1.a = pandas.read_csv(filepath):读取.csv格式的文件到列表a中,文件在路径filepath中
pandas.core.frame.DataFrame是pandas的核心结构
b = a.head(n):b中存有文件前n行,默认为5行
b = a.tail(n):b中存有文件后n行,默认为5行
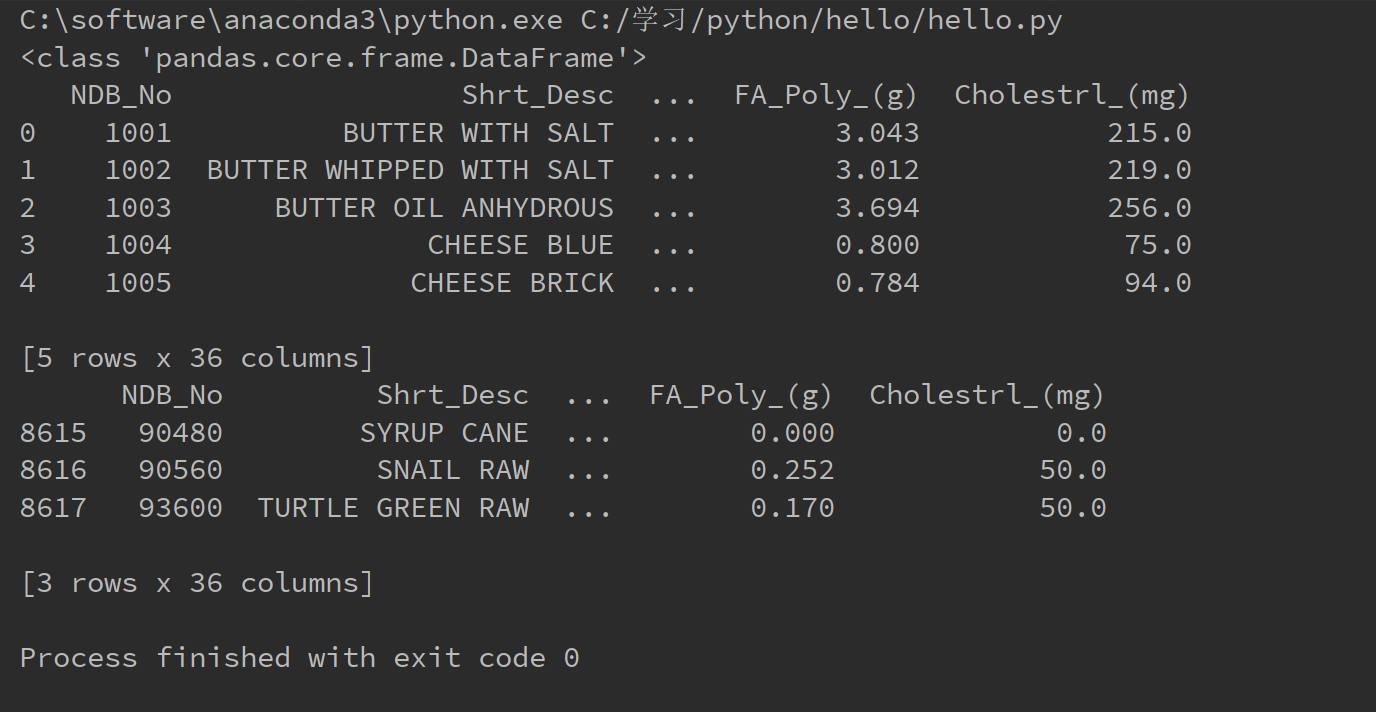
1 import pandas as pd 2 3 food_info = pd.read_csv("C:/Users/娄斌/Desktop/.ipynb_checkpoints/food_info.csv") 4 print(type(food_info)) 5 a = food_info.head() 6 b = food_info.tail(3) 7 print(a) 8 print(b)
2.pandas索引与计算。
设a为DataFram类型。
- a.loc[n]表示提取a的第 n行;a.loc[n:m]表示提取a的n到m行,当然,还可以用列表作为索引。
- a['name']表示提取列名为"name"的列。
- 加减乘除和numpy的向量一样。
- a.columns.tolist()将所有的列名存储在一个向量中
- a['name'].max()可以取出该列的最大值。
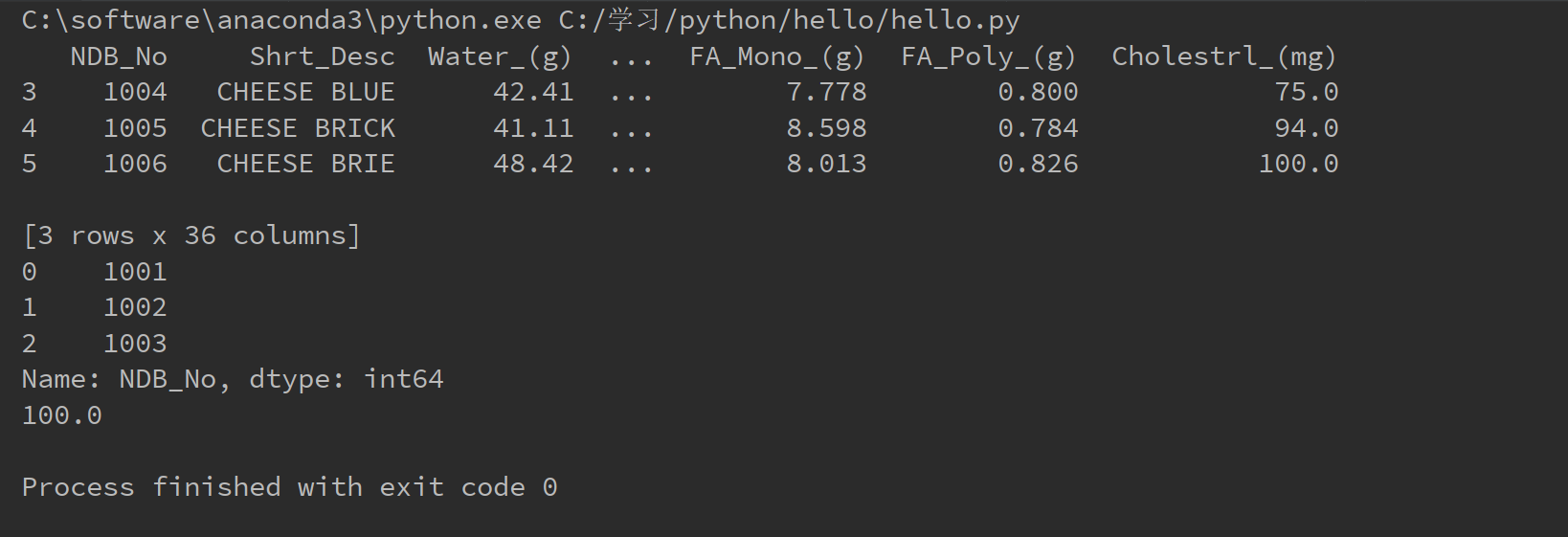
1 import pandas as pd 2 3 food_info = pd.read_csv("C:/Users/娄斌/Desktop/.ipynb_checkpoints/food_info.csv") 4 print(food_info.loc[3:5]) 5 print(food_info["NDB_No"].head(3)) 6 print(food_info["Water_(g)"].max())
运行结果如下
下面的代码是将所有的单位是g的列找出来,并转化为mg,然后求和并加入a中。
1 import pandas as pd 2 3 food_info = pd.read_csv("C:/Users/娄斌/Desktop/.ipynb_checkpoints/food_info.csv") 4 columns = food_info.columns.tolist() 5 gram_c = [] 6 for c in columns: 7 if c.endswith("(g)"): 8 gram_c.append(c) 9 print(food_info[gram_c].head(3)) 10 food_info[gram_c] = food_info[gram_c]/1000 11 print(food_info[gram_c].head(3)) 12 13 food_info["sum(mg)"] = 0 14 for c in gram_c: 15 food_info["sum(mg)"] += food_info[c] 16 print(food_info.head(3))

