struts2部分
一、struts2框架的集成:
1.web.xml配置struts2过滤器:前端控制器、核心控制器 如果有多个过滤器,需要将该过滤器放置到最后一个
2.struts.xml配置:主要是配置action,根据该配置,可以让前端请求找到对应的action的位置。
2.1package标签:
可以继承框架提供的package包,帮助我们扩展package的功能,提供访问action的副父级路径,package可以继承多个包
2.2action标签:
配置actioon对象。name,action的访问路径。class,action的类型。method,action要调用的方法
2.3 result标签:
一般负责视图的跳转。name,视图的逻辑名称。type,跳转的方式
2.4 include标签
包含其他的配置文件。file:要办韩文件的路径
2.5 constant标签
设置常量,覆盖default.properties文件中对应的常量。name,常量名。value,常量值。
2.6 param标签
设置action的初始变量值,result中可以设置返回数据。
(1)excludenullPrpperties,是否序列化空的属性
(2)includeProperties 需要序列化的属性
(3)excludeProperties 不需要序列化的属性
(4)namespace 配置跳转页面的命名空间
(5)actionName配置跳转action的名字
3. Action类:POJO,实现Action接口,继承自ActionSupport,作用对前端的请求进行业务逻辑处理。
二、struts2框架的简单的运行流程:
前端发起请求-->请求经过过滤器StrutsPrepareAndExecuteFilter-->过滤器会扫描struts.xml文件-->根据xml文件创建对应action的invocation对象-->通过invocation对象执行action中对应的方法,返回视图的逻辑名称-->根据返回的视图的逻辑名称在struts.xml文件中找到对应的result-->根据result中的视图相对路径,找到result中的视图-->将该视图返回给前端界面。
三、strut2的六大配置文件:
(1)default.properties
(2)struts-default.xml
(3)struts-plugn.xml
(4)struts.xml
(5)struts.properties
(6)web.xml
四、struts2中对servletAPI的使用:
(1)实现Aware接口
(2)通过servletActionContext静态方法
(3)通过ActionContext获取
(4)起主要作用的拦截器ServletConfig
五、struts2接收前端传递过来数据的方式:
(1)通过action的成员变量接收
(2)定义一个model类,前端传递参数时候,通过ognl表达式来提取
(3)通过实现modelDriver接口,将前端提交的参数,赋值给model对象的成员变量
(4)接收前端传递过来的数据为数组(数组中的元素是String或者是Model类)或者集合
六、struts2返回给前端json数据
(1)使用struts2的一个json插件:struts-json-plugin.jar
(2)负责处理json数据返回的 配置文件中的package要继承自json-default包
(3)负责返回json数据的result需要将type设置为json
(4)负责返回json数据的result标签中如果没有内容,则将action中所有提供了get方法的成员变量,都转换成json对象返回给前端
(5)result的子标签param
Spring、SpringMVC、Mybatis部分
一、Spring
1、Spring 在ssm中起什么作用?
Spring:轻量级框架
作用:Bean工厂,用来管理Bean的生命周期和框架集成。
两大核心:
(1)IOC/DI(控制反转/依赖注入) :把dao依赖注入到service层,service层
反转给action层,Spring顶层容器为BeanFactory。
(2)AOP:面向切面编程
2、Spring的事务?
(1)编程式事务管理:编程方式管理事务,极大灵活性,难维护。
(2)声明式事务管理:可以将业务代码和事务管理分离,用注解和xml配置来管理事务。
3、IOC 在项目中的作用?
作用:Ioc解决对象之间的依赖问题,把所有Bean的依赖关系通过配置文件或注解关联起来,降低了耦合度。
4、Spring的配置文件## 标题中的内容?
(1)开启事务注解驱动
(2)事务管理器
(3)开启注解功能,并配置扫描包
(4)配置数据库
(5)配置SQL会话工厂,别名,映射文件
(6)不用编写Dao层的实现类
5、Spring下的注解?
