推荐的清理purge的方法:
>purge binary logs to 'mybin.log000001';半同步复制
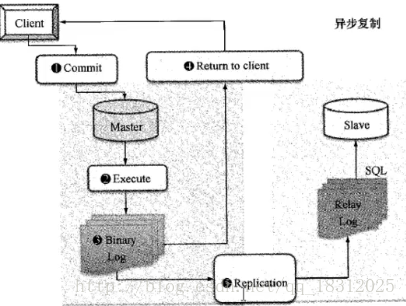
主库产生binlog到主库的binlog file,传到从库中继日志,然后从库应用。
即:传输是异步的,应用也是异步的。
半同步复制指的是传输同步,应用还是异步的。
- 好处:保证数据不丢失(本机和远端都有binlog)
- 坏处:不能保证应用的同步。
半同步复制的原理:
(半同步复制的流程:)
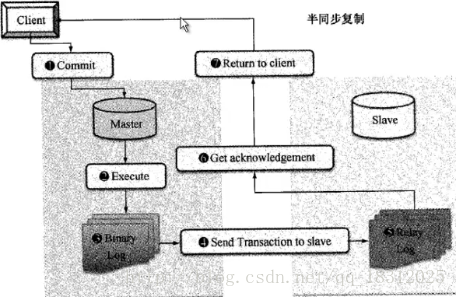
(即 主库忽然崩了时,从库虽然说有延迟,但是延迟过后,可以把从库提升为主库继续服务,事后恢复到主库即可)
(MySQL的异步复制流程:)
如何实现半同步复制?
半同步复制是一个功能模块,库要能支持动态加载才能实现半同步复制!
- ①看库是否支持动态加载(现在一般都支持)
> select @@have_dynamic_loading;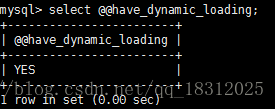
- ②主从库上分别安装插件
在主库上安装插件 semisync_master.so
> install plugin rpl_semi_sync_master soname 'semisync_master.so';在从库上安装 semisync_slave.so
> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';- ③安装完成后,从plugin表中能够看到刚才安装的插件
select * from mysql.plugin;- ④分别在主从库打开半同步复制(可加到配置文件里)
> set @@global.rpl_semi_sync_master_enabled=on;
> set @@global.rpl_semi_sync_slave_enabled=on;当一主多从
- ⑤重启一下从库的IO
> start slave io_thread;
> start slave io_thread;
(stop slave; -->IO和应用线程)- ⑥查看半同步状态
> show global status like '%rpl%';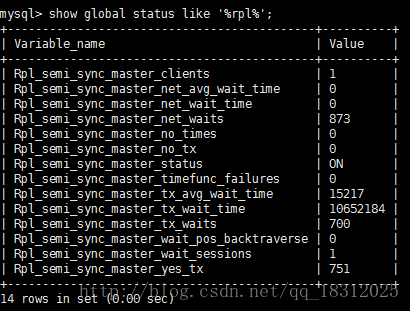
(图是主库在压测的时候的状态)
Rpl_semi_sync_master_clients
Rpl_semi_sync_master_net_avg_wait_time:网络等待的平均时间
Rpl_semi_sync_master_net_wait_time:网络等待时间
Rpl_semi_sync_master_net_waits
Rpl_semi_sync_master_no_times
Rpl_semi_sync_master_no_tx:大于0就是异步。半同步是应为0
Rpl_semi_sync_master_status
Rpl_semi_sync_master_timefunc_failures
Rpl_semi_sync_master_tx_avg_wait_time:平均等待时间
Rpl_semi_sync_master_tx_wait_time:总的等待时间
Rpl_semi_sync_master_tx_waits
Rpl_semi_sync_master_wait_pos_backtraverse
Rpl_semi_sync_master_wait_sessions
Rpl_semi_sync_master_yes_tx:大于0就是 同步模式开启半同步复制意味着什么?
