一 . SQLAlchemy 基本使用 单表 一对多表 多对多表 数据库连接方方式(多线程)原生sql
https://www.cnblogs.com/wupeiqi/articles/8259356.html
1.SQLAlchemy 介绍
pip3 install sqlalchemy
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,
简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
Engine,框架的引擎 Connection Pooling ,数据库连接池 Dialect,选择连接数据库的DB API种类 Schema/Types,架构和类型 SQL Exprression Language,SQL表达式语言
2. SQLAlchemy 使用单表常用操作
models.py
import datetime from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index Base = declarative_base() # https://www.cnblogs.com/wupeiqi/articles/8259356.html class Users(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) dep_id=Column(Integer, index=True) def create_all(): """ 根据类创建数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb2?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) def drop_all(): """ 根据类删除数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb2?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) if __name__ == '__main__': create_all() # drop_all()
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Users engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb2?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查 session = SessionFactory() # ======================增============================= # # 单条数据 obj=Users(name="张三") session.add(obj) session.commit() # 多条数据 session.add_all([ Users(name="张里"), Users(name="马上") ]) session.commit() # ======================查============================= # for集合查询 aa=session.query(Users).all() for row in aa: print(row.name,row.id) # # 条件查询 bb=session.query(Users).filter(Users.id>=3) for roe in bb: print(roe.name) # # 条件查询 res=session.query(Users).filter(Users.id>=2).first() print(res) # ======================删============================= session.query(Users).filter(Users.id>2).delete() session.commit() # ======================改============================= session.query(Users).filter(Users.id==1).update({Users.name:"哈哈哈哈"}) session.query(Users).filter(Users.id==2).update({"name":"哈哈哈哈哈哈哈哈哈哈企鹅恶趣味去"}) session.query(Users).filter(Users.id == 4).update({'name':Users.name+"DSB"},synchronize_session=False) # 在原来的数据上进行追加 session.commit() # ======================其他常用============================= # 1. 指定列 select id,name as cname from users; result = session.query(Users.id,Users.name.label('cname')).all() for item in result: print(item,item.id,item.cname) aa=session.query(Users.id,Users.name.label('cname')) print(aa) 查看sql语句 # 2. 默认条件and aa=session.query(Users).filter(Users.id > 1, Users.name == '李四').all() for i in aa: print(i.name) # 3. between 在什么之间 aa=session.query(Users).filter(Users.id.between(4, 7), Users.name == '李四').all() for i in aa: print(i.name) # in 包含 aa=session.query(Users).filter(Users.id.in_([1,5,2])).all() #在这个范围内 查询的结构顺序会乱 for i in aa: print(i.name)
print("--------------------------") cc=session.query(Users).filter(~Users.id.in_([1,3,4])).all() # ~不在这个范围内 for i in cc: print(i.name) # 5. 子查询 aa=session.query(Users).filter(Users.id.in_(session.query(Users.id).filter(Users.name=='李四'))).all() for i in aa: print(i.name) # 6. and 和 or from sqlalchemy import and_, or_ aa=session.query(Users).filter(Users.id > 3, Users.name == '李四').all() # 默认就是and for i in aa: print(i.name) bb=session.query(Users).filter(and_(Users.id > 3, Users.name == '马上')).all() #and #id大于3 并且name=马上 for i in bb: print(i.name) cc=session.query(Users).filter(or_(Users.id < 2, Users.name == '黄色')).all() # or_(Users.id < 2, Users.name == '黄色')表示id小于2 或者name等于黄色 for i in cc: print(i.name) dd=session.query(Users).filter( or_( Users.id < 2, and_(Users.name == 'eric', Users.id > 3), Users.extra != "" )).all() for i in dd: print(i.name) # 7. filter_by aa=session.query(Users).filter_by(name='李四').all() print(aa) for i in aa: print(i.name) # 8. 通配符 ret1 = session.query(Users).filter(Users.name.like('李%')).all() for i in ret1: print(i.name) ret = session.query(Users).filter(~Users.name.like('黄%')).all() for i in ret: print(i.name) # 9. 切片 result = session.query(Users)[1:3] 切片 (限制/分页) print(result) for i in result: print(i.name) # 10.