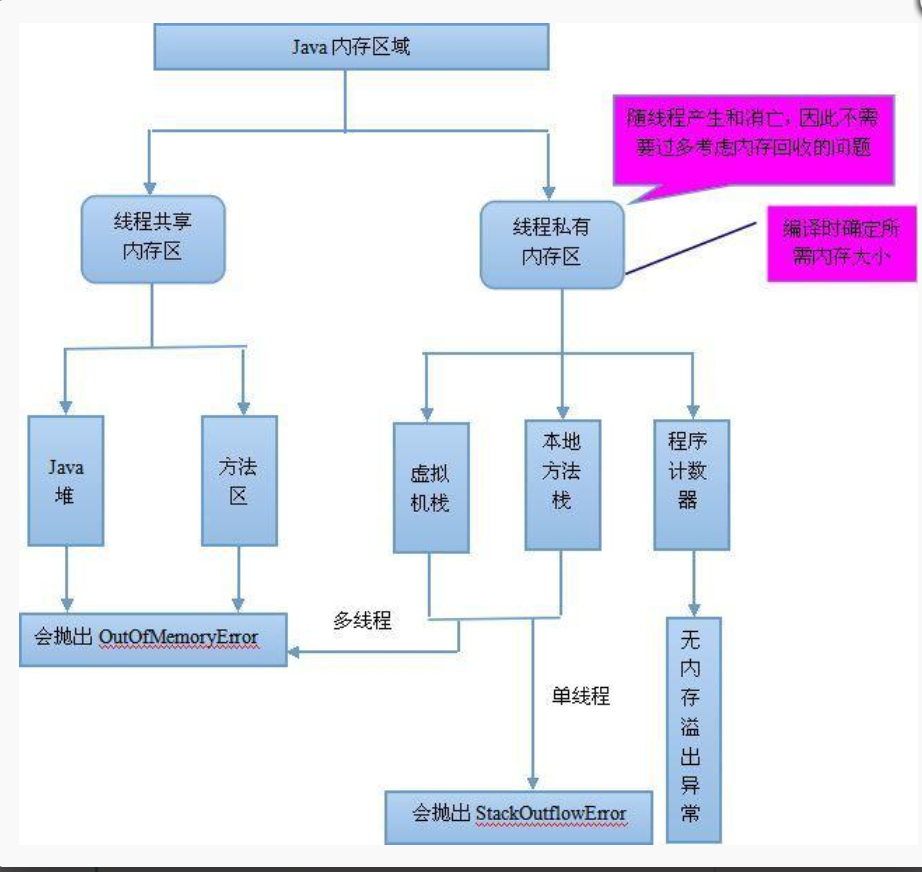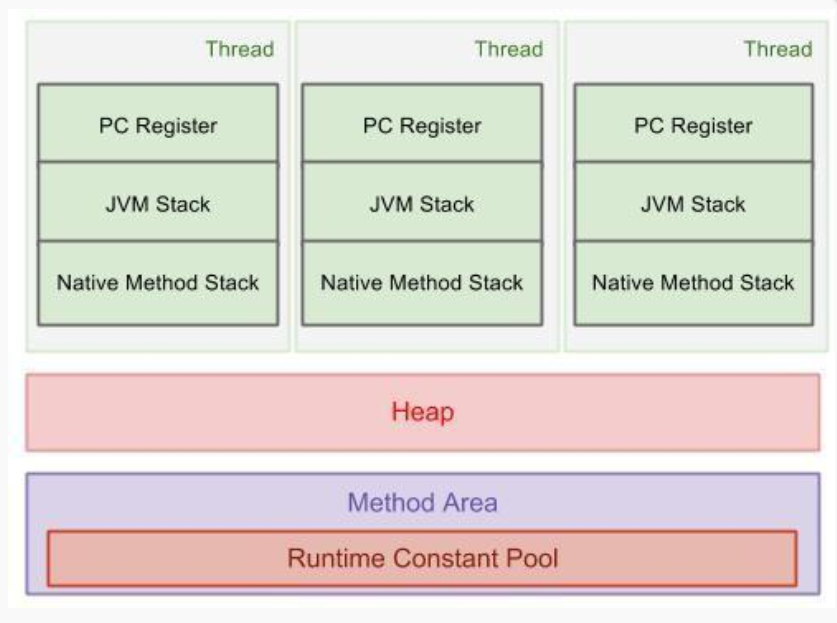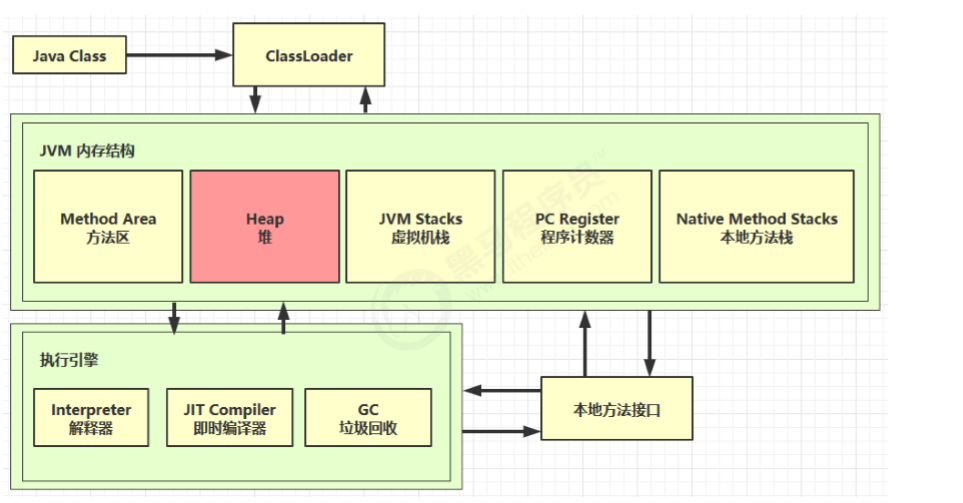
一、程序计数器/PC寄存器 (Program Counter Registe)
用于保存当前正在执行的程序的内存地址(下一条jvm指令的执行地址),由于Java是支持多线程执行的,所以程序执行的轨迹不可能一直都是线性执行。当有多个线程交叉执行时,被中断的线程的程序当前执行到哪条内存地址必然要保存下来,以便用于被中断的线程恢复执行时再按照被中断时的指令地址继续执行下去。为了线程切换后能恢复到正确的执行位置,每个线程都需要有一个独立的程序计数器,各个线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存,是线程安全的。
特点:1.线程私有 2.不会存在内存溢出
二、虚拟机栈(Java Virtual Machine Stack)
虚拟机栈总是与线程关联在一起的,每当创建一个线程,JVM就会为该线程创建对应的虚拟机栈,在这个虚拟机栈中又会包含多个栈帧(Stack Frame),这些栈帧是与每个方法关联起来的,每运行一个方法就创建一个栈帧,每个栈帧会含有一些局部变量、操作栈和方法返回值等信息。每当一个方法执行完成时,该栈帧就会弹出栈帧的元素作为这个方法的返回值,并且清除这个栈帧,虚拟机栈的栈顶的栈帧就是当前正在执行的活动栈,也就是当前正在执行的方法,PC寄存器也会指向该地址。(只有一个活动栈)只有这个活动的栈帧的本地变量可以被操作栈使用,当在这个栈帧中调用另外一个方法时,与之对应的一个新的栈帧被创建,这个新创建的栈帧被放到Java栈的栈顶,变为当前的活动栈。同样现在只有这个栈的本地变量才能被使用,当这个栈帧中所有指令都完成时,这个栈帧被移除虚拟机栈,刚才的那个栈帧变为活动栈帧,前面栈帧的返回值变为这个栈帧的操作栈的一个操作数
2.1 特点:
- 每个线程包含一个栈区,栈中只保存方法中(不包括对象的成员变量)的基础数据类型和自定义对象的引用(不是对象),对象都存放在堆区中
- 每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