在主库开启一个事务,这个事务在主库和远端的从库各存一份。此时 Rpl_semi_sync_master_yes_tx 的值加一。忽然断网时,会有10s的hang住(rpl_semi_sync_master_timeout =10000),然后mysql会自己关闭主从复制。然后变成异步。此时Rpl_semi_sync_master_yes_tx 值不变了,而Rpl_semi_sync_master_no_tx 的值就开始加一。
- ⑦模拟断网时的状态
# iptables -A INPUT -s IP -j DROP
-A:处理INPUT
-s:源地址
-j:处理的策略是DROP会发现,压测的trx忽然降低,但不会降低为0。因为此时变成了异步。但是一会儿之后,mysql会自动恢复到同步。
从库的日常管理和错误处理
- 1、master_connect_retry 参数
mysql> change master to
master_host='192.168.159.131',
master_user='congku',
master_password='123123',
master_log_file='mastera.000028',
master_log_pos=245,
master_connect_retry=10;
#连接主库失败时,每隔10s钟就重新连一下- 2、log_slave_updates参数
用来配置一级从库是否写二进制日志。此参数要和–logs-bin 参数一起使用。
- 3、–read-only 参数
用来设置从库只能接受root的更新操作,限制了应用程序错误的对从库的更新操作。使用后,保证了主从的一致性,从库的更新就只能来自于主库的更新了。可在从库启动时启动,也可以加到配置文件。
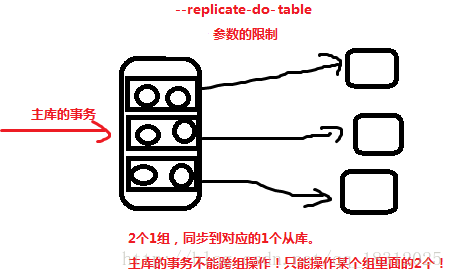
# mysqld_safe --defaults-file=/etc/my.cnf --user=root --read-only- 4、–replicate-do-table 参数
从库启动时添加。实现了从库的分拆,将从库分拆成多个不一致的从库,分别同步不同的库或表。
(例如,让四个从库来同步一个主库,这样应用延迟就会降低。
主库的日志会分4个完整的,传给4个从库。然后从库都接到后,再看是对谁做的操作,例如是对促销的相关操作。就只有对应的2号从库更新。)
事务层面:主库的事务不能跨组操作,只能操作某个组里面的2个!
此参数使用的限制:
- 5、slave-skip-errors 参数
在复制过程中,从库可能由于各种原因遇到执行binlog中的SQL出错的情况(比如主键冲突),默认情况从库将会停止复制进程,等待用户处理,不再进行同步(hang住)。
此参数的作用就是用来定义复制过程中从库可以自动跳过的错误号。
取值:ddl_exist_errors(具体错误号)、all
用法:
#mysqld_safe --slave-skip-errors=1064 --defaults-file=/etc/my.cnf &PS:1064错误,是常见的sql语法不对时出现的错误。
从库如何处理sql应用出现的错误?
- ①slave-skip-errors 为all
时,忽略所有错误。为ddl_exist_errors(具体错误号)时,跳过这一个错误。(自动) - ②set global sql_slave_skip_counter=n:n的值为1或2。如果来自主库的更新语句不使用auto_increment 或 last_insert_id(),n值应为1,否则为2。(手工)然后重启stop slave;start slave;

上面的这一个sql,会生成2条日志,如果想在同步时跳过这条sql,n=2即可。
怎么监控:> show slave status G #看读和执行的pos是不是在快速的缩短。
- 6、log event entry exceeded max_allowed_packet 的处理
如果应用中使用大的blog列或者长字符串,那么在从库上进行恢复的时候,可能会出现”log event entry exceeded max_allowed_packet”错误,这是因为含有大文本的记录无法通过网络进行传输导致。解决的办法就是在主从库上增加 max_allowed_packet 参数的大小。默认值1MB。可按实际需要修改。
#set global max_allowed_packet =16MB;Create By LPeng