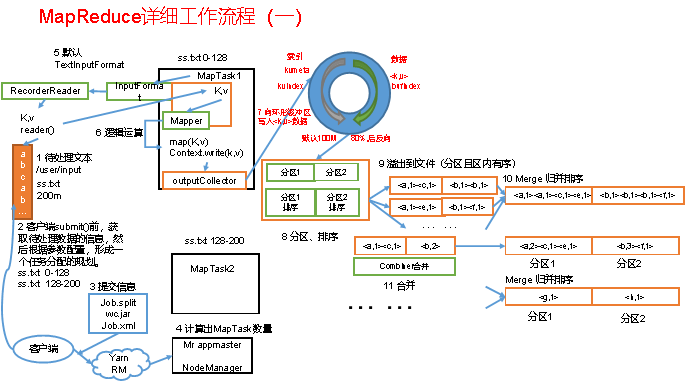
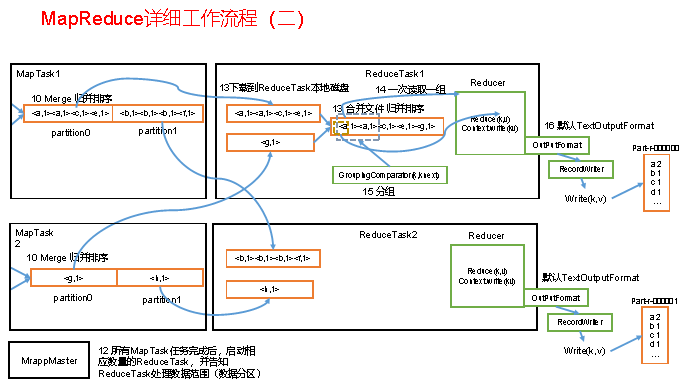
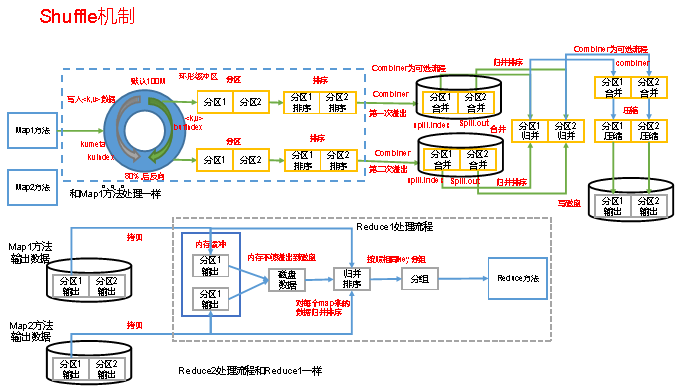
简单描述Shuffle过程环形缓冲区的作用?
key,value从map()方法输出,被outputcollector收集通过getpartitioner()方法获取分区号,在进入环形缓冲区。默认情况下,环形缓冲区大小值为100MB。当map输入的数据进入环形缓冲区的量达到80MB以上时,那么开始执行溢写过程,溢写过程中如果有其他数据进入,那么由剩余的百分之20反向写入。溢写过程会根据key,value先进行分区,后进行排序,最终maptask溢写文件经过归并排序后落入本地磁盘,reduceTask将多个mapTask下相同分区的数据copy到不同的reduceTask中进行归并排序后一次读取一组数据给reduce()函数。
简述Hdfs的默认副本策略?这样做有什么好处?
1)第一个副本在客户端所处的节点上。如果客户端在集群外(意思就是执行上传的服务器不属于集群的节点),则随机再机架上选一个; (2)第二个副本和第一个副本位于相同机架随机节点上; (3)第三个副本位于不同机架,随机节点。 优点:该策略减少了机架间的写流量,通常可以提高写性能。机架故障的机会远小于节点故障的机会。所以此策略不会影响数据的可靠性和可用性保证。
简单描述你对Hadoop集群SafeMode模式的理解?
集群处于安全模式,不能执行重要操作(写操作),集群属于只读状态。但是严格来说,只是保证HDFS元数据信息的访问,而不保证文件的访问。集群启动完成后,自动退出安全模式, 如果集群处于安全模式,想要完成写操作,需要离开安全模式。 (1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态) (2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态) (3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态) (4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)。 对于全新创建的HDFS集群,NameNode启动后不会进入安全模式,因为没有Block信息。
用一句话总结Combiner的作用和意义,使用它有什么前提?
Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
简述HDFS的文件上传流程?