(1)注册:@Controller @Service @Component
(2)注入:@Autowired @Resource
(3)请求地址:@RequestMapping
(4)返回具体数据类型而非跳转:@ResponseBody
6、Spring DI 的三种方式?
(1)构造器注入:通过构造方法初始化
<constructor-arg index="0" type="java.lang.String" value="宝马"></constructor-arg>
(2)setter方法注入:通过setter方法初始化
<property name="id" value="1111"></property>
(3)接口注入
7、Spring主要使用了什么模式?
(1)工厂模式:每个Bean的创建通过方法
(2)单例模式:默认的每个Bean的作用域都是单例
(3)代理模式:关于Aop的实现通过代理模式
8、IOC,AOP的实现原理?
(1)IOC:通过反射机制生成对象注入
(2)AOP:动态代理
二、SpringMVC
1、SpringMvc 的控制器是不是单例模式,如果是,有什么问题,怎么解决?
问题:单例模式,在多线程访问时有线程安全问题
解决方法:不要用同步,在控制器里面不能写字段
2、SpringMvc 中控制器的注解?
@Controller:该注解表明该类扮演控制器的角色
3、@RequestMapping 注解用在类上的作用?
作用:用来映射一个URL到一个类或者一个特定的处理方法上
4、前台多个参数,这些参数都是一个对象,快速得到对象?
方法:直接在方法中声明这个对象,SpringMvc就自动把属性赋值到这个对象里面
5、SpringMvc中函数的返回值?
String,ModelAndView,List,Set 等
一般String,Ajax请求,返回一个List集合
6、SpringMvc中的转发和重定向?
转发:return:“hello”
重定向 :return:“redirect:hello.jsp”
7、SpringMvc和Ajax之间的相互调用?
通过JackSon框架把java里面对象直接转换成js可识别的json对象,具体步骤如下:
(1)加入JackSon.jar
(2)在配置文件中配置json的映射
(3)在接受Ajax方法里面直接返回Object,list等,方法前面需要加上注解@ResponseBody
8、SpringMvc的工作流程图?
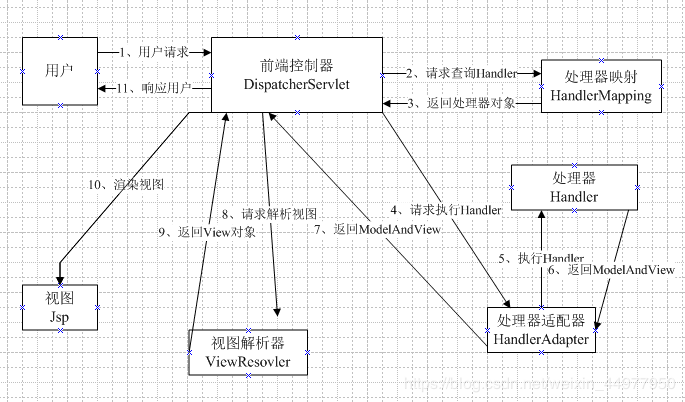
9、Struts2 和 SpringMvc的区别?
(1)入口不同:
Struts2:filter过滤器
SpringMvc:一个Servlet即前端控制器
(2)开发方式不同:
Struts2:基于类开发,传递参数通过类的属性,只能设置为多例
SpringMvc:基于方法开发(一个url对应一个方法),请求参数传递到方法形参,可以为单例也可以为多例(建议单例)
(3)请求方式不同:
Struts2:值栈村塾请求和响应的数据,通过OGNL存取数据
SpringMvc:通过参数解析器将request请求内容解析,给方法形参赋值,将数据和视图封装成ModelAndView对象,最后又将ModelAndView中的模型数据通过request域传输到页面,jsp视图解析器默认使用的是jstl。
三、Mybatis
1、Ibatis和Mybatis?
(1)Ibatis:2010年,apache的Ibatis框架停止更新,并移交给了google团队,同时更名为MyBatis。从2010年后Ibatis在没更新过,彻底变成了一个孤儿框架。一个没人维护的框架注定被mybatis拍在沙滩上。
(2)Mybatis:Ibatis的升级版本。
2、什么是Mybatis的接口绑定,有什么好处?
