算法思想:https://www.cnblogs.com/lliuye/p/9144312.html
随机选择k个点作为初始质心 (初始参数的K代表聚类结果的类簇数)
repeat: 将每个点指派到最近的质心,形成k个簇 (K-means是利用距离来量化相似度的)
重新计算每个簇的质心 (对簇内所有样本点求均值)
until: 质心不发生变化 (准则函数收敛)
通常采用平方误差准则:计算每个数据点的误差,即它到最近质心的欧氏距离,然后计算误差的平方和。误差平方和的值越小表示数据点越接近于它们的质心,聚类效果也越好。
关于K的选择:见https://blog.csdn.net/weixin_37536446/article/details/81326932
1、经验法:在实际的工作中,可以结合业务的场景和需求,来决定分几类以确定K值。
2、肘部法则:在使用聚类算法时,如果没有指定聚类的数量,即K值,则可以通过肘部法则来进行对K值得确定。肘部法则是通过成本函数来刻画的,其是通过将不同K值得成本函数刻画出来,随着K值的增大,平均畸变程度会不断减小且每个类包含的样本数会减少,于是样本离其重心会更近。但是,随着值继续增大,平均畸变程度的改善效果会不断减低。因此找出在K值增大的过程中,畸变程度下降幅度最大的位置所对应的K较为合理。
注:成本函数:各个类的畸变程度之和与其内部成员位置距离的平方和,最优解是以成本函数最小化为目标。公式如下:
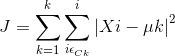 ,其中
,其中是第k个质心的位置
3、规则法:K= (此种方法存在一定的缺点:可能导致聚类的数目较大)
关于该算法的优缺点及改进:见https://blog.csdn.net/u011204487/article/details/59624571
K均值算法中:当聚类的样本点中有“噪声”(离群点)时,在计算类簇质点的过程中会受到噪声异常维度的干扰,造成所得质点和实际质点位置偏差过大,从而使类簇发生“畸变”。
K中心点算法(K-medoids)提出了新的质点选取方式,而不是简单像k-means算法采用均值计算法。
在K中心点算法中,每次迭代后的质点都是从聚类的样本点中选取,而选取的标准就是当该样本点成为新的质点后能提高类簇的聚类质量,使得类簇更紧凑。
该算法使用绝对误差标准来定义一个类簇的紧凑程度。