github地址:(https://github.com/LQ77/personal-project)
一、计划表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 490 | 660 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 300 |
| · Design Spec | · 生成设计文档 | 10 | 20 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 30 |
| · Coding | · 具体编码 | 90 | 60 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 150 |
| Reporting | 报告 | 60 | 120 |
| · Test Repor | · 测试报告 | 10 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 50 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| | 合计 |570 |800
二、解题思路
需求分析
- 统计文件有多少个字符,包括非数字字母字符
- 统计文件的有效行数。
- 统计单词的总数,该单词定义为“至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。”
- 统计文件中各单词出现的次数,然后输出频率最高的10个。
思路
我选择使用Java完成课题。
首先,在理解题意后,我先考虑需要几个类、几个对象;而后再考虑类中有几个属性、方法;并且整理好类与类之间的关系。
初步分析后,我确定了几个需要的类:首先是io包内的File类,new出从外部输入的文本的File类型,再使用util包内的Scanner类,对该文本中的内容进行跟踪、遍历等功能。根据课题需求,我拟定了四个方法去实现四个功能(后续由于统计字符和行数各只需一句话,固不分离,将统计单词数和计算词频并输出的方法分别存在CountWords和CountMaxOfWords这两个类并包装在lib包内)。
关键的词频统计部分,我联想到了Java中容器Map,其定义了存储键值key和值value的映射对的方法,将单词定义为key,词频定义为value,对统计和遍历将会有极大的帮助,因此我选择使用Map,并构建TreeMap。
三、设计实现
String directory = "D:\java\031602123\src";//用于测试的txt文件路径
File f = new File(directory,args[0]);
//创建一个File类f,指向test,txt;
//......
Scanner input = new Scanner(f)//创建一个Scanner类input指向f;
//......
Map<String, Integer> words = new TreeMap<String, Integer>();//创建TreeMap用于词频统计部分;
//利用while循环遍历txt文件内的每一行内容