Mybatis实现了DAO接口与xml映射文件的绑定,自动为我们生成接口的具体实现,使用起来变得更加省事和方便。
3、什么情况用注解,什么情况用xml绑定?
(1)注解使用情况:Sql语句简单时
(2)xml绑定使用情况:xml绑定 (@RequestMap用来绑定xml文件)
4、Mybatis在核心处理类叫什么?
SqlSession
5、查询表名和返回实体Bean对象不一致,如何处理?
映射键值对即可
<result column="title" property="title" javaType="java.lang.String"/>
column:数据库中表的列名
property:实体Bean中的属性名
6、Mybatis的好处?
(1)把Sql语句从Java中独立出来。
(2)封装了底层的JDBC,API的调用,并且能够将结果集自动转换成JavaBean对象,简化了Java数据库编程的重复工作。
(3)自己编写Sql语句,更加的灵活。
(4)入参无需用对象封装(或者map封装),使用@Param注解
7、Mybatis配置一对多?
<collection property="topicComment" column="id"
ofType="com.tmf.bbs.pojo.Comment" select="selectComment" />
(1)property:属性名
(2)column:共同列
(3)ofType:集合中元素的类型
(4)select:要连接的查询
8、Mybatis配置一对一?
<association property="topicType" select="selectType"
column="topics_type_id" javaType="com.tmf.bbs.pojo.Type"/>
(1)property:属性名
(2)select:要连接的查询
(3)column:共同列
(4)javaType:集合中元素的类型
9 、${} 和 #{}的区别?
(1):简单字符串替换,把 {}:简单字符串替换,把:简单字符串替换,把{}直接替换成变量的值,不做任何转换,这种是取值以后再去编译SQL语句。
(2)#{}:预编译处理,sql中的#{}替换成?,补全预编译语句,有效的防止Sql语句注入,这种取值是编译好SQL语句再取值。
(3)总结:一般用#{}来进行列的代替
10、获取上一次自动生成的主键值?
select last _insert_id()
11、Mybatis如何分页,分页原理?
RowBounds对象分页
在Sql内直接书写,带有物理分页
12、Mybatis工作原理?
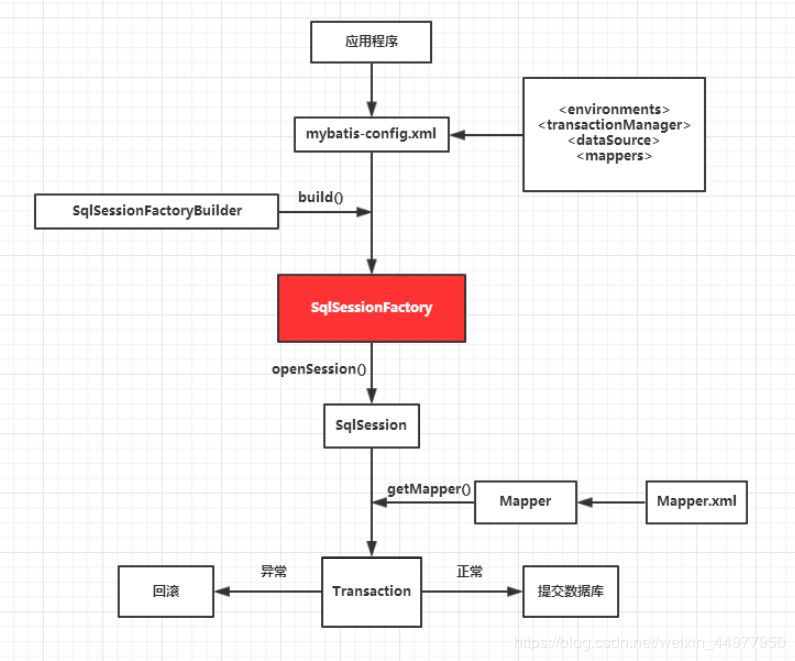
原理:
(1)通过SqlSessionFactoryBuilder从mybatis-config.xml配置文件中构建出SqlSessionFactory。
(2)SqlSessionFactory开启一个SqlSession,通过SqlSession实例获得Mapper对象并且运行Mapper映射的Sql语句。
(3)完成数据库的CRUD操作和事务提交,关闭SqlSession。
Hibernate部分
一、关于Hibernate映射
关于Hibernate的映射要说明的一点就是关于ID的访问权限,property以及field的区别。以前使用的时候根本没有注意过这个问题,这里简单的强调一下。
表的主键在内存中对应一个OID对象描述标识符,需要在xml的配置文件中要指定对象标识符的生成方式。
assinged是自然主键的方式,这种策略需要用户指定ID才可以,在这个知识点里先忽略。
其他的方式比如sequence通过序列生成主键。identity,increment等是自动增长。这种方式生成的主键一般是由hibernate完成的,所以我们在编写实体对象的时候,id的get和set方法权限应该注意:
class XXX{