3.pandas排序和titanic数据集
sor_value()函数进行排序,当参数inplace = false时,原数据集不变,当inplace = true时,原数据集变成排序后的结果。
下面的代码是读取titanic_train.csv的数据并按照标签“fare"进行排序,然后读取所有年龄为空的记录,并统计该记录集的长度。
1 import pandas as pd 2 3 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 4 print(titanic.head(5)) 5 titanic.sort_values("Fare", inplace=True) 6 print(titanic.head(5)) 7 8 #将所有年龄为空的记录显示出来并统计个数 9 age = titanic['Age'] 10 age_is_null_judge = pd.isnull(age) 11 age_is_null = age[age_is_null_judge] 12 print(age_is_null) 13 print(len(age_is_null))
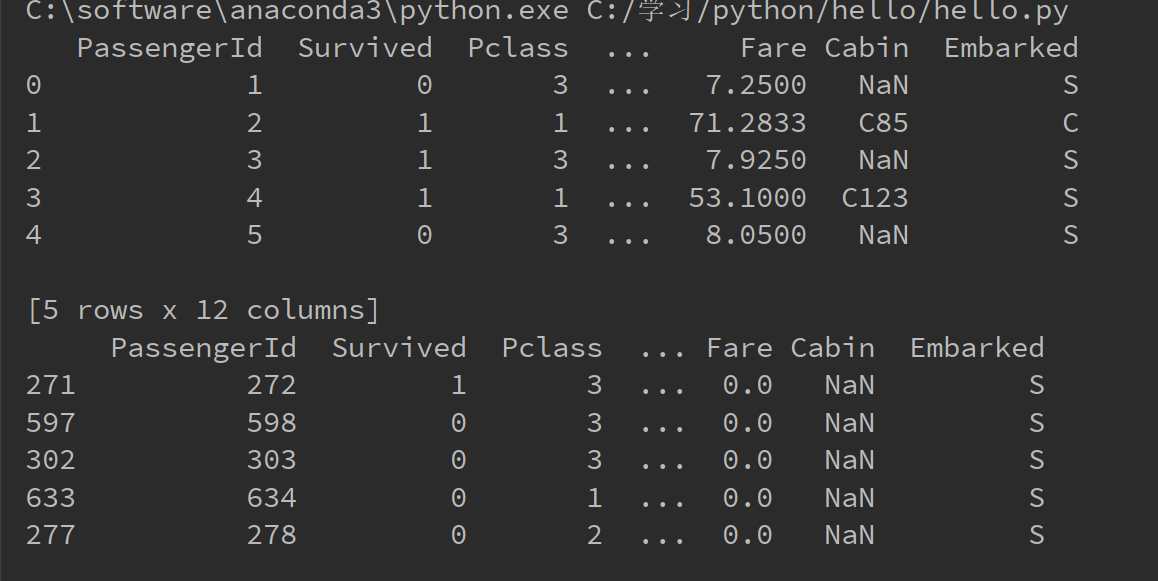
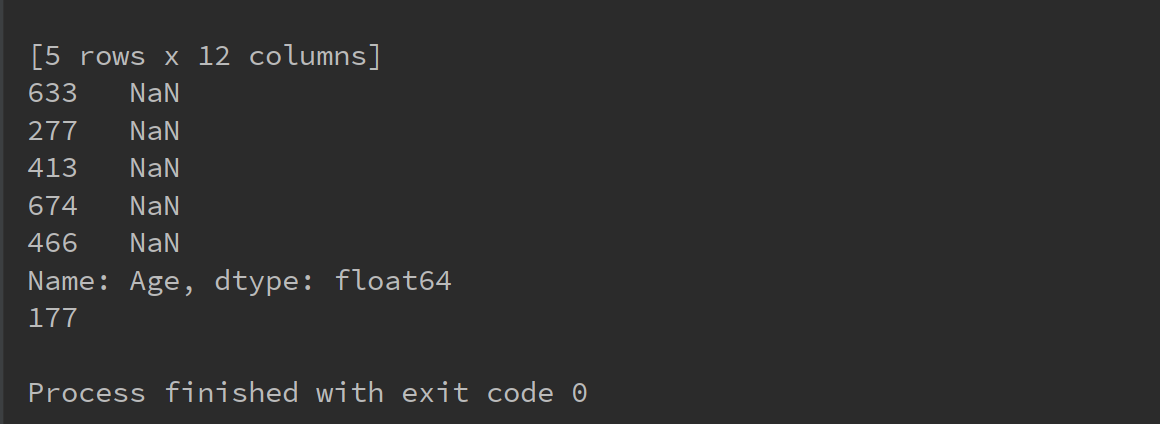
4.数据预处理方法
计算某一个属性的平均值,下面代码是计算数据集中age属性平均值
1 import pandas as pd 2 3 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 4 age = titanic['Age'] 5 age_is_null_judge = pd.isnull(age) #isnull函数判断函数的age是否为NaN,如果是则为true,否则为false 6 new_age = titanic['Age'][age_is_null_judge == False] #注意俩个中括号,一个是属性,一个是判断 7 mean = sum(new_age) / len(new_age) #sun函数和len函数 8 print(mean)
还可以用dropna函数去掉属性为空的记录
1 import pandas as pd 2 3 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 4 age = titanic['Age'] 5 6 new_titanic = titanic.dropna(axis=0, subset=['Age']) #subset是一个列表,可以有多个属性 7 new_age = new_titanic['Age'] 8 print(sum(new_age)/len(new_age))
