一、Mapreduce
原理
- 一个reduce任务的MapReduce数据流
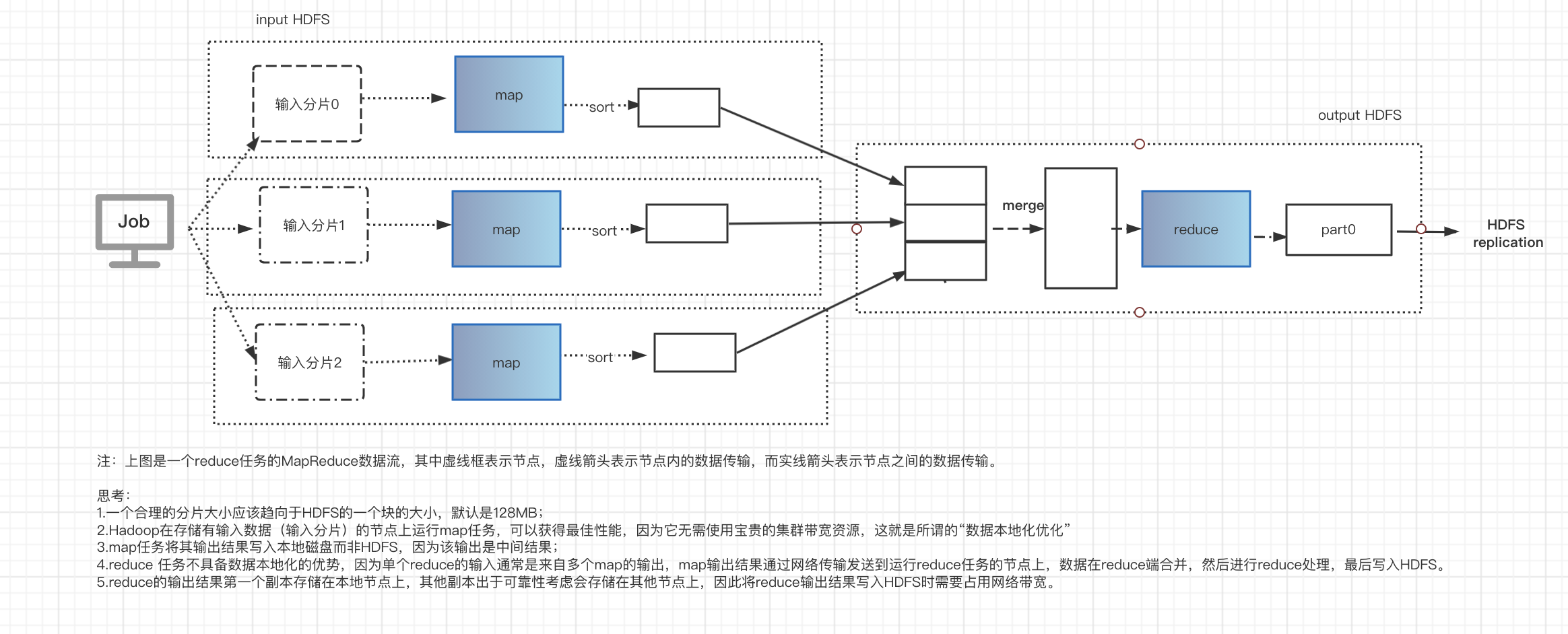
- 多个reduce任务的MapReduce数据流

combiner调优
集群上的可用带宽限制了MapReduce作业的数量,因此尽量避免map和reduce任务之间的数据传输是有利的,Hadoop允许用户正对map任务的输出制定一个combiner函数,combiner函数的输出作为reduce函数的输入。注意无论是否使用combiner函数reduce最终输出的结果没有变化。
2、HDFS
特点:
- 超大文件存储,TB甚至PB级别。
- 流式数据访问:一次写入多次读取。
- 不支持多用户写入,可以在原文件的基础上添加数据,但是不能在文件的任意位置修改数据。
- 由namenode来存储文件系统中所有元数据信息,所以该文件系统所能存储的文件总数受namenode容量的限制。
- 适合离线数据存储,对于低延迟数据可以考虑Hbase。
数据块
- HDFS上有块(block)的概念,默认是128MB, HDFS上的文件被划分为块大小的多个分块,进行独立存储。值得注意的是当一个1MB的文件存储在一个128MB的块中时,文件只占了1MB的磁盘空间,而不是128MB
- 数据块的好处:
1.一个文件的大小可以大于集群中任意一个磁盘的容量,文件的所有块并不需要存储在同一个磁盘上。
2. Hadoop将每个块复制到至少几个(默认3个)物理机上互相独立的机器上,保证在机器出故障后数据不丢失。
namenode和datanode
