最小生成树是图这一数据结构里最常讨论的方面之一。
先用一下几个概念回忆一下什么是最小生成树:
连通图:任意两个结点之间都有一个路径相连
生成树(Spannirng Tree):连通图的一个极小的连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边
最小生成树(Minimum Spannirng Tree):连通图的最小代价的生成树(各边的权值之和最小)
最小生成树性质(MST性质):
设G=(V,E)是一个连通网络,U是顶点集V的一个真子集。若(u,v)是G中一条“一个端点在U中(例如:u∈U),另一个端点不在U中的边(例如:v∈V-U),且(u,v)具有最小权值,则一定存在G的一棵最小生成树包括此边(u,v)。
证明:http://fdcwqmst.blog.163.com/blog/static/164061455201010392833100/
构造最小生成树的两种方法:Prim算法和Kruskal算法。它们都利用了MST性质;都使用贪心策略,一次生成一条权值最小的“安全边”。
下面看一下Prim算法的具体内容。
算法思想:
1. 从图中选取一个节点作为起始节点(也是树的根节点),标记为已达;初始化所有未达节点到树的距离为到根节点的距离;
2. 从剩余未达节点中选取到树距离最短的节点i,标记为已达;更新未达节点到树的距离(如果节点到节点i的距离小于现距离,则更新);
3. 重复步骤2直到所有n个节点均为已达。
上述过程应该是很清晰的,下面看一下Prim算法的C语言实现:


#define N 10 // 定义最大节点数,实际有几个是几个 #define MAXDIST 100 // 最大距离,表示两个节点间不可达, 为了输入方便设置成100,实际可用INT_MAX // 为了计算方便传入的距离矩阵用指针数组的格式,n是节点数 int Prim(int (*map)[N], int n) { int i, j; int minDist, minIndex, totalWeight; int *visited, *parent, *dist; // 分别保存节点的已达标志,父节点,到树的距离 // 申请空间并清零 visited = (int *)malloc(n * sizeof(int)); parent = (int *)malloc(n * sizeof(int)); dist = (int *)malloc(n * sizeof(int)); memset(visited, 0, n * sizeof(int)); memset(parent, 0, n * sizeof(int)); memset(dist, 0, n * sizeof(int)); // 初始化,设置节点0为根节点 visited[0] = 1; totalWeight = 0; // 初始化未达节点到树的距离 for (i = 1; i < n; ++i) { parent[i] = 0; dist[i] = map[0][i]; } printf(" Edge Weight "); // n - 1次循环找出n - 1条边 for (i = 0; i < n - 1; ++i) { minDist = MAXDIST; minIndex = i; // 找出到树距离最小的节点 for (j = 1; j < n; ++j) { if (visited[j] == 0 && dist[j] < minDist) { minDist = dist[j]; minIndex = j; } } if (minIndex == i) // 所有节点到树的距离都为MAXDIST,说明不是连通图,返回 { printf("This is not a connected graph! "); return MAXDIST; } // 标记并输出找到的节点和边 visited[minIndex] = 1; totalWeight += minDist; printf("%d-->%d %3d ", parent[minIndex], minIndex, map[parent[minIndex]][minIndex]); // 更新剩余节点到树的距离 for (j = 1; j < n; ++j) { if (visited[j] == 0 && map[j][minIndex] < dist[j]) { parent[j] = minIndex; dist[j] = map[j][minIndex]; } } } printf(" Total Weight: %d ", totalWeight); return totalWeight; }
再写一个测试函数验证一下功能:
1 int main()
2 {
3 int map[N][N];
4 int i, j;
5 int n, tmp;
6
7 printf("Num of nodes: ");
8 scanf("%d", &n);
9
10 printf("Distance matrix (lower triangular) : ");
11 for (i = 1; i < n; ++i)
12 {
13 map[i][i] = 0;
14
15 for (j = 0; j < i; ++j)
16 {
17 scanf("%d", &tmp);
18 map[i][j] = tmp;
19 map[j][i] = tmp;
20 }
21 }
22
23 Prim(map, n);
24
25 return 0;
26 }
测试图的距离矩阵如下:
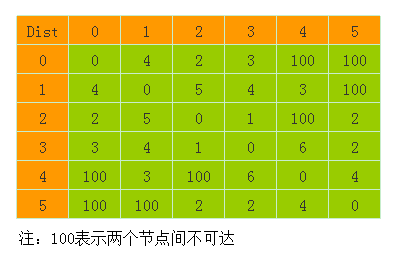
因为无向图矩阵是对称的,所以程序中设置只要输入下三角数据即可,也就是下面这些:

也就是输入的数据是这些: 4 2 5 3 4 1 100 3 100 6 100 100 2 2 4
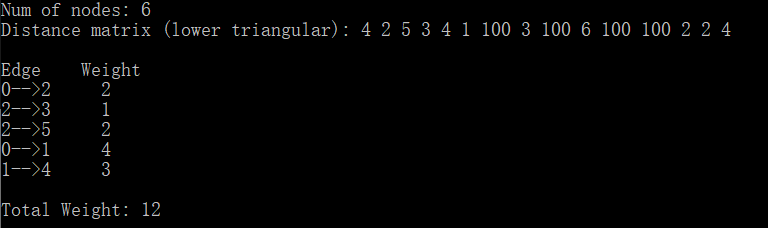
下面是程序运行截图:
算法效率 O(n^2):
很明显对于每个节点(初始节点除外),都要进行此次遍历查找距离树最近的节点 O(n),和一次更新操作O(n),所以总的时间复杂度为O(n^2)。
优化:
上述过程中,冗余操作在于对已经标记为可达的节点,在每次遍历查找和更新时,都还要访问一次。优化的关键就在于如何避免这种操作。
使用优先队列(Priority Queue),或叫堆(Heap),将每次更新的节点加入到队列中,而且保证队列有一定的大小顺序(每次调整的时间复杂度O(logn))。而查找具有最小距离的元素,只需要取队列首个元素再调整队列(O(logn))。所以取出n个节点,总的时间复杂度为O(nlogn)。
很明显这是空间换时间的策略,效果相当可观。但是在数据量大的情况下,可能会因为内存不足而无法工作。