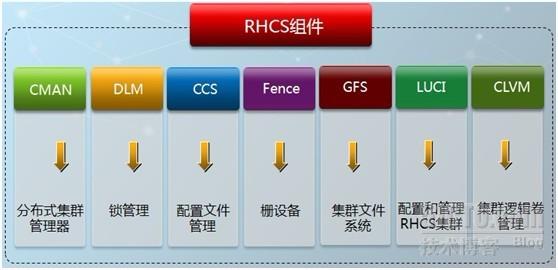
分布式集群管理器(cman)
Cluster manager 简称CMAN,是一个分布式集群管理工具,运行在集群的各个节点上,为RHCS提供集群管理任务。
它用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的有关系。当集群中某个节点出现故障时,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。
CMAN根据每个节点的运行状态,统计出一个法定节点数,作为集群是否存活的依据。当整个集群中有多于一半的节点处于激活状态时,表示达到了法定节点数,
此集群可以正常运行,当集群中有一半或少于一半的节点处于激活状态时,表示没有达到法定的节点数,此时整个集群系统将变得不可用。
CMAN依赖于CCS,并且CMAN通过CCS读取cluster.conf文件。
锁管理(DLM)
Distributed Lock
Manager,简称DLM,是一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制。DLM运行在每个节点
上,GFS通过锁管理器的机制来同步访问文件系统的元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。
DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大提高了处理性能。同时,DLM避免了单个节点失败需要整体恢复的性能瓶颈。另外,DLM的请求是本地的,不需要网络请求,因此请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。
配置文件管理(CCS)
Cluster configuration system
简称CCS,主要用于集群配置文件管理和配置文件在节点之间的同步。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc
/cluster/cluster.conf的状态。当这个文件发生任何变化
时,都将些变化更新至集群中的每个节点上,时刻保持每个节点的配置文件同步。
Cluster.conf是一个XML文件,其中包含集群名称,集群节点信息,集群资源和服务信息,fence设备等。
栅设备(Fence)
通过栅设备可以从集群共享存储中断开一个节点,切断I/O以保证数据的完整性。当CMAN确定一个节点失败后,它在集群结构中通告这个失败的节
点,fenced进程将失败的节点隔离,以保证失败节点不破坏共享数据。它可以避免因出现不可预知的情况而造成的“脑裂”(split-brain)现
象。“脑裂”是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地
址)进行争用,抢夺。
Fence的工作原理是:当意外原因导致主机异常或宕机时,备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
RHCS的Fence设备可以分为两种:内部Fence和外部Fence。内部fence有IBM RSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SAN switch ,Network switch等。
栅设备实例
当节点A上的栅过程发现C节点失效时,它通过栅代理通知光纤通道交换机将C节点隔离,从而释放占用的共享存储。
当A上的栅过程发现C节点失效时,它通过栅代理直接对服务器做电源power on/off,而不是去执行操作系统的开关机指令。
rgmanager管理
它主要用来监督、启动、停止集群的应用、服务和资源。当一个节点的服务失败时,高可用集群服务管理进程可以将服务从这个失败节点转移至其点健康节点上,这种服务转移能力是自动动,透明的。
RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
在RHCS集群中,高可用生服务包括集群服务和集群资源两个方面。集群服务其实就是应用,如APACHE,MYSQL等。集群资源有IP地址,脚本,EXT3/GFS文件系统等。
在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的。由几个节点负责一个特定的服务的集合叫失败转移域,在失败迁移域中可以设置节点的优先级,主节点失效,服务会迁移至次节点,如果没有设置优先,集群高可用服务将在任意节点间转移。
说了这么多,初学者可能还是不明白RHCS组件之间的关系,所以整个图给大家作感性认识一下,RHCS组件可以归到以下图示中:
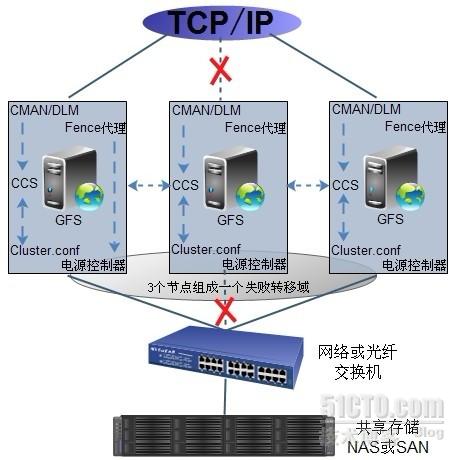
集群配置和管理工具
RHCS提供了多种集群配置和管理工具,常用有基于GUI的system-config-cluster,conga等,还提供了基于命令行的管理工具。
System-config-cluster由集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态,一般用于早期的RHCS版本中。
Conga是新的基于网络的集群配置工具。它是web界面管理的,由luci和ricci组成,luci可以安装在一台独立的计算机上,也可安装在节点
上,用于配置和管理集群,ricci是一个代理,安装在每个集群节点上,luci通过ricci和集群中的每个节点通信。
GFS是RHCS为集群系统提供的一个存储解决方案,它允许集群的多个节点在块级别上共享 存储,多个节点同时挂载一个文件系统分区,而使文件系统数据不受破坏,单一的ext2或ext3无法做到。
为了实现多个节点对一个文件系统同时进行读写操作,GFS使用锁管理器(DLM)来管理I/O操作:当一个写进程操作一个文件时,此文件被锁定,其它进程无法进行读写操作,操作完成后,RHCS底层机制会把此操作在其它节点上可见。
有GFS就有RHCS,但建立RHCS时,如果不用共享存储,就没有必要用GFS。
资源(Resource)
脚本(script),IP Address,File system可以用来定义一个高可用的web服务功能
实例操作(不带共享存储)
红帽建议做RHCS集群,一般要三台服务器以上,含三台,其中一台作LUCI,这里作实验因为用的是虚拟环境,加上PC机性能差,所以只用到二台。