HDFS以管理节点-工作节点模式运行,即一个namenode和多个datanode,namenode管理文件系统的命名空间,它维护着文件系统树,及整棵树内所有的文件目录,这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件,namenode也记录着每个文件中各个块所在的数据节点信息,到那时它不会永久保存块的位置信息,因为这些信息会在系统启动时根据数据及诶单信息重建。
缓存块
通常情况下,datanode从磁盘中读取块,但是对于访问频繁的文件,可以先将其对于的块缓存在datanode的内存中,作业调度器(MapReduce、Spark等)通过在缓存块的datanode上运行任务,可以提高读操作的任务。
三、Hive
-
hive的基本组件
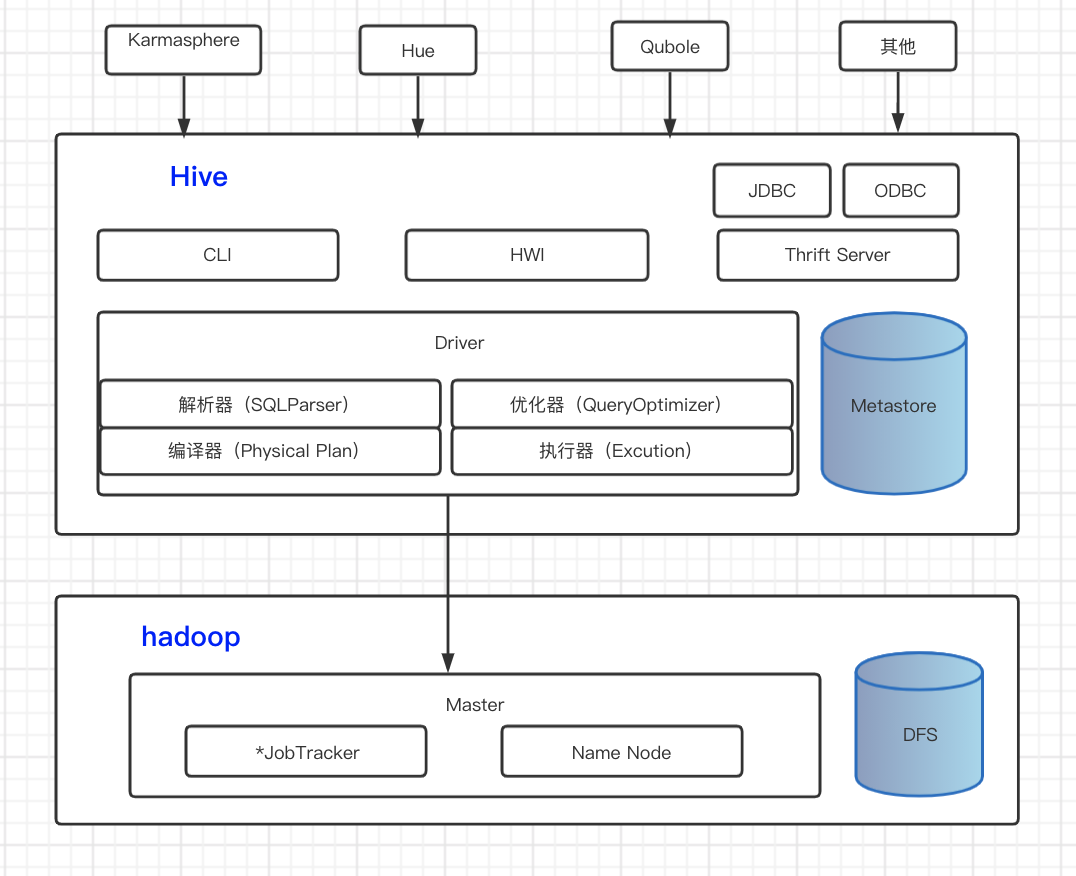
-
hive执行过程
hive的执行过程包括一下几步:HiveSql -> AST(抽象语法树) -> QB(查询块)-> OperatorTree(操作树) -> 优化操作树 -> mapreduce 任务树 -> 优化后的mapreduce树
大体过程如下图:
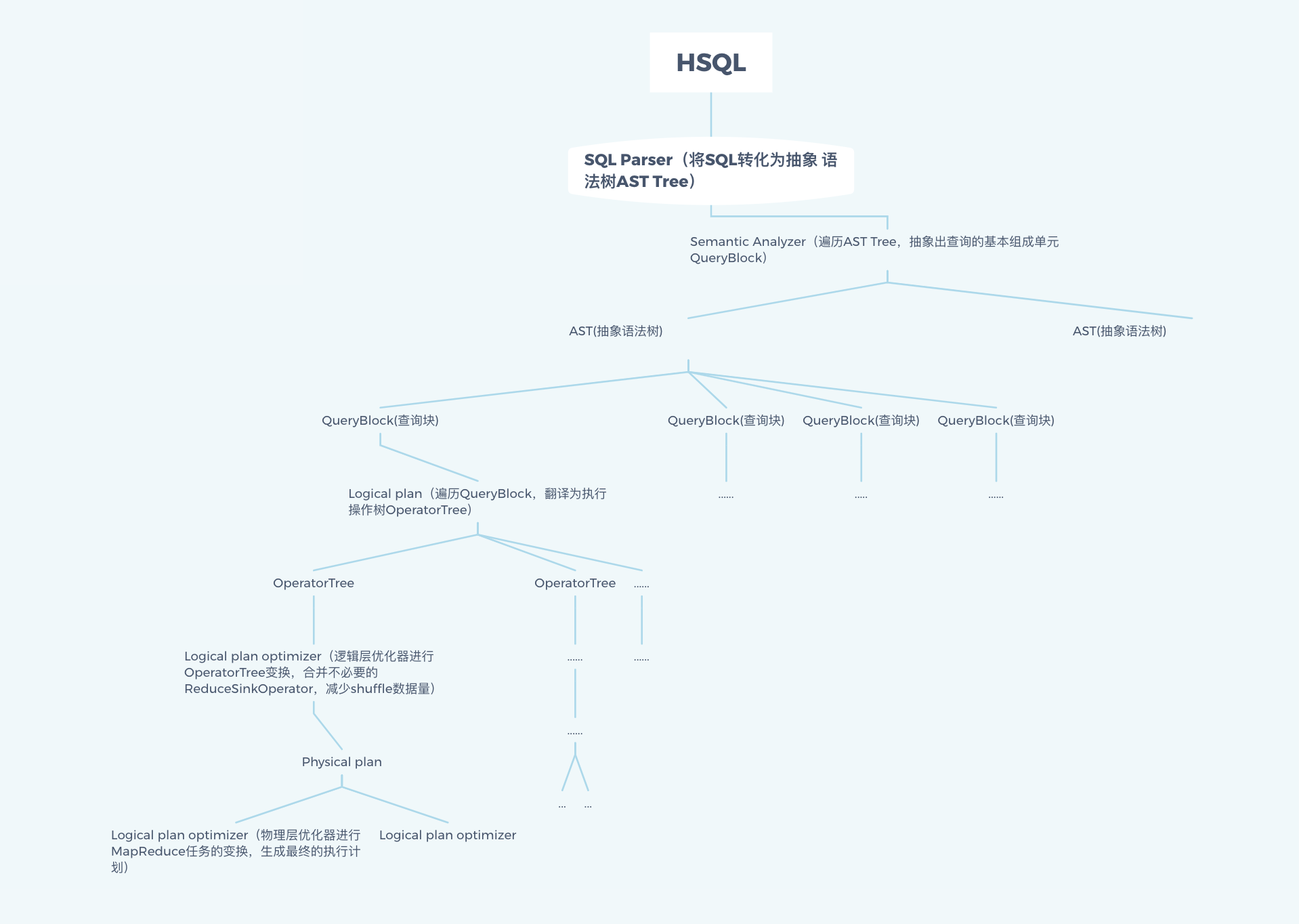
-
hive性能调优
https://www.cnblogs.com/ITtangtang/p/7683028.html
1.限制map和reduce的数量
2.JOIN优化
3.本地模式
4.strict模式
5.并行执行
6.动态分区调整
7.数据倾斜 -
小文件问题
小文件是如何产生的
1.动态分区插入数据,产生大量的小文件,从而导致map数量剧增。