- 栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
2.2 问题辨析:
1.垃圾回收涉及到栈内存吗? 不涉及,栈内存中存放了一个个栈帧,当一个栈帧执行完时,该栈帧就会弹出虚拟机栈,然后被清空
2.栈内存分配越大越好吗? 不是,总内存是一定的,当栈内存分配大了,最大线程数就会减少
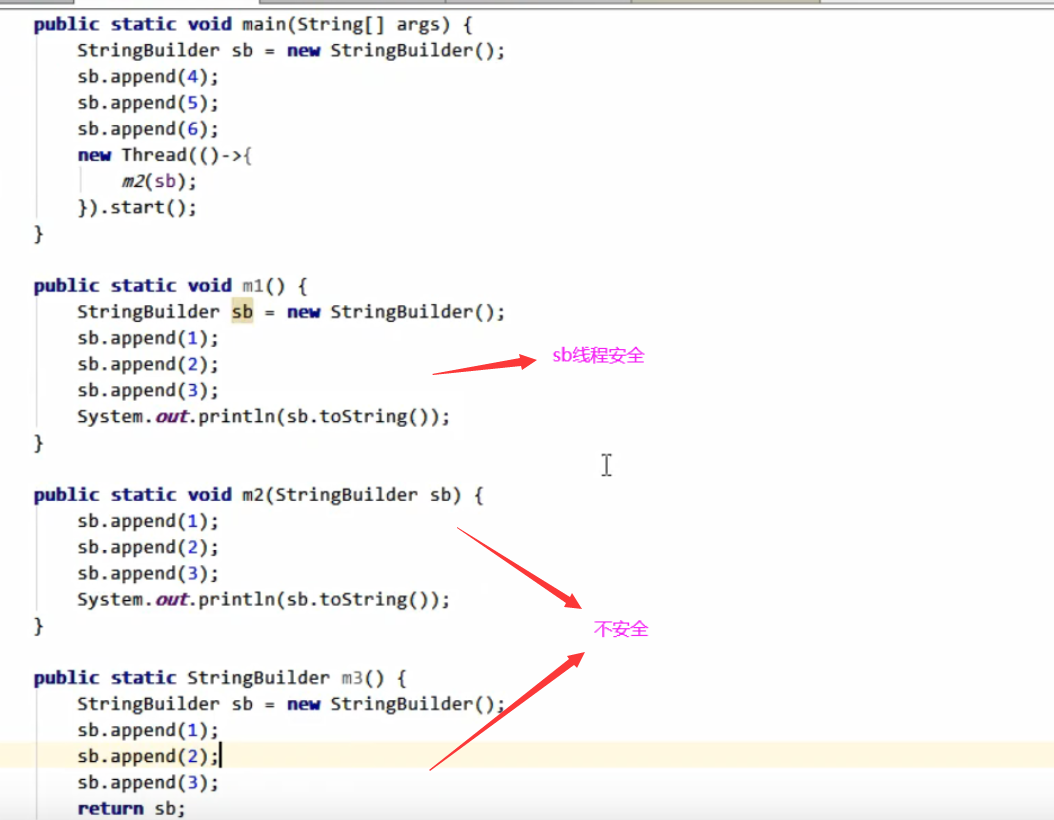
3.方法内的局部变量是否线程安全?
(1).如果方法内局部变量没有逃离方法的作用访问,它是线程安全的
(2).如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
2.3 栈内存溢出
原因:
1.栈帧过多导致栈内存溢出
2.栈帧过大导致栈内存溢出
以上都属于线程请求的栈深度大于虚拟机所允许的深度,会报StackOverflowError异常,如果虚拟机可以动态扩展,如果扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常。
三、本地方法栈(Native Method Stacks)
本地方法栈和Java(虚拟机)栈所发挥的作用非常相似,区别不过是Java栈为JVM执行Java方法服务,而本地方法栈为JVM执行Native方法服务。本地方法栈也会抛出StackOverflowError和OutOfMemoryError异常。
1.存储的全部是对象实例,每个对象都包含一个与之对应的class的信息(class信息存放在方法区)。
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身,几乎所有的对象实例和数组都在堆中分配。
3.不需要连续的内存、可以选择固定大小、可扩展
4.2 堆内存溢出
当堆中没有可用内存完成实例分配,并且也无法再扩展时

4.3 堆内存诊断
1. jps 工具
查看当前系统中有哪些 java 进程
2. jmap 工具
查看堆内存占用情况 jmap - heap 进程id
3. jconsole 工具
图形界面的,多功能的监测工具,可以连续监测
五、方法区
