ALS算法参数:
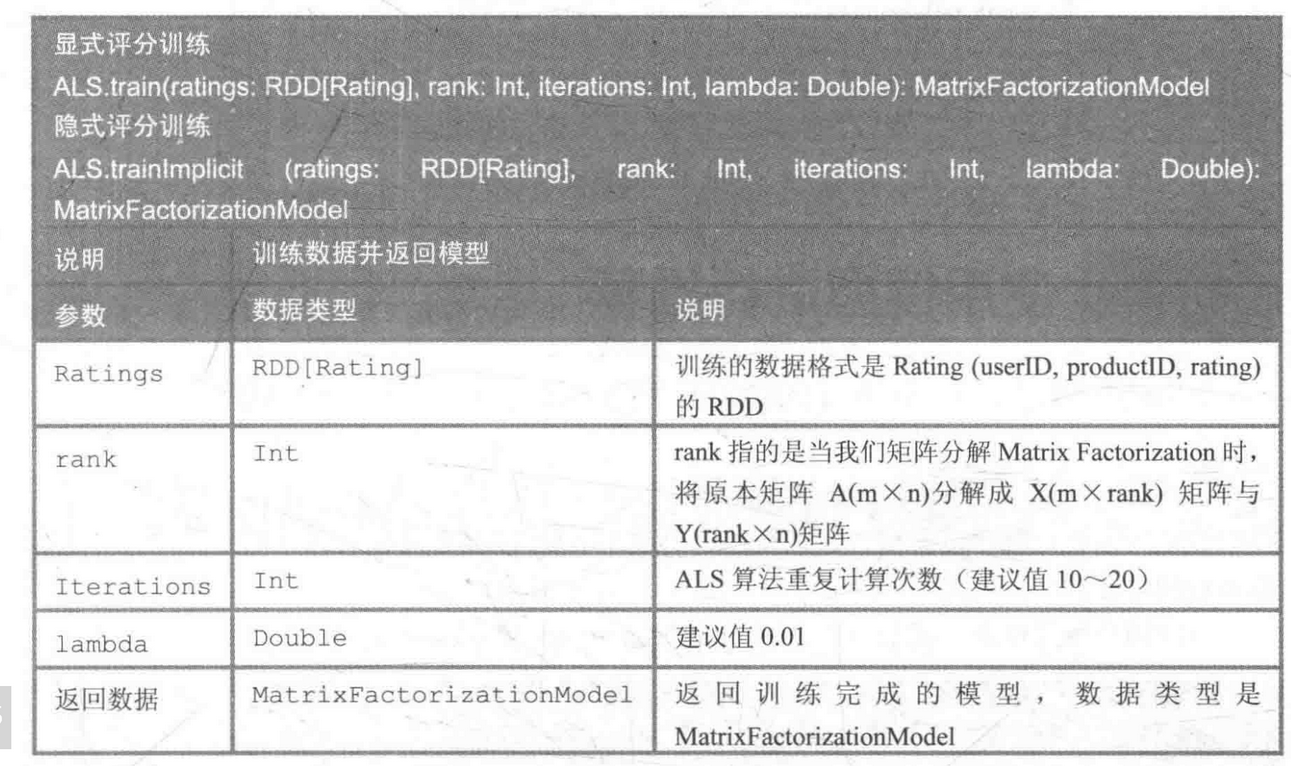
// ALS关键代码
val model =ALS.train(训练集,rank,循环次数iter,lambda)
那是怎么想到要这样设置的呢?那就要在了解算法的基础上来设置此参数;
1、训练集,数据格式:(用户id 物品id 评分(0-1) )
2、rank,根据数据的分散情况测试出来的值,特征向量纬度,如果这个值太小拟合的就会不够,误差就很大;如果这个值很大,就会导致模型大泛化能力较差;所以就需要自己把握一个度了,一般情况下10~1000都是可以的;
3、循环次数iter,这个设置的越大肯定是越精确,但是设置的越大也就意味着越耗时;
4、 lambda也是和rank一样的,如果设置很大就可以防止过拟合问题,如果设置很小,其实可以理解为直接设置为0,那么就不会有防止过拟合的功能了;怎么设置呢?可以从0.0001 ,0.0003,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10这样每次大概3倍的设置,先大概看下哪个值效果比较好,然后在那个比较好的值(比如说0.01)前后再设置一个范围,比如(0.003,0.3)之间,间隔设置小点,即0.003,0.005,0.007,0.009,0.011,,,,。当然,如果机器性能够好,而且你够时间,可以直接设置从0到100,间隔很小,然后一组参数一组的试试也是可以的。
模型修改策略
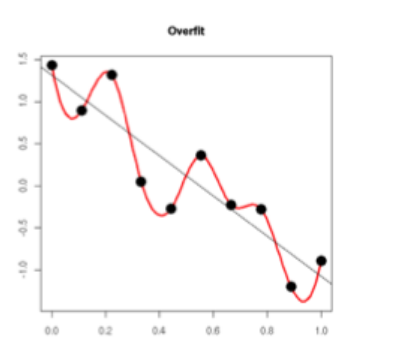
过拟合:增大数据规模、减小数据特征数(维数)、增大正则化系数λ
欠拟合:增多数据特征数、添加高次多项式特征、减小正则化系数λ