2.reduce数量越多,小文件也越多(reduce的个数和输出文件是对应的)。
3.数据源本身就包含大量的小文件。
小文件问题的影响
1.从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
2.在HDFS中,每个小文件对象约占150byte,如果小文件过多会占用大量内存。这样NameNode内存容量严重制约了集群的扩展。
小文件问题的解决方案
从小文件产生的途经就可以从源头上控制小文件数量,方法如下:
1.使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件。
2.减少reduce的数量(可以使用参数进行控制)。
3.少用动态分区,用时记得按distribute by分区。
对于已有的小文件,我们可以通过以下几种方案解决:
1.使用hadoop archive命令把小文件进行归档。
2.重建表,建表时减少reduce数量。
3.通过参数进行调节,设置map/reduce端的相关参数,如下:
设置map输入合并小文件的相关参数:
- hive中的存储格式
行存储:TextFile(耗费存储空间,I/O性能较低;Hive不进行数据切分合并,不能进行并行操作,查询效率低。适合于小型查询)、Sequencefile(可压缩,占空间,适用于数据量较小,大部分列的查询)
列存储:ORC(压缩快,快速列存取,加载时性能消耗较大;需要通过text文件转化加载,适用于Hive中大型的存储、查询)、Patquet(Parquet能够很好的压缩和编码,有良好的查询性能,支持优先的模式演进。缺点:写速度通常比较慢。应用场景:适用于字段数非常多,无更新、只取部分列的查询。)