修改各节点的/etc/hosts文件
注意格式要一致,特别是127.0.0.1行,默认的不合rhcs集群要求,必须改,否则在用luci建立集群时会报错。

在节点1上安装luci软件
[root@rhcs1 ~]# yum install luci*
Luci初始化及重启
在所有集群节点上(rhcs1,rhcs2)安装RHCS软件
[root@rhcs1 ~]# yum install cman
[root@rhcs1 ~]# yum install ricci
[root@rhcs1 ~]# yum install rgmanager
其它ricci,rgmanager不截图了
安装完所有RHCS组件后,重启所有节点,并启动ricci,luci服务,rhcs1节点需要启动luci,rhcs2不需要,服务启动完毕后,查看rhcs1节点的11111端口,8084端口有没有在监听,rhcs2节点的11111端口有没有在监听。
[root@rhcs1 ~]# /etc/init.d/ricci start
[root@rhcs1 ~]# /etc/init.d/luci start
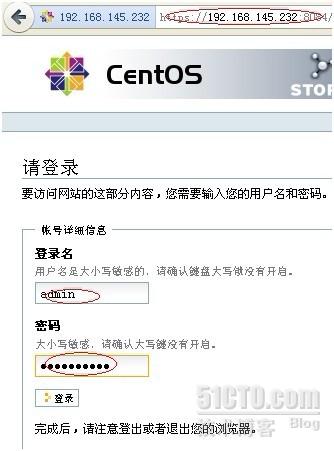
Web登录luci进行集群设置
在客户机上,打开浏览器,这里我用火狐,输入https://192.168.145.232:8084,输入初始化时设置的密码,进行web登录。
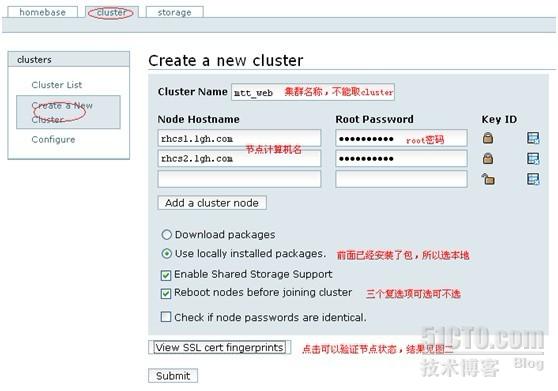
新建cluster
设置集群名称,节点信息,然后点submit按钮