以上两段代码的运行结果都是
29.69911764705882
下面这几行代码可以访问DataFram中的某行某列的元素
1 titanic = pd.reavd_csv("C:/学习/python/hello/titanic_train.csv") 2 print(titanic.loc[24, 'Age'])
可以用pivot_table(index='Pclass', values='Age', aggfunc=np.mean)对数据进行分类统计,例如这里的参数index说明该函数先将所有的记录按照Pclass的不同进行分类,
参数value = ‘Age'说明对于每一类的记录,统计其属性Age, aggfunc = np.mean参数说明对Age属性求平均值。
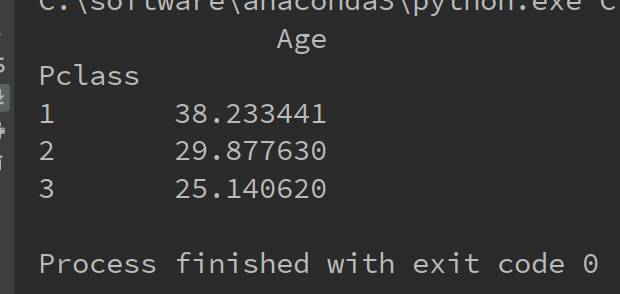
下面的代码就是分别统计1,2,3等舱的乘客的平均年龄
1 import pandas as pd 2 import numpy as np 3 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 4 mean_age = titanic.pivot_table(index='Pclass', values='Age', aggfunc=np.mean) 5 print(mean_age)
运行结果如下
利用panddas的sort_value函数可以实现排序,但是排序好的记录的索引值还是原来的索引,即样本不再是从第0行到第n行了,如下图所示

现在要把索引变成从0到1,只需要利用reset_index()函数
1 import pandas as pd 2 import numpy as np 3 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 4 new_titanic = titanic.sort_values('Age') 5 new_titanic1 = new_titanic.reset_index() 6 print(new_titanic.head(5)) 7 print(new_titanic1.head(5))
运行结果如下

可以用apply(func, axis)函数实现自定义函数,其中第一个参数func是自定义的函数,第二个参数axis=0表示func函数逐列处理数据,axis=1表示逐行处理函数
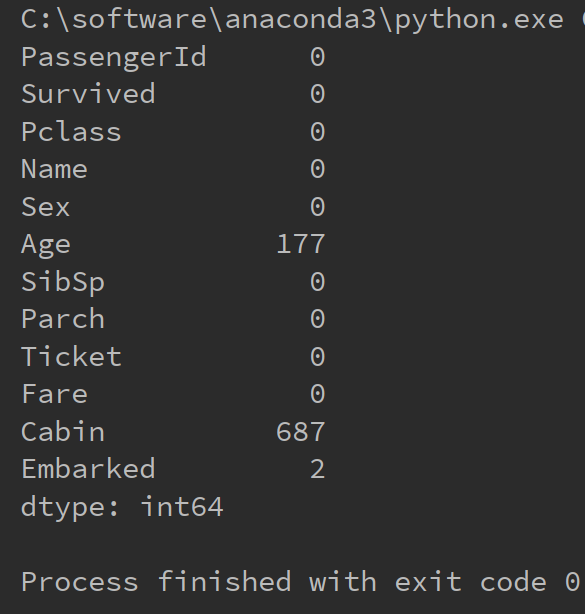
如下代码统计每一列的空值个数