排序 ret1 = session.query(Users).order_by(Users.name.desc()).all() #升序 for i in ret1: print(i.name) print("-----------------") ret2= session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 降序 for i in ret2: print(i.name) # 11. group by from sqlalchemy.sql import func # 导入 func,func 中有聚合函数 ret = session.query( Users.dep_id, func.count(Users.id), ).group_by(Users.dep_id).all() for item in ret: print(item) # group_by(字段)之后不要 query() 所有字段 print("-----------------------------------------------------") ret = session.query( Users.dep_id, func.count(Users.id), ).group_by(Users.dep_id).having(func.count(Users.id) >=2).all() 根据 name 分组,func.count(Users.id) > 2 ;根据聚合函数进行二次筛选:having for item in ret: print(item) # 12.union 和 union all 组合(垂直/上下连表):union 和 union all --- union all 去重,union 不去重 # Union All:对两个结果集进行并集操作,包括重复行,不进行排序 # Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序; # 有关union和union all关键字需要注意的问题是: # union 和 union all都可以将多个结果集合并,而不仅仅是两个,你可以将多个结果集串起来。 # 使用union和union all必须保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。但列名则不一定需 # union 和 union_all 的区别 # union 去重 # union_all 不去重 # 相同点:合并的两张表的列要相同 """ select id,name from users UNION select id,name from users; """ q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union(q2).all() print(ret) q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union_all(q2).all() print(ret) session.close()
3. SQLAlchemy 一对多(ForeignKey)
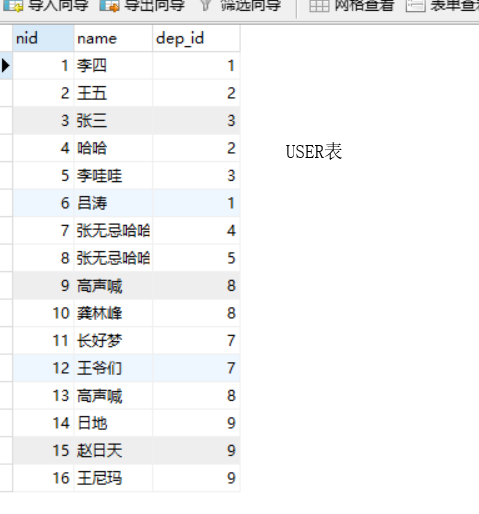
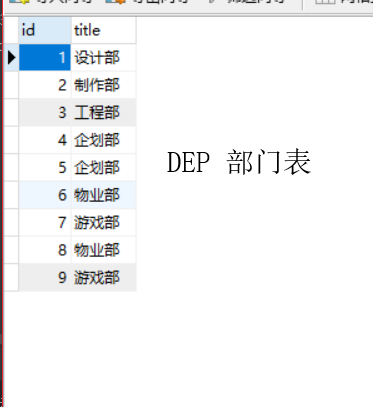
models.py
import datetime from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index from sqlalchemy.orm import relationship Base = declarative_base() # ##################### 一对多示例表 ######################### class Dep(Base): __tablename__ = 'dep' id = Column(Integer, primary_key=True) title = Column(String(50),index=True,nullable=False) class Users(Base): __tablename__ = 'users' nid = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) dep_id = Column(Integer, ForeignKey("dep.id")) # 与生成表结构无关,仅用于查询方便 dp = relationship("Dep", backref='pers') # 这个会在数据库创建 只会创建一个简单的关系 (跨表操作) def create_all(): """ 根据类创建数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb3?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) def drop_all(): """ 根据类删除数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb3?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) if __name__ == '__main__': create_all() # drop_all()
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Users,Dep engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb3?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查 session = SessionFactory() # 1. 查询所有用户 ret=session.query(Users).all() for roe in ret: print(roe.nid,roe.name,roe.dep_id) # 2. 查询所有用户+所属部门名称 print("————————————————————————————————————————————") res=session.query(Users,Dep).join(Dep).all() for roe in res: print(roe[0].name,roe[1].title) print("————————————————————————————————————————————") aa=session.query(Users.nid ,Users.name,Dep.title,Users.dep_id).join(Dep,Users.dep_id==Dep.id).all() for roe in aa: print(roe) print("2222222222222222") print(roe.nid,roe.name,roe.title) print("————————————————————————————————————————————") bb=session.query(Users.nid ,Users.name,Dep.title).join(Dep,Users.dep_id==Dep.id,isouter=True) print(bb) print("————————————————————————————————————————————") # 查询所有用户+所属部门名称 # relationship 字段 # 这个会在数据库创建 只会创建一个简单的关系 (可以正向和反向查找) cc=session.query(Users).all() for roe in cc: print(roe.nid,roe.name,roe.dep_id,roe.dp.title) # 反查 部门对应的人 查询工程部所有的人员 ob=session.query(Dep).filter(Dep.title=="工程部").first() for roe in ob.pers: print(roe.nid,roe.name,ob.title) # 5. 创建一个名称叫:IT部门,再在该部门中添加一个员工:田硕 # 方式一: d1 = Dep(title='企划部') session.add(d1) session.commit() u1 = Users(name='张无忌哈哈哈',dep_id=d1.id) session.add(u1) session.commit() # 方式二: u1 = Users(name='高声喊',dp=Dep(title='物业部')) session.add(u1) session.commit() # 6. 创建一个名称叫游戏,再在该部门中添加一个员工:龚林峰/长好梦/王爷们 d1 = Dep(title='游戏部') #一个部门创建了三个人 d1.pers = [Users(name='日地'),Users(name='赵日天'),Users(name='王尼玛'),] session.add(d1) session.commit() session.close()
4. SQLAlchemy 多对多(ForeignKey+ForeignKey)

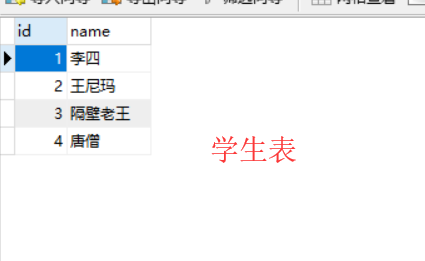
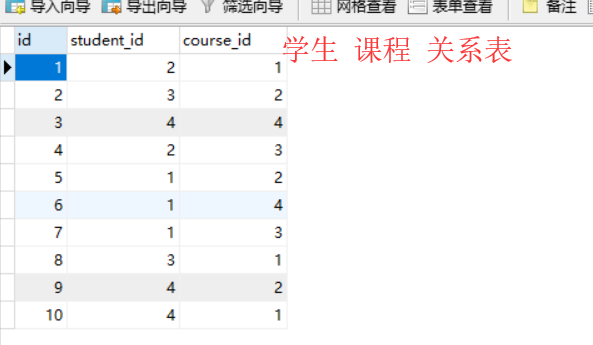
models.py