private long id;
public long getId();
private void setId();
}
这里应该设置get的访问权限是public的,set的访问权限是private的。由于hibernate在访问实体模型时,是不考虑权限的,因此这样就避免了用户指定主键。
另外一个知识点就是,如果不通过property指定一个列,而使用field。那么hibernate就会直接访问属性,而不会通过get set访问属性。
二、关于对象映射标识符OID
这一块相对来说也是hibernate的重点,什么是OID?如何指定OID?OID与主键是什么关系?
1、什么是OID?
OID 全拼是object identifier,也就是对象标识符。因为数据库表中一般都通过主键来识别一个表中的不同行,而JVM中一般使用地址来识别不同的对象。在Session缓存中,当然也需要一个标识符来表示不同的缓存对象。因此,OID也就排上了用场。
由于涉及到缓存的概念,就先说一下缓存
上节说过,SessionFactory是重量级的缓存,里面包含了数据库的连接,预定义的SQL等等。而Session的缓存是轻量级的,里面包含一些增删改查的对象。
如果同一个JVM中的对象,加入到不同的session中,也是不同的缓存对象。而不同的对象加入到同一个Session中,也需要保证OID不同。因为Session不管你存的是什么,都需要通过对象标识符来检索对象。
2、如何指定OID?
通常分为两种:
1 自然主键,也就是带有业务含义的,比如学生的学号,工作的编号,通常包含了年份,部门或者班级,专业等等业务上的意义,因此需要手动的合成或者拼接指定。这种情况下就需要使用assinged方式,这种方式如果不指定主键就提交缓存进行更新,会报错!
2 代理主键,也就是没有业务含义的,通常是通过编码自动生成的。
(1)increment:不依赖于底层数据库,适合单个数据库场合不适合集群,必须为long int short类型。插入式,先选择最大的id值,再加1
(2)identity:依赖底层数据库系统。支持自动增长字段: OID 为long,int,short
(3)sequence:MYSQL不支持序列。依赖底层,必须支持序列。Oracle db2 sap db postgresql
(4)hilo:计算公式hi*(max_lo+1)+lo 不依赖底层数据库系统,Long,int,short,只能在一个数据库中保持唯一
(5)native:跨平台,自动选择使用哪个策略。
由于上面的identity,sequence都需要依赖于底层数据库,不同的数据库可能不支持这种方式。那么一般推荐使用native,自动进行选择。
3、OID与主键是什么关系?
一般来说,OID就是一个对象持久化之前是null,持久化的时候hibernate或者我们手动指定一个id,这个ID被插入到数据库当做主键,在session中当做索引。也因为这个原因,需要保证OID与主键的一致性,比如类型啊,长度之类的。
三、关于Session缓存——清理缓存
缓存的概念,一般学过基础理论的都应该理解,就是为了缓冲数据,减少与真实数据库的频繁交互。与计算机的缓存类似,经常访问硬盘效率太低,IO太慢,就把内存当做缓存,CPU每次与内存直接交互,内存中找不到的数据再去读硬盘。内存又觉得慢了,就弄个Cahce当做缓存,经常访问的数据再放到这里,更加快了速度。
Session缓存也是如此,与Web中的Session也类似。在网页中,也有Session这样一种概念,比如我们登陆淘宝,会记录我们的用户信息,当浏览器关闭或者退出时,Session关闭。这期间就完全通过Session来识别用户的身份,无需每次登陆进行校验。Hibernate中也是如此,我们从SessionFactory中开启这个Session,持久化一个对象,然后提交事务,增删改查,最后关闭Session,就像一个对话一样。
1、那么Session缓存具体有什么作用呢?
