1. 安装IDEA和scala
IDEA 可以去官网下载
scala插件 https://plugins.jetbrains.com/plugin/1347-scala
要注意IDEA需要对应的jdk版本
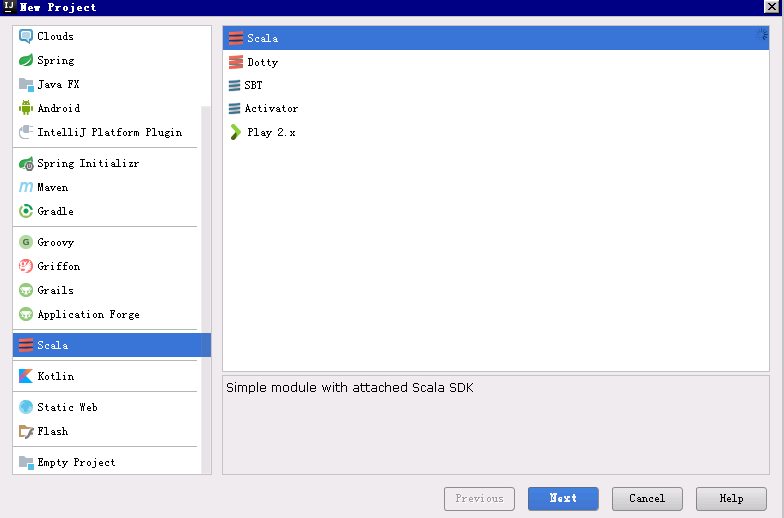
2. 新建scala项目
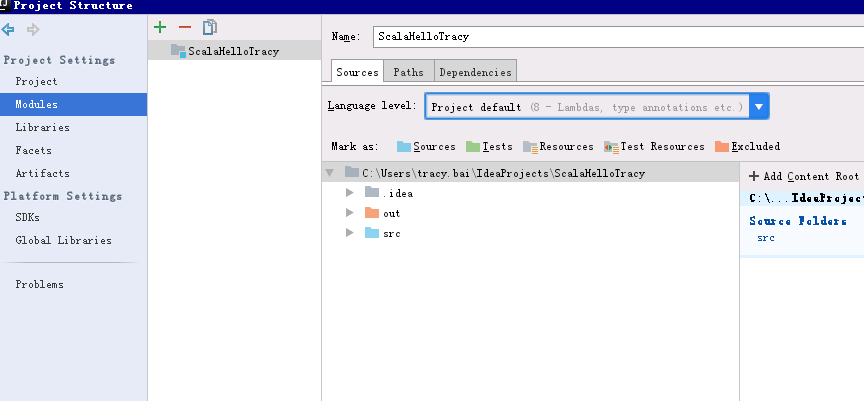
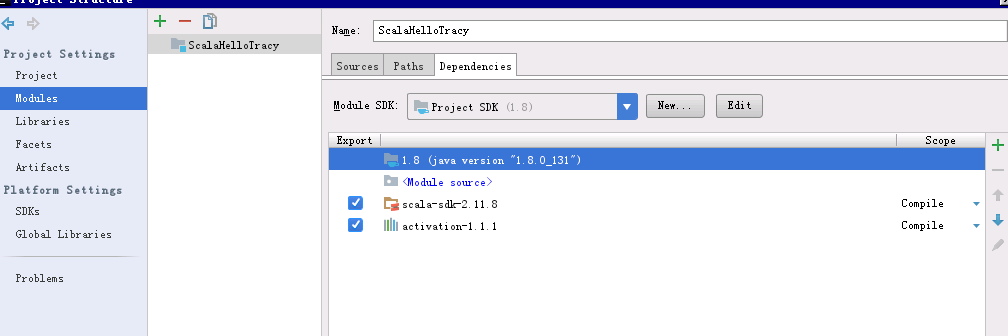
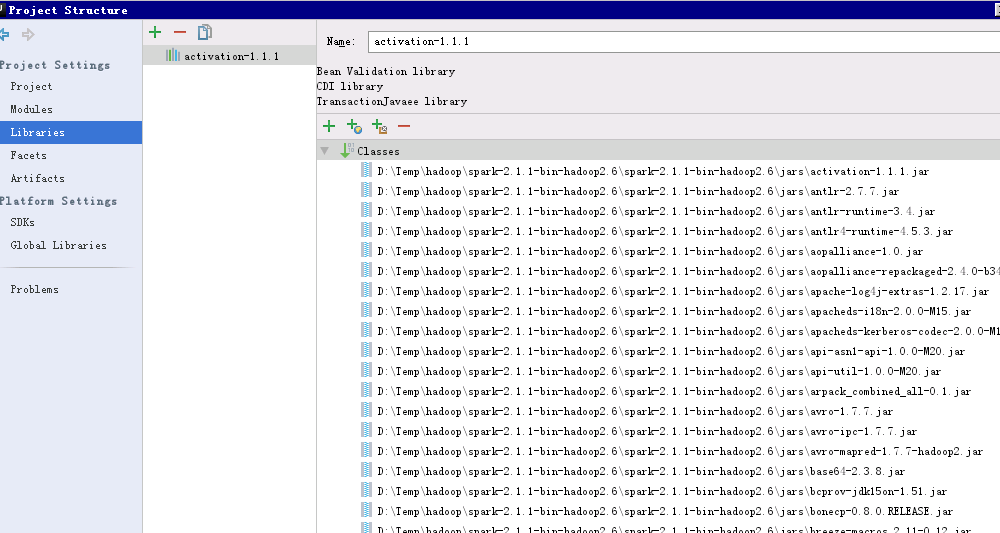
3.配置项目结构和dependencies,要在libraries里加入spark
4. 运行hello workd测试项目是否可以
object HelloWorld3 {
def main(args: Array[String]) {
println("Hello World")
}
}
5. 新建sparkdemo,测试
//System.setProperty("HADOOP_USER_NAME", "hadoop01");
/*val logFile = "hdfs://10.10.0.141:9000/user/hadoop01/mapreduce/wordcount/input/wc.input" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val rdd=sc.textFile(logFile)
val wordcount=rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
wordcount.saveAsTextFile("hdfs://10.10.0.141:9000/user/hadoop01/mapreduce/wordcount/sparkoutput4");
sc.stop()
最后在hdfs里查看运行结果
bin/hdfs dfs -text /user/hadoop01/mapreduce/wordcount/sparkoutput3/part*