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 2)NameNode返回是否可以上传。 3)客户端请求第一个 Block上传到哪几个DataNode服务器上。 4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。 5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。 6)dn1、dn2、dn3逐级应答客户端。 7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。 8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。
ReduceTask是负责从MapTask上远程读取输入数据后对数据排序,将数据分组传递给用户编写的reduce进行处理
MapReduce是一个分布式的运算程序编程框架,适合处理大量的离线数据,有良好的扩展性和高容错性
hdfs是分布式的海量文件存储系统
web页面访问http://192.168.153.88:50070可以查看hadoop的datanode存活和数据存储的URL地址
Namenode 全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport),接收到心跳信号意味着该Datanode节点工作正常
ResourceManager负责对 NodeManager 资源进行统一管理和调度
Hadoop1.x和Hadoop2.x区别之一,后则将mapreduce中的资源调度模块拆分为yarn
下列哪些是对reduceTask阶段任务正确理解:
对多个mapTask任务输出key,value,按照不同的分区通过网络copy到不同的reduceTask节点处理
对多个mapTask任务的输出进行合并、排序。再reduce函数中实现自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
outputformat把reducer输出的key,value保存到文件中
执行一个job, 如果这个job的输出路径已经存在,那么程序会:
抛出一个异常,然后退出程序的执行
会抛出文件路径已存在的异常
对mapreduce数据类型理解正确:
数据类型都实现Writable接口
hadoop的序列化中数据可以被序列化进行网络传输和文件存储
下面对Combiner描述正确的是:
合理利用Combiner可以提高程序执行效率
Combiner的作用可以减少对本地磁盘的访问次数。
Combiner过程设置则执行,否则不执行,默认过程中没有执行Combiner
Container封装节点上多维度资源包括:
内存 CPU 磁盘 网络
对ApplicationMaster描述正确的是:
负责协调来自ResourceManager分配的资源
通过NodeManager监视任务的执行和资源使用
对fsimage和edits描述正确的是:
FsImage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
SecondaryNode实时的辅助备份fsimage和edits,辅助NameNode,协助其完成元数据和编辑文件的合并工作
关于 SecondaryNameNode :
它是辅助NameNode ,它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间和压力,提高NameNode的整体性能
元数据中包含两个文件是:
fsimage和edits
1.mapreduce定义和优缺点?
MapReduce定义:MapReduce是一个分布式运算的编程框架,使用户开发“基于hadoop的数据分析应用”的核心框架。
优点:
1,MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的pc机上运行。也就是说写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2,良好的扩展性
当你的计算机资源不能得到满足的时候,你可以通过简单的增加机器扩展它的计算能力。
3,高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的pc机器上,这就是要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的机任务转移到另一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由hadoop内部完成的。
4,适合pb级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点:
1不擅长实时计算
MapReduce无法像mysql一样,在毫秒或者秒级内返回结果。
2,不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3,不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入磁盘,会造成大量的磁盘IO,导致性能非常的低下。
2.mapreduce的数据类型
|
Java类型 |
Hadoop Writable类型 |
|
Boolean |
BooleanWritable |
|
Byte |
ByteWritable |
|
Int |
IntWritable |
|
Float |
FloatWritable |
|
Long |
LongWritable |
|
Double |
DoubleWritable |
|
String |
Text |
|
Map |
MapWritable |
|
Array |
ArrayWritable |
hadoop序列化:
序列化:将对象序列化成字节序列 (方便磁盘存储和网络传输)
反序列化:将字节序列转换成对象
hadoop的序列化的优点:(只对数据进行序列化)
紧凑 快速 可扩展 可以跨语言交互
序列化
步骤1:
使用Writer接口
implements Writable
步骤2
/**
* 注意点:
* 1.序列化数据的时候,序列化的数据类型要对应
* write这个是hadoop提供的序列化方法
* @param dataOutput
* @throws IOException
*/
public void write(DataOutput dataOutput) throws IOException {
}
/**
* 注意点:
* 一定要注意反序列化变量赋值的顺序,要和序列化顺序保持一致
* readFields :hadoop 提供的反序列化方法
* @param dataInput
* @throws IOException
*/
public void readFields(DataInput dataInput) throws IOException {
}
job的提交流程:
waitForCompletion提交任务的入口方法
this.submit(); 提交job任务
this.ensureState(Job.JobState.DEFINE);再次确认我们job的状态(DEFINE)
this.connect();判断任务是在本地运行还是远程集群中运行(连接yarn)
submitter.submitJobInternal() 任务提交者提交任务
this.checkSpecs(job); 检查文件的输出路径是否存在
checkOutputSpecs()检查文件的输出路径是否存在,没有设置报异常,已经存在也报异常
addMRFrameworkToDistributedCache(conf); 将配置信息加载到分布式缓存中
this.submitClient.getNewJobID(); 获取一个任务的id
this.writeSplits(job, submitJobDir);获取切片数量,并将切片文件信息写入到submitJobFile文件夹下