1 import pandas as pd 2 import numpy as np 3 4 #统计每个属性的空值个数 5 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 6 7 8 def nul_count(column): 9 is_null_judge = pd.isnull(column) 10 is_null = column[is_null_judge] 11 return len(is_null) 12 13 14 column_null_count = titanic.apply(nul_count, axis=0) 15 print(column_null_count)
运行结果如下
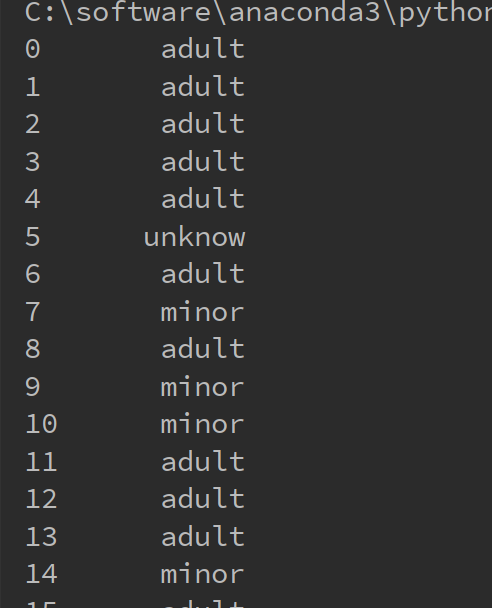
以下的代码将年龄离散化成成年人和未成年人
1 import pandas as pd 2 import numpy as np 3 4 #统计每个属性的空值个数 5 titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") 6 7 8 def generate_age_label(row): 9 age = row['Age'] 10 if pd.isnull(age): 11 return "unknow" 12 elif age < 18: 13 return "minor" 14 else: 15 return "adult" 16 17 18 age_labels = titanic.apply(generate_age_label, axis=1) 19 print(age_labels)
运行结果如下
5.series结构
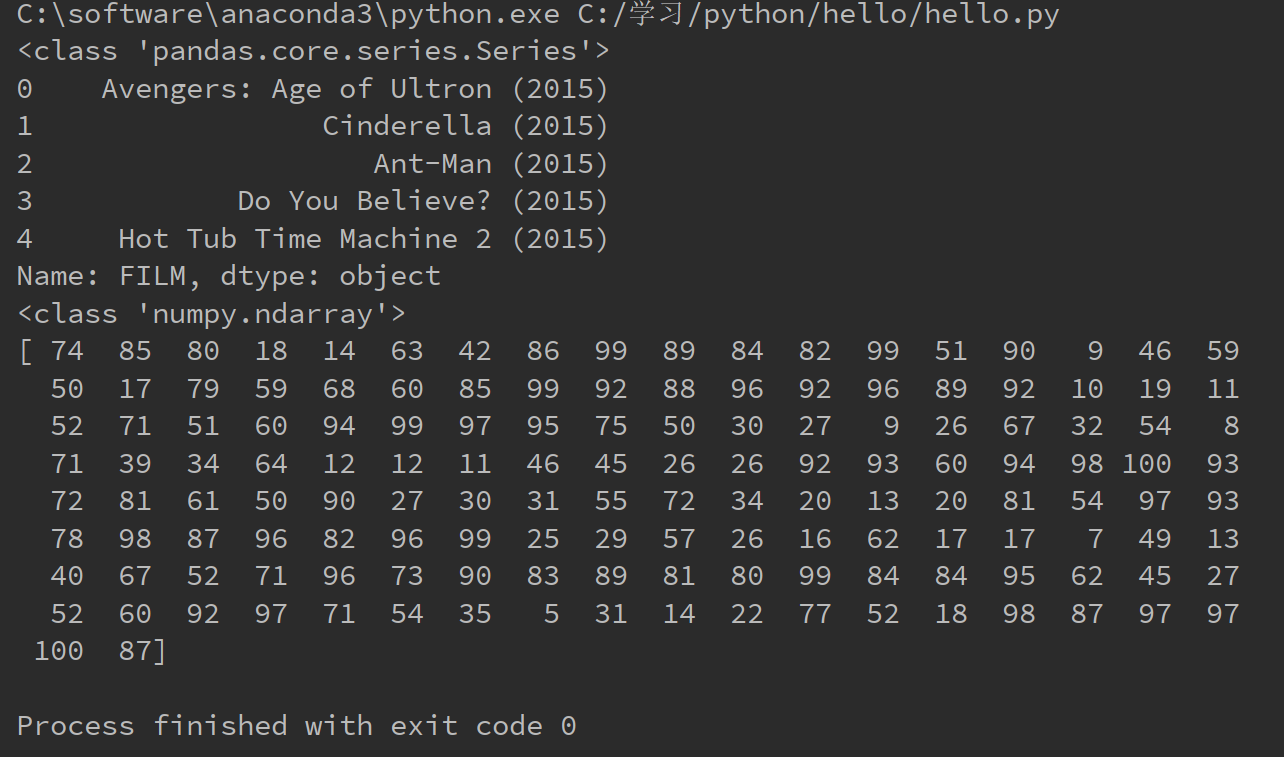
设a是DataFram结构,b为a的某一行或者某一列,那么b为Series结构。 c = b.values,那么c为numpy的ndarray结构。如下代码所示
1 import pandas as pd 2 import numpy as np 3 4 fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 5 series_film = fandango["FILM"] 6 series_rt = fandango["RottenTomatoes"] 7 print(type(series_film)) 8 print(series_film.head(5)) 9 film_name = series_film.values 10 rt_scores = series_rt.values 11 print(type(rt_scores)) 12 print(rt_scores)
下面是运行结果
通过pandas.Series(value, index)函数可以将两个ndarray类型的值组合成一个Series类型,这里index是索引,value是值,如下代码 所示,将电影名和其RontenTomatoes的评分对应起来