while (input.hasNext()) {
String line = input.nextLine();
countOfCharacters += line.length();//计算当前行的字符个数;
countOfLine ++;//行数加一;
/*这是两个关键的方法,首先是在while循环内,每次调用一次countWords方法,对每一行统计符合条件的单词数,记录或更新词频;另一个则是在循环结束后,对Map中的数据进行一次遍历,并从中筛选 出符合条件的10组映射;*/
countOfWords += CountWords.countWords(line, words); //CountWords内的static方法countWords
CountMaxOfWords.Sort(words); //CountMaxOfWords内的static方法Sort
四、程序改进
在ecilpse中安装JProfiler插件,并进行观察。
首先先让我们看一下输出的结果: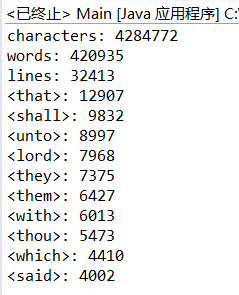
运行情况: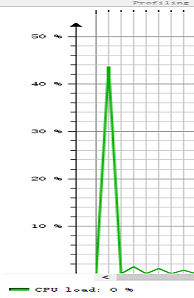
以及内存的分布:
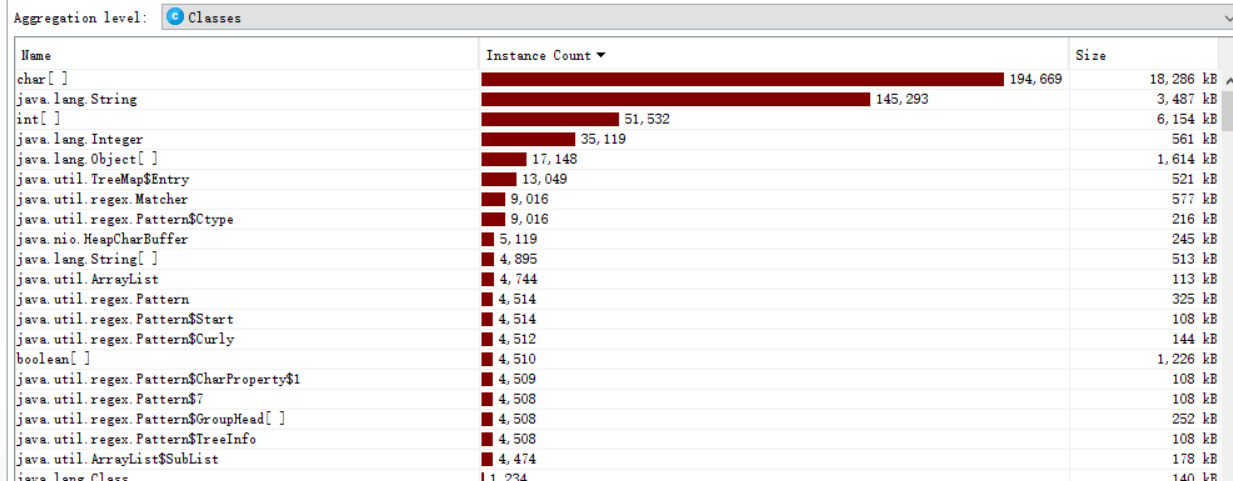
由于在方法CountWords内对单词是否符合条件的判断需要把String内转换成char[],所以char[]比String多,其次就是int[]与Integer,分别在CountMaxOfWords和TreeMap中使用。同时也能看出,方法CountWords是占用率最多的方法。
在最开始,统计单词数和统计词频我是分开来做的,但是假设有n个单词,我就需要遍历k次,n<=k<=2n次,于是我决定边统计单词数、同时统计词频;然后是查找需要的10组最大数据,假设有n组数据,我则需要先从map中遍历一遍,时间为O(n),一开始我对整个数据进行排序后再去取,效果很不理想,复杂时间达到了O(nlogn),但是我利用了类堆排序的方法,只需要每次判断10组就行,时间仅为O(nlog10),大大优化了运行状况。
五、代码说明
我将展示三个部分的关键代码
Main类
//利用Scanner类构建的input对文本内容进行跟踪,hasNext()是一个类似指针的结构,将指针指向当前行的下一行,这样每次循环就能一一对应每一行,并做出分析、处理等;
try(Scanner input = new Scanner(f)){
int countOfCharacters = 0;
int countOfLine = 0;
int countOfWords = 0;
while (input.hasNext()) {
String line = input.nextLine();
countOfCharacters += line.length(); //计算当前行的字符个数
countOfLine ++;
countOfWords += CountWords.countWords(line, words); //CountWords内的static方法countWords
}
CountWords类
流程图:

