Ubuntn16.04.3安装Hadoop3.0+scale2.12+spark2.2
前言:因为安装的Hadoop、Scale是基于JAVA的应用程序,所以必须先安装JDK。Spark是利用scale语言搭建,因此安装完jdk还需要安装scale才能让spark跑起来。
一、安装JDK
下载jdk,点击下载:
因为接下来安装的Hadoop版本是3.0所以这里安装1.8JDK
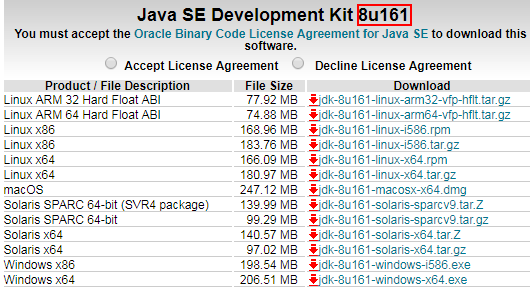
用户权限限制我们可以切换到root账户执行以下操作
l 新建一个文件夹存放jvm相关文件
sudo mkdir /usr/lib/jvm
l 解压下载的jdk文件并移动到jvm下
cd /usr/lib/jvm
sudo tar xzvf jdk-8u161-linux-x64.tar.gz
修改文件夹名jdk1.8.0_161-> jdk1.8
l 修改系统环境变量
sudo gedit ~/.bashrc
l 在文件底部追加
#JDK1.8
export JAVA_HOME=/usr/lib/jvm/jdk1.8 #目录要换成自己解压的jdk 目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
l 追加成功后保存,使环境变量立即生效
source ~/.bashrc
l 验证jdk是否安装成功
java -version
二、配置SSH免密登录
首先安装配置SSH
原因:不配置SSH免密登录,每次请求流程比较繁琐。客户机在与远程机进行交互时要进行三次才能登录:第一步请求远程机第二步远程机返回公钥第三步客户机使用密码+公钥加密后登录,这样导致每次都需要输入密码。
配置的ssh免密码登录后:客户机直接发送公钥到远程机,远程机发送随机字符串到客户机,客户机使用私钥加密传给远程机,远程机使用公钥加密后判断是否正确。
客户机掌握公钥和私钥,并且不再需要密码登录的方式成为ssh免密登录。
检测是否已经配置ssh
ssh -version
l 获取并安装ssh
sudo apt install openssh-server
l 配置ssh免密登录
ssh-keygen -t rsa # 一直回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
l 测试ssh无密登陆
ssh localhost # 如果不提示输入密码则配置成功
Are you sure you want to continue connecting (yes/no)? yes输入yes将不再需要密码
l 重启ssh服务
sudo /etc/init.d/ssh restart
三、安装Hadoop3
下载hadoop-linux-3.0.0.tar.gz至/usr/local/lib/hadoop3
l 解压压缩包
cd /usr/local/hadoop3
sudo tar xzvf hadoop-linux-3.0.0.tar.gz
l 添加环境变量
sudo gedit /etc/profile
在文件末尾添加
#Hadoop 3
export HADOOP_HOME=/usr/local/hadoop3 ##解压安装目录
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
l 立即生效
source /etc/profile
l 测试Hadoop
hadoop version
此时,如果出现警告WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
直接在/etc/profile 可以将HADOOP_HOME改为HADOOP_PREFIX
Hadoop配置修改
l 配置hdfs端口和地址,临时文件存放地址
sudo gedit /usr/local/hadoop3/etc/hadoop/core-site.xml
打开后修改配置文件
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop3/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
注释:localhost主机名,可以通过以下方式修改主机名
l 命令修改主机名称
sudo gedit /etc/hosts
#127.0.0.1 localhost
l 修改hdfs-site.xml文件配置副本个数以及数据存放的路径
sudo gedit /usr/local/hadoop3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop3/tmp/dfs/data</value>
</property>
</configuration>
l 修改hadoop-env.sh文件修改hadoop运行时环境变量
sudo gedit /usr/local/hadoop3/etc/hadoop/hadoop-env.sh
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/jdk1.8
修改JAVA_HOME指向Java安装路径
l 执行NameNode格式化
hdfs namenode -format
l 运行start-dfs.sh查看DataNode、NameNode线程编号
start-dfs.sh
修改mapred-site.xml配置YARN
cd /usr/local/hadoop3
cp ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
sudo gedit /usr/local/hadoop3/etc/hadoop/ mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
l 配置yarn-site.xml
cd /usr/local/hadoop3
sudo gedit ./etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
l 启动hadoop
start-dfs.sh
l 启动yarn
start-yarn.sh
此时,可能会出现一下错误提示
Q1:Starting namenodes on [localhost]
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch
解决方法:打开sbin/start-dfs.sh和stop-dfs.sh在文件头部添加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
Q2:出现一下yarn错误提示:
Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
Starting nodemanagers
ERROR: Attempting to launch yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch.
解决方案:打开sbin/start- yarn.sh和stop- yarn.sh在文件头部添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
l 启动历史服务器,以便在Web中查看任务运行情况
mr-jobhistory-daemon.sh start historyserver
l 停止历史服务器
mr-jobhistory-daemon.sh stop historyserver
l 停止yarn
stop-yarn.sh
l 停止hadoop
stop-dfs.sh
l 浏览器查看运行情况
localhost:8088
三、安装scale
因为spark是有scale语言编写,因此需要安装scale环境。
打开https://www.scala-lang.org/download/下载对应版本语言库,这里下载版本是scala-2.12.1.tgz 大小21.74M
l 将下载好的文件复制到/usr/local
l 2. 解压下载的scala文件
cd /usr/local/scala2.12
sudo tar -xzvf scala-2.12.1.tgz
l 3.添加环境变量
sudo gedit /etc/profile
l 添加一下配置
# Scala2.12.1
export SCALA_HOME=/usr/local/scala2.12
export PATH=$SCALA_HOME/bin:$PATH
l 配置生效
source /etc/profile
l 检测是否安装成功
scala –version
四、安装Spark
打开下载地址http://spark.apache.org/downloads.html,选择需要下载的Spark release版本和package type,点击spark-2.3.0-bin-hadoop2.7.tgz打开下载页面。
选择一个下载地址:
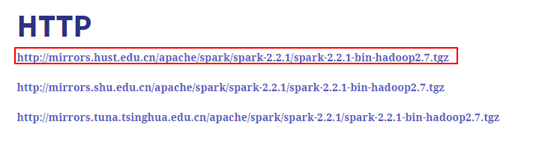
l 将下载好的文件复制到/usr/local/spark2.2
l 2.解压文件spark-2.2.1-bin-hadoop2.7.tgz
cd /usr/local/spark2.2
sudo tar -xzvf spark-2.2.1-bin-hadoop2.7.tgz
l 3.添加环境变量
sudo gedit /etc/profile
l 添加环境变量配置
#spark2.2.1
export SPARK_HOME=/usr/local/spark2.2
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
l 添加配置文件
l cong下创建配置文件spark-env.sh
#配置hadoop+jdk
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop3/bin/hadoop classpath)
export JAVA_HOME=/usr/lib/jvm/jdk1.8
l 启动Spark
/usr/local/spark2.2/sbin/start-all.sh
l 停止Spark
/usr/local/hadoop3/sbin/stop-all.sh
浏览器查看spark运行情况
localhost:8080