又叫静态区,跟堆一样,被所有的线程共享。它用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据(比如spring 使用IOC或者AOP创建bean时,或者使用cglib,反射的形式动态生成class信息等)。
5.1 组成
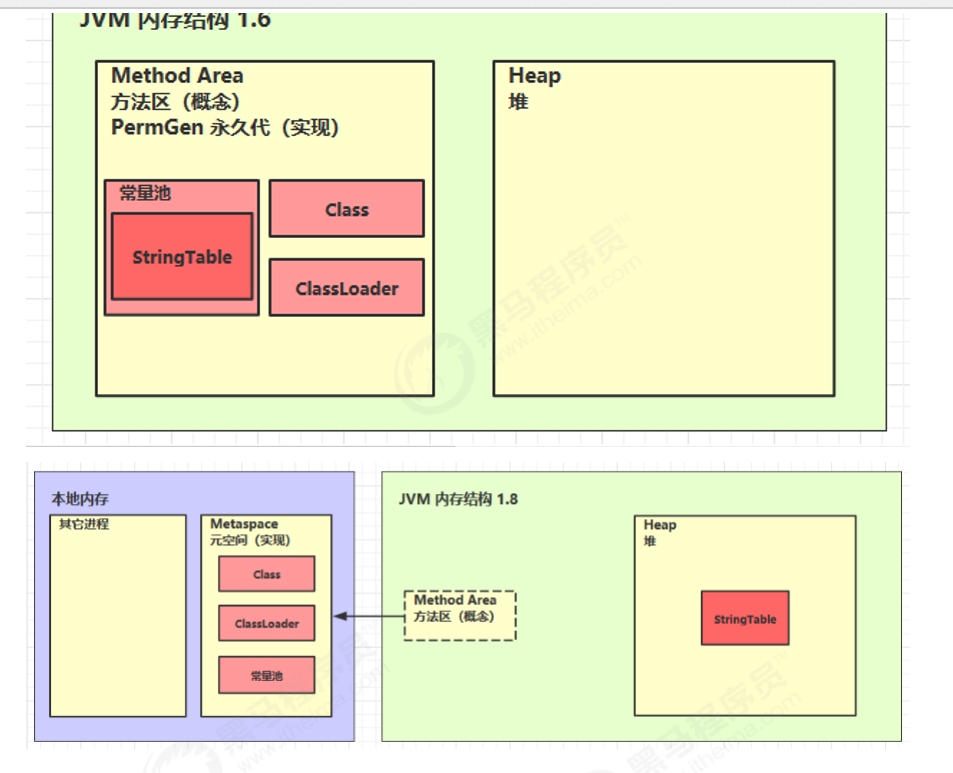
由上图可知,jdk1.6的时候,方法区是通过永久代实现的。而对于jdk1.8,方法区是通过元空间实现的。存储位置不同,永久代物理是是堆的一部分,和新生代,老年代地址是连续的,而元空间属于本地内存;
注:JDK 6 时,String等字符串常量的信息是置于方法区中的,但是到了JDK 7 时,已经移动到了Java堆。
5.2 方法区内存溢出
永久代内存溢出 :java.lang.OutOfMemoryError: PermGen space
-XX : MaxPermSize=8m
元空间内存溢出 : java.lang.OutOfMemoryError: Metaspace
-XX : MaxMetaspaceSize=8m
5.3 常量池
常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量 等信息
5.4 运行时常量池
运行时常量池是方法区的一部分,常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量 池,并把里面的符号地址变为真实地址,一个类加载到 JVM 中后对应一个运行时常量池
5.5 字符串常量池(StringTable)
5.5.1 注意:
- 在JDK1.7之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时hotspot虚拟机对方法区的实现为永久代
- 在JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是hotspot中的永久代
- 在JDK1.8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)
5.5.2 特性:
1.常量池中的字符串仅是符号,第一次用到时才变为对象
2.利用串池的机制,来避免重复创建字符串对象
3.字符串变量拼接的原理是 StringBuilder (1.8)
