HTTP协议:
HTTP(Hypertext Transfer Protocol):即超文本传输协议。URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源的操作:

Requests库提供了HTTP所有的基本请求方式。官方介绍:http://www.python-requests.org/en/master
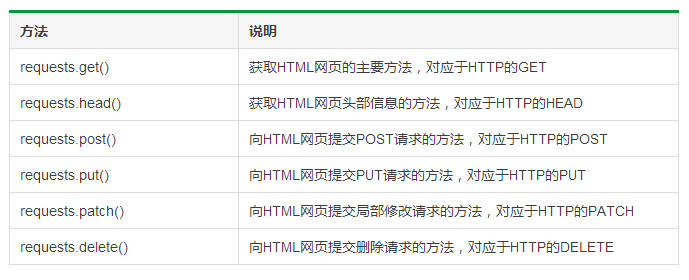
Requests库的6个主要方法:
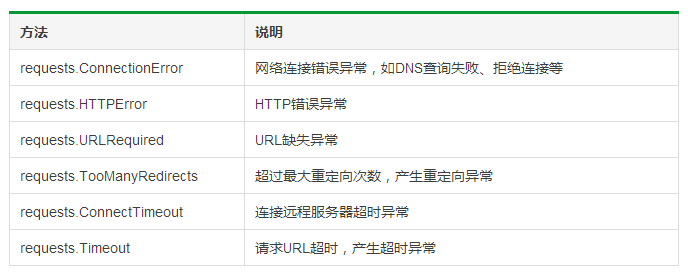
Requests库的异常:
Requests库的两个重要对象:Request(请求)、Response(相应)。Request对象支持多种请求方法;Response对象包含服务器返回的所有信息,也包含请求的Request信息。
Response对象的属性:

其中,r.encoding指:如果header中不存在charset,则认为编码为ISO‐8859‐1。
r.raise_for_status()可以直接知道r.status_code是否等于200。
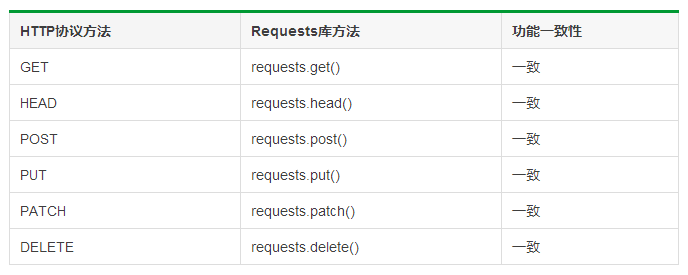
HTTP协议与Requests库对比:
爬取网页的通用代码框架:
1 try: 2 r = requests.get(url,timeout = 30) 3 r.raise_for_status() 4 # 如果状态不是200,引发HTTPError异常 5 r.encoding = r.apparent_encoding 6 return r.text 7 except: 8 return '产生异常'
例如,获取PMCAFF首页的信息:
1 import requests 2 3 def getHtmlText(url): 4 try: 5 r = requests.get(url,timeout = 30) 6 r.raise_for_status() 7 r.encoding = r.apparent_encoding 8 return r.text 9 except: 10 return '产生异常' 11 12 if __name__ == '__main__': 13 url = 'https://www.pmcaff.com/' 14 print(getHtmlText(url))
爬取网页的通用代码框架:操作环境:win,Python 3.6
参考资料:中国大学MOOC课程《Python网络爬虫与信息提取》