比如我们通过Session.get(xxx.class,new Long(1));来获取Session中OID为1的对象,它会首先到缓存中查找,如果找到了就直接用。如果找不到就去读取数据库,然后存储到缓存中!第二次,就可以直接从缓存中获取数据了!
这样就减少了访问数据库的频率!
另外,我们频繁的修改一个对象,如果这个对象放在缓存中,而且还是用了事务,那么只有事务在commit的时候,才会执行真正的SQL语句!
这样就对对象与数据库的表进行了动态的映射!
2、Session缓存又是什么时候提交清理的呢?
(1) 当使用事务时,transaction.commit()会触发缓存的清理。
(2)直接调用Session.flush()也会触发缓存的清理。
(3)如果使用的是native,那么在持久化的时候也会清理缓存,也就是session.save()时。
(4) 执行查询时。
这里就不得不提一下commit与Session的flush的区别了:
当使用flush时,并没有提交事务,只是清理缓存而已。
而commit的时候,是先调用flush再提交事务。
四、关于Session中的方法使用
1、save()
Session调用save时,一般都是创建或者获取到了一个瞬时态的对象,这时对象的OID有可能是空的,session需要指定生成一个OID。再计划生成一条insert语句,这条语句只是简单的缓存起来,当事务提交时才执行。而持久化的对象,OID是不能随便更改的,这也是为什么前面的setId推荐设置成private的访问权限。
2、load()和get()
他们都是加载一个对象,或者从缓存中查找。区别在于,如果使用load,如果数据库中不存在该对象对应的数据,会抛出异常。而get会得到null。
3、update()
这个方法是把一个游离态的对象持久化,比如一个对象如果session清理了,那么session中就找不到这个对象了,但是数据库中仍然存在。我们通过这个对象的引用,可以通过update在Session中创建它的实例。这样,会生成一条update语句。如果此后在修改无论多少次,都只会生成一条update语句。总结起来就是,update方法,会生成一条对应的update语句来同步缓存与数据库中的对象。
如果数据库中对应的表设置了触发器,那么就蛋疼了、!因为无论你是否修改了数据,都会生成一条update语句,这样就会导致触发了大量无效的触发器。不要担心,可以通过设置select-before-update属性,一看名字就能猜到,是在update前,进行一次select,如果数据一致,就必须要update了,如果数据不一致,才update。
4、saveOrUpdate()
这个方法就给力了,它会自动判断传入的参数是什么类型的,然后采取什么措施!完全的自动化,最喜欢这样的了!跟native一个套路。
5、merge()
对象的复制,它首先获取到OID,然后去session中查找是否存在这样的对象,如果存在直接修改或者使用;如果不存在,就复制这个对象的属性。
6、delete()
如果删除的对象时一个游离态的对象,那么需要先进行持久化,在删除。
7、replicate()
这个方法可以跨Sessionfactory拷贝对象。
这次的总结,大致就是以上内容。后续还会继续总结常用的知识点。
Spring Boot部分
一、什么是SpringBoot
描述:Spring Boot是Spring社区发布的一个开源项目,旨在帮助开发者快速并且更简单的构建项目。大多数SpringBoot项目只需要很少的配置文件。
二、SpringBoot核心功能
1、独立运行Spring项目
Spring boot 可以以jar包形式独立运行,运行一个Spring Boot项目只需要通过java -jar xx.jar来运行。
2、内嵌servlet容器
Spring Boot可以选择内嵌Tomcat、jetty或者Undertow,这样我们无须以war包形式部署项目。
3、提供starter简化Maven配置
spring提供了一系列的start pom来简化Maven的依赖加载,例如,当你使用了spring-boot-starter-web,会自动加入如图5-1所示的依赖包。
4、自动装配Spring
SpringBoot会根据在类路径中的jar包,类、为jar包里面的类自动配置Bean,这样会极大地减少我们要使用的配置。当然,SpringBoot只考虑大多数的开发场景,并不是所有的场景,若在实际开发中我们需要配置Bean,而SpringBoot灭有提供支持,则可以自定义自动配置。
5、准生产的应用监控