4. 字符串常量拼接的原理是编译期优化
5.可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份, 放入串池, 会把串池中的对象返回
6.可被垃圾回收
7.hashtable 的实现
5.5.3 性能调优调整 -XX:StringTableSize=桶个数
String s1 = "a"; String s2 = "b"; String s3 = "a" + "b"; String s4 = s1 + s2; String s5 = "ab"; String s6 = s4.intern(); // 问 System.out.println(s3 == s4); System.out.println(s3 == s5); System.out.println(s3 == s6);
String x2 = new String("c") + new String("d"); String x1 = "cd";
x2.intern(); // 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢 System.out.println(x1 == x2);
共6个答案:false true true false true false
六、直接内存(Direct Memory)
NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可使用Native函数库直接分配堆外内存。不受Java堆大小(-Xmx)限制,从而可能造成各个内存区域总和大于物理内存限制而造成动态扩展时出现OutOfMemoryError。
6.1 特点:
1.常见于 NIO 操作时,用于数据缓冲区
2.分配回收成本较高,但读写性能高
3.不受 JVM 内存回收管理
6.2 分配和回收原理
1.使用了 Unsafe 对象完成直接内存的分配回收,并且回收需要主动调用 freeMemory 方法
2. ByteBuffer 的实现类内部,使用了 Cleaner (虚引用)来监测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调 用 freeMemory 来释放直接内存