参考:https://github.com/LouisYZK/ShiXi_inWuhan/tree/master/1.23
Flex技术是网站运用flash方法与客户端进行数据通信,数据的格式可以是txt,json或amf等。
AMF是一种二进制编码方式,其在flash传输效率高,以农业信息网数据为例,爬取的方式与一般ajax分析相同。通过抓包分析请求头和响应数据,然后构造请求、接受返回数据
通过爬取全国农产品批发市场价格信息系统,获取数据,但是此网站是通过flash展示数据,与现在大部分网站展示数据的方法不同,因此使用python下的pyamf来帮助我们获取数据。
1.分析网页
通过分析网页,我们得到信息,此网站的data是在hqapp.swf中
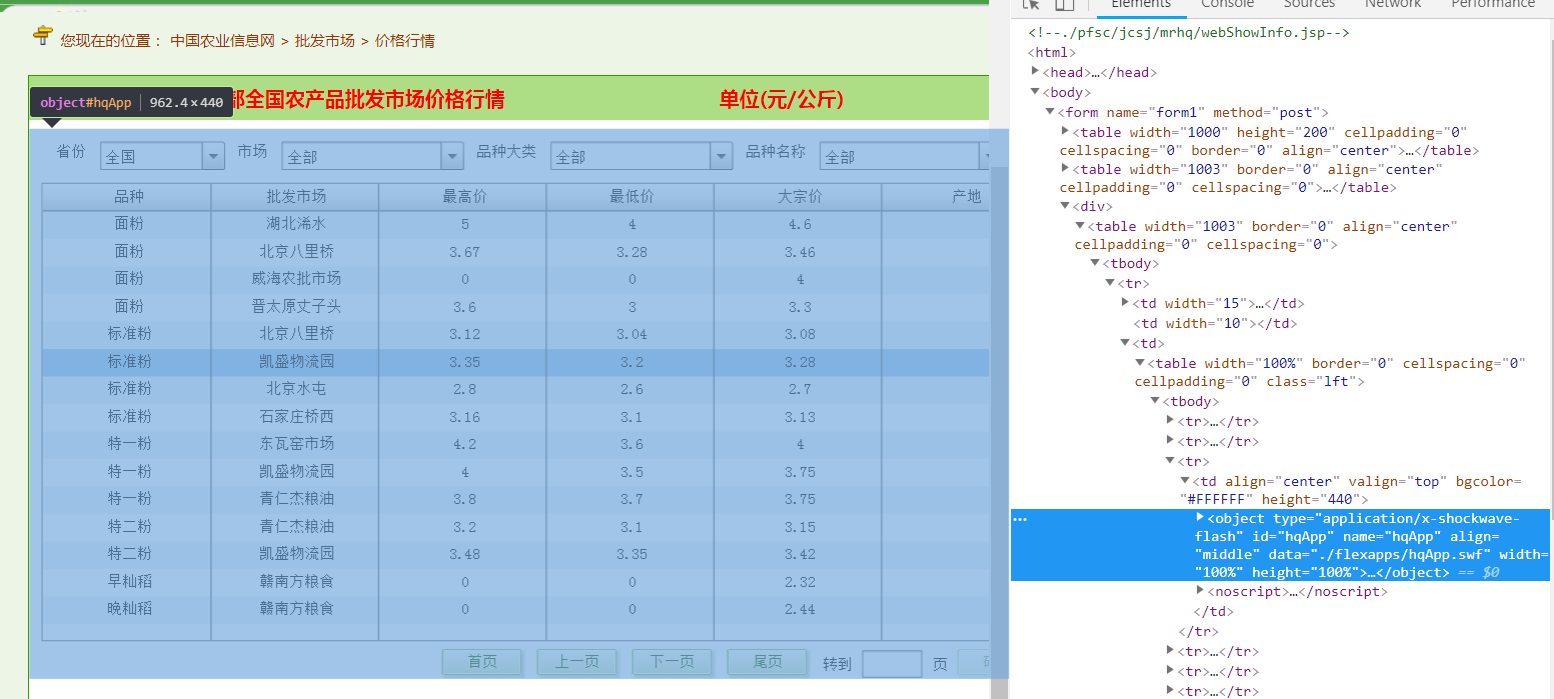
2.分析请求包
目前Chales抓包工具能够支持将AMF编码解析成明文形式,便于我们分析。
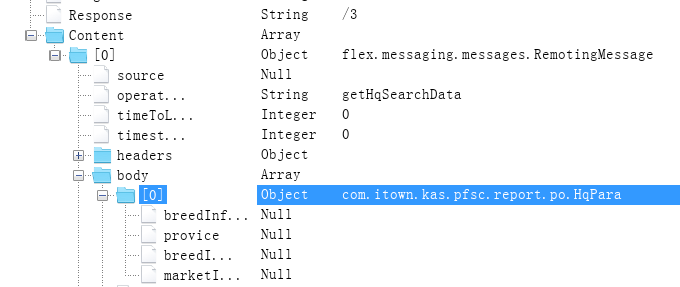
通过chares抓包,我们发现请求的body包含一个com.itown.kas.pfsc.report.po.HqPara对象和四个参数,结合网页可知为flash上的四个选择菜单,可以选择省份和批发市场名称等。
class HqPara: def __init__(self): self.marketInfo = None self.breedInfoDl = None self.breedInfo = None self.provice = None # 第一个是查询参数,第二个是页数,第三个是控制每页显示的数量(默认每页只显示15条)但爬取的时候可以一下子设置成全部的数量 # 构造请求数据 def getRequestData(page_num,total_num): # 注册自定义的Body参数类型,这样数据类型com.itown.kas.pfsc.report.po.HqPara就会在后面被一并发给服务端(否则服务端就可能返回参数不是预期的异常Client.Message.Deserialize.InvalidType) pyamf.register_class(HqPara, alias='com.itown.kas.pfsc.report.po.HqPara') # 构造flex.messaging.messages.RemotingMessage消息 msg = messaging.RemotingMessage(messageId=str(uuid.uuid1()).upper(), clientId=str(uuid.uuid1()).upper(), operation='getHqSearchData', destination='reportStatService', timeToLive=0, timestamp=0) msg.body = [HqPara(),str(page_num), str(total_num)] msg.headers['DSEndpoint'] = None msg.headers['DSId'] = str(uuid.uuid1()).upper() # 按AMF协议编码数据 req = remoting.Request('null', body=(msg,)) env = remoting.Envelope(amfVersion=pyamf.AMF3) env.bodies = [('/1', req)] data = bytes(remoting.encode(env).read()) return data # 返回一个请求的数据格式
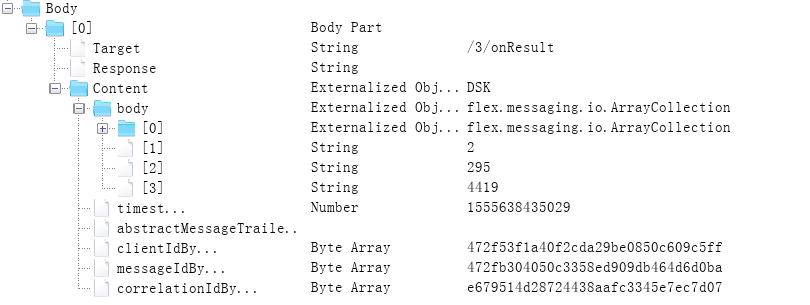
2.分析response
可以看到返回的response中,包含有所有记录条数