SpringBoot提供基于http ssh telnet对运行时的项目进行监控。
6、无代码生产和xml配置
SpringBoot不是借助与代码生成来实现的,而是通过条件注解来实现的,这是Spring4.x提供的新特性。
三、SpringBoot优缺点
优点:
1、快速构建项目。
2、对主流开发框架的无配置集成。
3、项目可独立运行,无须外部依赖Servlet容器。
4、提供运行时的应用监控。
5、极大的提高了开发、部署效率。
6、与云计算的天然集成。
缺点:
1、如果你不认同spring框架,也许这就是缺点。
四、SpringBoot特性
1、创建独立的Spring项目
2、内置Tomcat和Jetty容器
3、提供一个starter POMs来简化Maven配置
4、提供了一系列大型项目中常见的非功能性特性,如安全、指标,健康检测、外部配置等
5、完全没有代码生成和xml配置文件
五、SpringBoot快速搭建
网址:http://start.spring.io;
六、SpringBoot CLI
SpringBoot CLI 是SpringBoot提供的控制台命令工具。
七、SpringBoot maven 构建项目
spring-boot-starter-parent:是一个特殊Start,它用来提供相关的Maven依赖项,使用它之后,常用的包依赖可以省去version标签。
八、SpringBoot几个常用的注解
(1)@RestController和@Controller指定一个类,作为控制器的注解
(2)@RequestMapping方法级别的映射注解,这一个用过Spring MVC的小伙伴相信都很熟悉
(3)@EnableAutoConfiguration和@SpringBootApplication是类级别的注解,根据maven依赖的jar来自动猜测完成正确的spring的对应配置,只要引入了spring-boot-starter-web的依赖,默认会自动配置Spring MVC和tomcat容器
(4)@Configuration类级别的注解,一般这个注解,我们用来标识main方法所在的类,完成元数据bean的初始化。
(5)@ComponentScan类级别的注解,自动扫描加载所有的Spring组件包括Bean注入,一般用在main方法所在的类上
(6)@ImportResource类级别注解,当我们必须使用一个xml的配置时,使用@ImportResource和@Configuration来标识这个文件资源的类。
(7)@Autowired注解,一般结合@ComponentScan注解,来自动注入一个Service或Dao级别的Bean
(8)@Component类级别注解,用来标识一个组件,比如我自定了一个filter,则需要此注解标识之后,Spring Boot才会正确识别。
spring 启动方式
CLI启动 如:
Spring Boot 以 jar 包方式运行在后台
java -jar spring-boot01-1.0-SNAPSHOT.jar > log.file 2>&1 &
如果8080端口被占用,则:
netstat -ano|findstr 8080
taskkill /pid 2552 -f
Git部分
一、什么是git
代码管理工具,分布式管理,每个人电脑都是一个完整的版本库。并且有中央服务器(gitHub,gitLab)提供代码交换修改
二、git基础概念
1、工作区:自己的项目(有一个隐藏目录 ".git" 的文件)
2、stage暂存区(git add .之后就进入暂存区)
3、本地仓库(包含了本地的各种分支)
4、远程仓库(默认:origin)
5、分支:默认每个仓库都有一个master分支,也是我们的工作的一条线,git仓库则是由无数个分支组成
6、在git中HEAD表示当前版本指针
三、常用git指令
1、git add name(单个) || git add .(全部) : 工作区 ==> 暂存区
2、git commit -m "message" : 暂存区 ==> 本地分支
3、git push origin branchName : 本地分支 ==> 远程分支
4、git pull : 拉取关联了本地分支的远程分支的最新内容
5、git status : 用于显示工作目录和暂存区的状态
6、git rm file : 删除一个文件
7、git clone 项目地址 : 克隆一个项目
8、git remote 查看远程仓库信息
9、get remote -v 显示可以拉取和推送的origin的地址。如果没有推送权限,就看不到push地址
四、查看git操作信息