1 import pandas as pd 2 import numpy as np 3 4 fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 5 series_film = fandango["FILM"] 6 series_rt = fandango["RottenTomatoes"] 7 8 film_name = series_film.values 9 rt_scores = series_rt.values 10 11 series_custom = pd.Series(rt_scores, index=film_name) 12 print(type(series_custom)) 13 print(series_custom)
运行结果如下

可以用Series结构按索引排序构造新的Series。如下代码所示
1 import pandas as pd 2 import numpy as np 3 4 fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 5 series_film = fandango["FILM"] 6 series_rt = fandango["RottenTomatoes"] 7 8 film_name = series_film.values 9 rt_scores = series_rt.values 10 11 series_custom = pd.Series(rt_scores, index=film_name) 12 13 #对电影名进行排序 14 origial_index = series_custom.index.tolist() #origial_index是list类型 15 sorted_index = sorted(origial_index) 16 new_series_custom = series_custom.reindex(sorted_index) 17 print(new_series_custom)
运行结果如下

以下代码实现将数据表fandango中类型为float64的列保留下来构成新表
1 import pandas as pd 2 import numpy as np 3 4 fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 5 types = fandango.dtypes #Series结构,索引是列名,值是该列的数据类型 6 7 float_column = types[types.values == 'float64'].index #将类型为float64的列名找出来 8 print(type(float_column)) 9 print(float_column) 10 float_df = fandango[float_column] 11 print(float_df.head(5))