火狐浏览器中,显示这个进度有问题,总是初始化,正常情况下,如果install完毕后,空心圆点会变实心圆点,然后接下是reboot阶
段,configure阶段,join阶段,因为我在建集群时选择了reboot所以,集群建完后,所有节点会自动重启。重启后,要确保
luci,ricci服务有没有起来。
建立mtt_web后情况
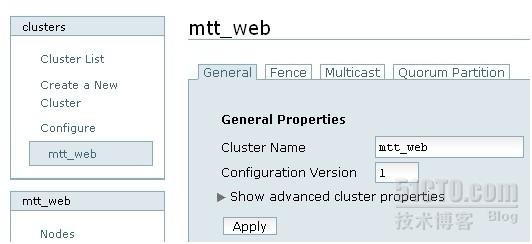
点cluster list,查看一下刚创建的集群状态是否正常,从图上看,集群显示绿色,表示正常。

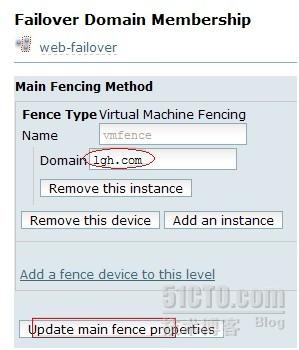
新建一个失败转移域
点击mtt_web,进去一个新界面,然后在左边窗中选failover domains下的add a failover
domain,根据选项填写转移域名,这里我们取web-failover,在此界面中,可以设置转移域中的优先级,从图上所示,rhcs1节点的优先级
为1,rhcs2节点的优先级为10,数值越大,优先级越低,在生产环境中也可以把优先级设置为一样,谁先启动服务,谁就是主节点。

创建必要的web资源
创建一些web服务所需要的资源,IP地址,脚本,这里的虚拟IP或叫公用IP,我们设置为192.168.145.235,这个IP要确保不能被其它服务器占用了。
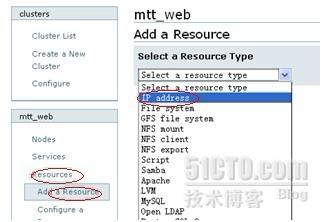

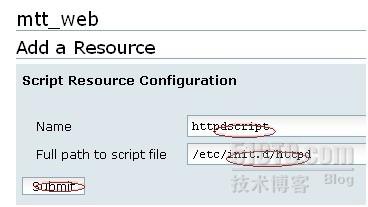
创建一个脚本资源,这个脚本文件其实是一个shell程序,因为本次的httpd是通过yum安装的所以系统会把apache的启动脚本放在/etc
/init.d/httpd目录下,如果是源码包安装的,就需要自己编写apache的启动脚本,该脚本里要包括start,stop等字段。
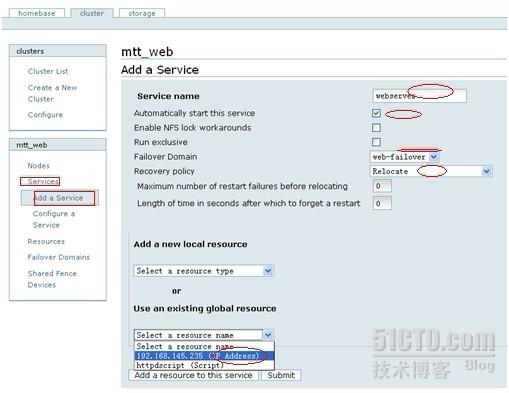
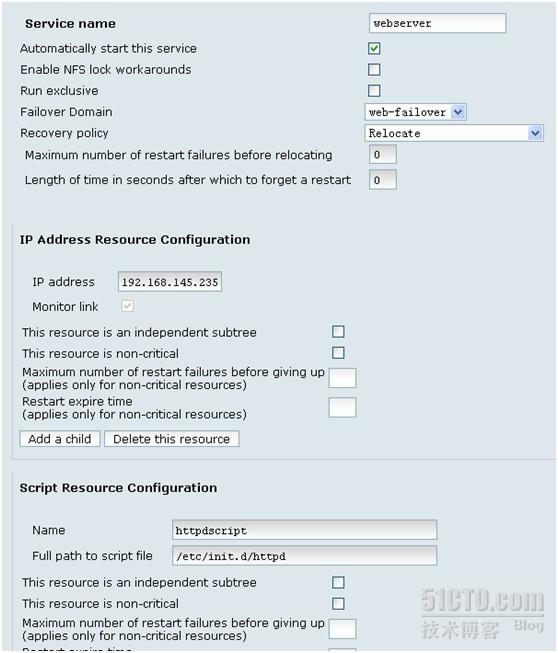
新建service
这里的service,并不指apache服务,或mysql服务,这里指整个集群的资源全部组成一个服务,所以这里先定义一个service,然后选择上面定义好的策略,如失败转移域,转移策略,所用的公共IP及脚本资源。
新建fence设备
上面已讲到fence设备是防止脑裂现象出现,所以我们在此集群中,再增加一个fence设备,因为我们用的是虚拟机,所以就添加虚拟设备的选项,实际生产环境中,根据条件定fence设备。
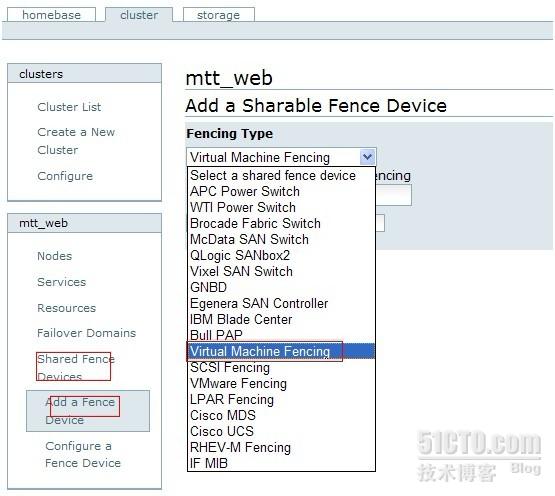