1、git log 查看log
2、git log 显示log详细信息
3、git log --pretty=oneline(更加简洁清晰的显示)
4、git reflog 记录了所有命令变更状态
5、git log --graph --pretty=oneline --abbrev-commit 查看分支合并图
五、分支
1、基础操作
(1)、git checkout -b 本地分支名 origin 远程分支名 :创建分支
(2)、git branch -a : 查看本地分支和远程分支
(3)、git branch -r : 查看远程分支
(4)、git branch : 查看本地分支
(5)、git branch -d 分支名 : 删除本地分支
(6)、git push origin --delete 远程分支名
2、合并分支操作
假设develop为最新分支,我们需要更新当前分支为最新的develop
1. git fetch origin develop:develop 更新develop为最新
2. git merge develop 把最新的develop更新到当前分支中
3. 如果有冲突就解决冲突后重新commit push等操作
六、缓存区操作
假设我们现在编写了很多代码,但是又不愿意commit,但是这个时候又需要切换到其它分支进行操作,那么此时就可以用上stash了
1、把我们写的内容保存起来,执行命令git stash
2、然后切换到其它分支去工作,工作完成后切换到当前分支来
3、执行 git stash list 查看缓冲区有哪些内容
4、恢复之前的工作内容:git stash apply(恢复最后一条stash里面的工作内容,并且stash中还保存着)
5、或者使用 git stash pop 恢复最后一条stash的工作内容,且stash中不再保存了
6、也可以执行 git stash apply stash@{0} 来恢复指定的stash工作内容
最后再介绍一条:git stash drop stash@{0} 来移除指定的stash里面已经没有用的内容。
七、rebase操作流程
假设develop为最新分支,我们所在的分支名为cur分支,现在我们想要把develop的最新内容更新到cur分支上。
条件:我们现在所处的分支是cur分支
1. 拉取最新develop:git fetch origin develop:develop
2. git rebase develop
3. 如果有冲突的话,处理好冲突
4. git add .
5. git rebase --continue
6. git push -f (这里必须要强制推送)
八、cherry-pick操作
假设我们现有release/1.0分支,我们所在的分支为cur分支,按照git flow 的分支管理方式,我们需要把cur分支合并到develop分支上的同时,我们还需要cherry-pick一份到release/1.0
1、git log 找到我们即将要cp的 commitID 假设(4b16df9cdf46159ceac7a5489b3da8eb5486034b)
2、切换到release/1.0分支上(git checkout release/1.0)
3、执行命令: git cherry-pick 4b16df9cdf46159ceac7a5489b3da8eb5486034b
4、查看是否有冲突,如果有冲突就解决冲突(假设有冲突)如果没有冲突的话就直接git push结束
5、解决完冲突后,git add .
6、git cherry-pick --continue
7、git push 操作
九、后悔药
1、暂存区后悔
git reset HEAD <filename> 这个是把暂存区的修改返回到工作区
git checkout --filename 丢弃工作区,回到上一次commit的状态
2、本地仓库后悔
git reset --hard origin/分支名 : 放弃所有修改,同步远程仓库
git reset --hard HEAD^ : 回退到上一次commit的状态
git reset --hard commitId : 回退到任意commitId
十、常见问题
1、当我们在gitLab上面创建了一个新分支,为什么使用命令行是看不到的?
需要先git fetch 更新一下
十一、小结
本文让我们初步了解了git是什么,且理解了git的四个核心的概念:工作区,暂存区,本地仓库,远程仓库。其实我们对于git的操作无非就是分支,把分支在这4个区中不断的变更位置,做错了就回退位置,做完了就合并到其它分支上去的一个过程。