运行结果如下
设fandango是Datafram结构,则fandango.columns的数据类型是index,fandango.columns.values的数据类型是ndarray,fandango.columns.values.tolist()的数据类型是list。这个数据类型
关系很重要。还有Datafram的某一行或者某一列为Series结构,Series的values属性是ndarray类型,ndarray结构调用tolist()成为list类型
1 import pandas as pd 2 import numpy as np 3 4 fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 5 columns = fandango.columns 6 columns_values = columns.values 7 columns_value_list = columns_values.tolist() 8 print(type(columns)) 9 print(columns) 10 print(type(columns_values)) 11 print(columns_values) 12 print(type(columns_value_list)) 13 print(columns_value_list)
运行结果如下
以下代码实现对每个电影的所有评价求方差,并打印出来
1 import pandas as pd 2 import numpy as np 3 4 fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 5 columns = fandango.columns #所有的属性名,index类型 6 columns_values = columns.values #所有的属性名,ndarray类型 7 new_fandango = fandango[columns_values[columns_values != 'FILM']] #去掉电影名这一列才能对剩下的列求方差 8 result = new_fandango.apply(lambda x: np.std(x), axis=1) #自定义函数求方差,axis=1表示按行处理,这里的x是Series类型 9 film_name = fandango['FILM'] #Series类型的电影名 10 result_std = pd.Series(data=result.values, index=film_name.values) 11 print(result_std)
运行结果如下,记住numpy的std函数是可以传入Series类型的参数的,不过要求值全部为数值类型。
6.values属性将表格矩阵化
设a是datafram类型的数据集,则b = a.values执行后,b是一个矩阵,ndrray类型。