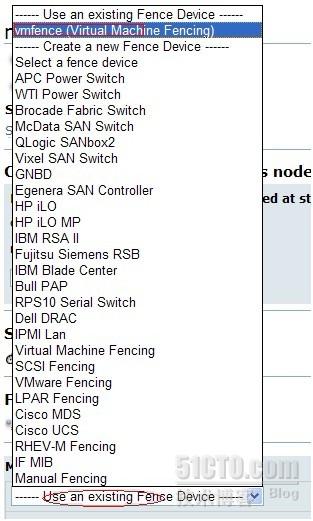
这样下来,集群的环境都搭建好了,完整的配置文件见/etc/cluster/cluster.conf文件
在所有节点上安装http服务
Shell>[root@rhcs1 ~]# yum install httpd
在rhcs1节点上的/var/www/html目录,新建index.html,内容如下:
- <html>
- <body>
- kkkk this is 145.232
- </body>
- </html>
在rhcs2节点上的/var/www/html目录,新建index.html,内容如下:
- <html>
- <body>
- kkkk this is 145.233
- </body>
- </html>
启动RHCS集群
先在所有节点是启动cman
Shell>service cman start
如果cman启动没有报错,再在所有节点是启动rgmanager,集群管理器
Shell>service rgmanager start
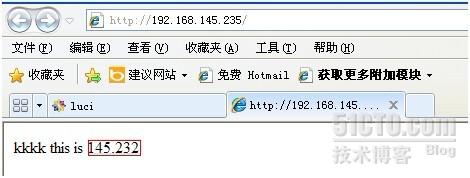
通过浏览器访问一下,集群
http://192.168.145.235
在rhcs1节点上,把httpd关闭
Shell>pkill -9 httpd
再通过客户端计算机访问145.235,建立先关闭刚打开的页面,新开一个页面,再输入IP地址,发现,页面显示为145.233。
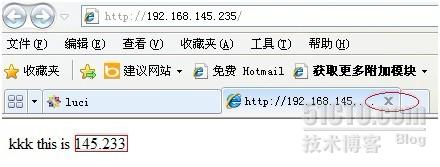
同样,在rhcs2节点上把httpd关闭,不到一分钟,再到访问,网页结果又显示为145.232了。
这里我用两个不同的index.html来显示内容,是为了好区别集群有没有作故障转移,在实际环境里,所有节点都是一样的,即次节点是主节点的镜像。
后记:
生产环境中,很多情况下,集群都会挂共享存储,一般为SAN或DAS,所以在以上基础上,还要加GFS文件系统,配置表决磁盘,具体可看附件中redhat官方手册
本文出自 “系统网络运维” 博客,请务必保留此出处http://369369.blog.51cto.com/319630/836001