部分代码如下
//将内容全部变为小写,并利用正则表达式"[^\w\d]+",将本行内容分割成每一个只含数字字母字符的小段;
String mline = line.toLowerCase();
String[] words = mline.split("[^\w\d]+");
int wcount = words.length;//用于统计符合条件的单词数;
//进入循环,首先排除掉长度小于4的字符段,其次对其进行判断是否符合条件、而后统计进Map容器内;
for(int i=0; i<words.length; i++){
if(words[i].length() < 4)
wcount--;
if(words[i].length() >= 4){
char[] word = words[i].toCharArray();
int mcount = 0;
for(int j=0; j<4; j++){
if((word[j]>='0') && (word[j]<='9')){
mcount++;
}
}
//只有经历过上方循环后mcount=0才表示该字符段符合单词条件
//在Map内记录或更新单词——词频映射对
if(mcount == 0){
if(m.containsKey(words[i])){
int v = (Integer)m.get(words[i]);
v++;
m.put(words[i],v);
}
else{
m.put(words[i],1);
}
}
else{
wcount--;
}
}
}
CountMaxOfWords类
流程图:

部分代码如下
int s = m.size();
int[] a = new int[10];
a[0] = 0;
int type = 0;
String[] wd = new String[10];
/*利用Map.Entry完成对Map内的数据进行以key为基准的遍历,type为一个标准,界定于10内外;
当数组a存放了10组数据后,调用选择排序方法bbsort,将最小数据放入a[0],之后对于新的数据比较value与a[0],大于则插入,并调用bbsort;*/
for(Map.Entry<String, Integer> entry : m.entrySet()){
String k = entry.getKey();
int v = entry.getValue();
if((type < 10)&&(type != s)){
a[type] = v;
wd[type] = k;
type++;
}
if((type == s)||(type == 10)){
if(v >= a[0]){
a[0] = v;
wd[0] = k;
}
bbsort(a,wd,s);
}
}
六、异常处理
各个方法的覆盖率:
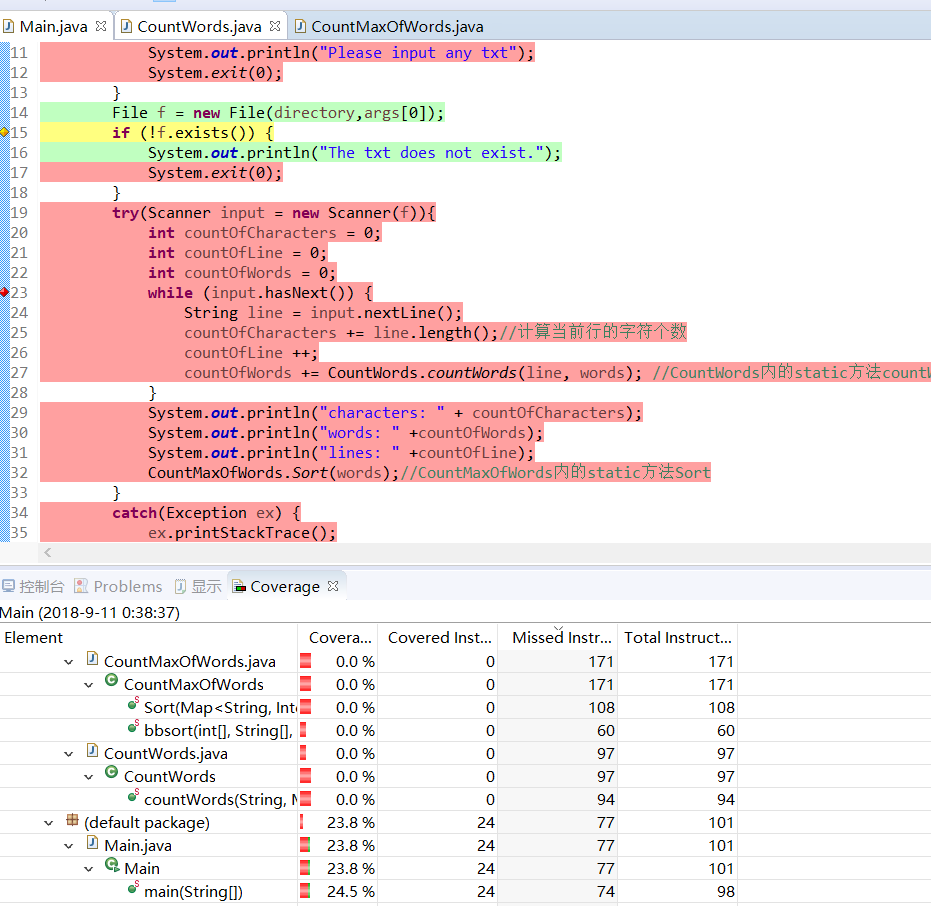
做了部分的测试:
- 传入空文件,输出结果全为0,符合预期;

- 不传入文件,输出:Please input any txt,符合预期;

- 输入错误或不存在的文件名,输出:The txt does not exist,符合预期;

- 输入单词数小于10的文件,文件内容和输出结果如下,符合预期;


七、总结
在这次课题中,我遇到得最大问题就是最新技术的学习和运用,利用这次暑假,虽然对Java有了一定程度的了解,但是JProfiler以及各种插件的使用、程序的改进、异常的处理等等,都很少去做,这次课题实打实的让我完成了一次关于与Java有关的小项目,体会到了“纸上得来终觉浅”。但是通过这次课题,自己的自学能力和代码的查错、改进能力有了不小的进步。虽然求学、求实之路不易,但是自己也在实践之中受益良多,为之后奠定了基础,也让我抱有期待。