import datetime from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index from sqlalchemy.orm import relationship Base = declarative_base() # ##################### 多对多示例表 ######################### class Student(Base): __tablename__ = 'student' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) # 与生成表结构无关,仅用于查询方便 course_list = relationship('Course', secondary='student2course', backref='student_list') class Course(Base): __tablename__ = 'course' id = Column(Integer, primary_key=True) title = Column(String(32), index=True, nullable=False) class Student2Course(Base): __tablename__ = 'student2course' id = Column(Integer, primary_key=True, autoincrement=True) student_id = Column(Integer, ForeignKey('student.id')) course_id = Column(Integer, ForeignKey('course.id')) __table_args__ = ( UniqueConstraint('student_id', 'course_id', name='uix_stu_cou'), # 联合唯一索引 # Index('ix_id_name', 'name', 'extra'), # 联合索引 ) def create_all(): """ 根据类创建数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb4?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) def drop_all(): """ 根据类删除数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb4?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) if __name__ == '__main__': create_all() # drop_all()
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb4?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查 session = SessionFactory() # 1. 录入数据 session.add_all([ Student(name='隔壁老王'), Student(name='唐僧'), Course(title='语文'), Course(title='地理'), ]) session.commit() session.add_all([ Student2Course(student_id=3,course_id=1) ]) session.commit() # 2. 三张表关联 ret = session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).order_by(Student2Course.id.asc()) for row in ret: print(row) print("________________________________----") # (1, '王尼玛', '生物') # (2, '隔壁老王', '体育') # (3, '唐僧', '地理') # (4, '王尼玛', '语文') # (5, '李四', '体育') # (6, '李四', '地理') # (7, '李四', '语文') # (8, '隔壁老王', '生物') # (9, '唐僧', '体育') # (10, '唐僧', '生物') # 3. “王尼玛”选的所有课 ret = session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).filter(Student.name=='李四').order_by(Student2Course.id.asc()).all() print(ret) # [(5, '李四', '体育'), (6, '李四', '地理'), (7, '李四', '语文')] # 4. “唐僧”选的所有课 # relationship # 与生成表结构无关,仅用于查询方便 print("________________________________----") obj = session.query(Student).filter(Student.name=='唐僧').first() for item in obj.course_list: print(item.title) # 生物 # 体育 # 地理 print("________________________________----") # relationship # 与生成表结构无关,仅用于查询方便 # 4. 选了“生物”的所有人 反向查找 obj1 = session.query(Course).filter(Course.title=='生物').first() for item in obj1.student_list: print(item.name) # 王尼玛 # 隔壁老王 # 唐僧 # 5. 创建一个课程,创建2学生,两个学生选新创建的课程。 obj = Course(title='英语') obj.student_list = [Student(name='老司机'),Student(name='幺二二')] session.add(obj) session.commit() session.close()
5. 数据库连接方式(多线程 每次都要去数据库获取连接 ) 注意:连接放在全局只会获取一次
方式一(推荐) :每次线程来都去获取一个连接(内部是基于threading.local) 方式二:也差不多
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb4?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) session = scoped_session(SessionFactory) def task(): ret = session.query(Student).all() for row in ret: print(row.name) # 李四 # 王尼玛 # 隔壁老王 # 唐僧 # 李四 # 将连接交还给连接池 session.remove() from threading import Thread for i in range(20): t = Thread(target=task) t.start()
方式二
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb4?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) def task(): # 去连接池中获取一个连接 session = SessionFactory() ret = session.query(Student).all() for row in ret: print(row.name) # 唐僧 # 李四 # 李四 # 将连接交还给连接池 session.close() from threading import Thread for i in range(20): t = Thread(target=task) t.start()
6. 原生sql
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:root@localhost:3306/mydb4?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) session = scoped_session(SessionFactory) def task(): """""" # 方式一 原生sql: """ # 查询 # cursor = session.execute('select * from users') # result = cursor.fetchall() # 添加 cursor = session.execute('INSERT INTO users(name) VALUES(:value)', params={"value": 'wupeiqi'}) session.commit() print(cursor.lastrowid) """ # 方式二 原生sql: conn = engine.raw_connection() cursor = conn.cursor() cursor.execute( "select * from t1" ) result = cursor.fetchall() cursor.close() conn.close() # 将连接交还给连接池 session.remove() from threading import Thread for i in range(20): t = Thread(target=task) t.start()