def getResponse(data): url = 'http://jgsb.agri.cn/messagebroker/amf' req = Request(url, data, headers={'Content-Type': 'application/x-amf'}) # 解析返回数据 opener = urllib2.build_opener() return opener.open(req).read() def getContent(response): amf_parse_info = remoting.decode(response) # 数据总条数 total_num = amf_parse_info.bodies[0][1].body.body[3] info = amf_parse_info.bodies[0][1].body.body[0] return total_num, info
3.解析和存储
def storagejson(info): path='info.json' path1='E:spyderdata\' res = [] for record in info: record['reportDate'] = record['reportDate'].strftime('%Y-%m-%d %H:%M:%S') record['auditDate'] = record['auditDate'].strftime('%Y-%m-%d %H:%M:%S') record['snatchDate'] = 'null' res.append(record) fp = open(path,'w',encoding='utf-8') json.dump(res,fp,indent=4,ensure_ascii= False) fp.close() os.rename(path,path1+filename+path) if __name__ == '__main__': filename = time.strftime("%Y-%m-%d", time.localtime()) # 第一次请求时,获取数据量 reqData = getRequestData(1,2) rep = getResponse(reqData) total_num,info = getContent(rep) # 一次请求完成 reqData = getRequestData(1, total_num) rep = getResponse(reqData) total_num,info = getContent(rep) storagejson(info)
所有代码


from urllib import request as urllib2 from urllib.request import Request import uuid import pyamf import json import time import os from pyamf import remoting from pyamf.flex import messaging class HqPara: def __init__(self): self.marketInfo = None self.breedInfoDl = None self.breedInfo = None self.provice = None # 第一个是查询参数,第二个是页数,第三个是控制每页显示的数量(默认每页只显示15条)但爬取的时候可以一下子设置成全部的数量 # 构造请求数据 def getRequestData(page_num,total_num): # 注册自定义的Body参数类型,这样数据类型com.itown.kas.pfsc.report.po.HqPara就会在后面被一并发给服务端(否则服务端就可能返回参数不是预期的异常Client.Message.Deserialize.InvalidType) pyamf.register_class(HqPara, alias='com.itown.kas.pfsc.report.po.HqPara') # 构造flex.messaging.messages.RemotingMessage消息 msg = messaging.RemotingMessage(messageId=str(uuid.uuid1()).upper(), clientId=str(uuid.uuid1()).upper(), operation='getHqSearchData', destination='reportStatService', timeToLive=0, timestamp=0) msg.body = [HqPara(),str(page_num), str(total_num)] msg.headers['DSEndpoint'] = None msg.headers['DSId'] = str(uuid.uuid1()).upper() # 按AMF协议编码数据 req = remoting.Request('null', body=(msg,)) env = remoting.Envelope(amfVersion=pyamf.AMF3) env.bodies = [('/1', req)] data = bytes(remoting.encode(env).read()) return data # 返回一个请求的数据格式 def getResponse(data): url = 'http://jgsb.agri.cn/messagebroker/amf' req = Request(url, data, headers={'Content-Type': 'application/x-amf'}) # 解析返回数据 opener = urllib2.build_opener() return opener.open(req).read() def getContent(response): amf_parse_info = remoting.decode(response) # 数据总条数 total_num = amf_parse_info.bodies[0][1].body.body[3] info = amf_parse_info.bodies[0][1].body.body[0] return total_num, info def storagejson(info): path='info.json' path1='E:spyderdata\' res = [] for record in info: record['reportDate'] = record['reportDate'].strftime('%Y-%m-%d %H:%M:%S') record['auditDate'] = record['auditDate'].strftime('%Y-%m-%d %H:%M:%S') record['snatchDate'] = 'null' res.append(record) fp = open(path,'w',encoding='utf-8') json.dump(res,fp,indent=4,ensure_ascii= False) fp.close() os.rename(path,path1+filename+path) if __name__ == '__main__': filename = time.strftime("%Y-%m-%d", time.localtime()) # 第一次请求时,获取数据量 reqData = getRequestData(1,2) rep = getResponse(reqData) total_num,info = getContent(rep) # 一次请求完成 reqData = getRequestData(1, total_num) rep = getResponse(reqData) total_num,info = getContent(rep) storagejson(info)
遇到的问题:
1.pyamf
此次爬虫要用到python的pyamf库,anaconda中并没有这个库,因此得自己下载,通过查询得知可以通过pip安装
pip install PyAMF
但是安装过程出现错误,无法安装,于是通过下载源文件,解压到 python安装目录Libsite-packages下,改名为pamf,在pycharm中导入pyamf,即可使用。
网上搜索时,有人说pyamf不支持python3,需要替换为Py3AMF,但是实测pyamf在python3可以运行爬虫。