this.writeConf(conf, submitJobFile);将配置信息写入到submitJobFile文件夹下
this.submitClient.submitJob 真正提交job任务
this.state = Job.JobState.RUNNING;任务提交完毕,将状态改为RUNNING
this.isSuccessful();任务执行成功还是失败:返回true表示任务执行成功,返回flase任务执行失败
FileInputFormat
getSplits:1.如何进行切片 2.可不可以切片this.isSplitable(job, path)
for(bytesRemaining = length; (double)bytesRemaining / (double)splitSize > 1.1D; bytesRemaining -= splitSize) {
blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining);
splits.add(this.makeSplit(path, length - bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
}
if (bytesRemaining != 0L) {
blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining);
splits.add(this.makeSplit(path, length - bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
}
如何自定义设置切片的大小参考课件3.1.3 默认情况下切片的切块大小是块大小128M
hadoop自带得inputformat
TextInputFormat 使用得是FileInput..得切片方法 LineRecordReader(将文件以kv值得形式返回)
NLineInputFormat 自定义了切片方法(按行切片) LineRecordReader
CombineTextInputFormat 自定义了切片方法(按照设置得大小切片) CombineFileRecordReader
FixedLengthInputFormat 使用得是FileInput..得切片方法 FixedLengthRecordReader(返回得都是固定长度得value)
KeyValueTextInputFormat 使用得是FileInput..得切片方法 KeyValueLineRecordReader(key是一行中得第一个单词,value是一行中除了第一个单词之后得字符串)
SequenceFileInputFormat 使用得是FileInput..得切片方法 SequenceFileRecordReader(二进制得数据)
注意一般情况下够用,但是特殊情况需要我们自定义
自定义inputformat首先得明确key value值得输出(作为mapper得输入得key value)
(1)自定义inputformat继承extends FileInputFormat<key,value>
@Override
protected boolean isSplitable(JobContext context, Path filename) {
//返回true或者false:表示是否允许切片
}
@Override
public RecordReader<org.apache.hadoop.io.Text, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
返回一个RecordReader(key value值)
}
(2)自定义RecordReader继承extends RecordReader<key,value>
实现6个方法,见代码
/**
* 框架运行的时候,执行一次
* @param inputSplit
* @param taskAttemptContext
* @throws IOException
* @throws InterruptedException
*/
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
fs = (FileSplit) inputSplit;
//获取文件的路径
Path path = fs.getPath();
//获取配置实例的对象
Configuration configuration = taskAttemptContext.getConfiguration();
//文件操作系统实例对象
fileSystem = path.getFileSystem(configuration);
}
/**
* 判断文件是否读完(是否还有下一组kv),
* @return 返回true表示存在下一组kv,返回false,表示不存在下一组kv
* @throws IOException
* @throws InterruptedException
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
}
/**
* 获取当前的key
* @return 返回当前的key
* @throws IOException
* @throws InterruptedException
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
}
/**
* 获取当前的value
* @return 返回当前的value
* @throws IOException
* @throws InterruptedException
*/
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
}
/**
* 获取读取文件的进度
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public float getProgress() throws IOException, InterruptedException {
}
/**
* 执行完毕,走close方法
* @throws IOException
*/
@Override
public void close() throws IOException {
}
(3)设置和使用自定义得inputformat(在driver类中)
//设置自定义的InputFormat
job.setInputFormatClass(xxxFileInputFormat.class);
inputformat主要得工作:
(1)文件得切片
(2)将输入文件转换为key value值,输出到mapper
mapreduce得流程图,自己去看一下(以后要达到会画得程度)。
分区:分数得数量对应着reducetask得数量,有几个分区就有几个输出文件
系统默认得分区,是随机分配得
可以自定义分区,将数据写入到指定分区中(文件中)
public class Mypartitioner extends Partitioner<Text,FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
//对不同得手机号进行处理,把不同得数据写入到指定得分区下
String phone = text.toString();
switch (phone.substring(0,3)){
case "138":
return 0;
case "139":
return 1;
case "135":
return 2;
case "150":
return 3;
default:
return 4;
}
}
}
设置reduceTask得数量
job.setNumReduceTasks(5);
设置自定义分区:
job.setPartitionerClass(xxxMypartitioner.class)
注意:
设置得reduceTask得数量(分区数)跟自定义分区分配分区时得值对应
注意分区号从0开始,不要跳号
MapReduce工作流程