运维在上线,无聊写博客。最近看了下Spring的缓存框架,这里写一下
1.Spring 缓存框架 原理浅谈
2.Spring 缓存框架 注解使用说明
3.Spring 缓存配置 + Ehcache(默认)
4.Spring 缓存配置 + Ehcache(自己实现)
5.Spring 缓存配置 + Memcache
6.Ehcache和Memcache的资料收集
Spring提供的缓存注解,通过对CacheManager管理Cache,实现对缓存的操作。Spring提供的CacheManager和Cache的关系,可以类比Ehcache里面的Cache和Element的关系。例如存储用户的缓存,对应的数据接口是:CacheManager中管理着一个Map<key,Cache>结构的Cache集合(参考:ConcurrentMapCacheManager.cacheMap),Map的key值为@Cacheable注解中的name属性,存储内容(Cache)对应的则是同一个name对应的一类数据。这一类数据会根据@Cacheable中key的属性,在Cache里面存储成Map<key,Element>结构的对象集合(参考:ConcurrentMapCache.store)。
可以简单的说,在Spring的@Cache注解中,管理的是一个Map1<name, Map2<key, value>>的存储结构,Map1对应的是CacheManager实现,Map2对应的是Cache实现,在实现中CacheManager和Cache都可以通过配置的方式,实现不同的缓存策略,如下图:
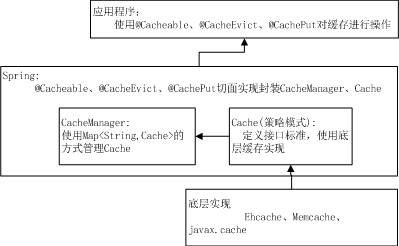
在如上结构中,主要应用了策略模式【面向接口,而不是面向实现】实现业务与具体实现的隔离;通过具体的不同策略实现【开闭原则】,可以方便的增加多个具体实现;业务代码只依赖接口(此处依赖注解),不依赖具体的实现【依赖倒转原则】,高层的业务模块不依赖底层的具体算法。
在底层的具体实现上面,Spring通过配置不同的动态代理的实现【代理工厂】对实现方式进行管理。
在这个框架中Map1<name, Map2<key, value>>的局限性在于,存储结构是一个二层的树状结构,但是现在大部分的缓存例如Memcache和Redis都是<K,V>结构。而且如果把Memcache存储成<K,Map<key,val>>结构的话,在判断缓存(K_key)是否存在的时候,需要把整个K对应的Map从缓存服务器中放到本地环境进行判断,对于宽带和效率上都有比较大的影响。
因此在具体实现的时候,针对集中是缓存,最好不要简单的使用CacheManager和Cache的Map1<name,Map2<key,value>>结构来实现。而是通过其他的方式,将需要存储的值,最终存储成<K,V>结构来提升效率(PS:不使用Map1<name,Map2<key,value>>会导致CacheEvict的allEntries属性失效,后面文章细说)。