2018-04-26
1.协同过滤
协同过滤(Collaborative Filtering)字面上的解释就是在别人的帮助下来过滤筛选,协同过滤一般是在海量的用户中发现一小部分和你品味比较相近的,在协同过滤中,这些用户称为邻居,然后根据他们喜欢的东西组织成一个排序的目录来推荐给你。问题的重点就是怎样去寻找和你比较相似的用户,怎么将那些邻居的喜好组织成一个排序的目录给你,要实现一个协同过滤的系统,需要以下几个步骤:
1.收集用户的爱好
2.找到相似的用户或者物品
3.计算推荐
在收集用户的喜欢方面,一般的方式有评分,投票,转发,保存书签,点击连接等等 ,有了用户的喜好之后,就可以通过这些共同的喜好来计算用户之间的相似度了。
2.相似度计算
相似度的计算一般是基于向量的,可以将一个用户对所有的物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对于某一个物品的偏好作为一个向量计算物品之间的相似度,相似度的计算有下列几种方式:
计算欧几里得距离:
利用欧几里得距离计算相似度时,将相似度定义如下:
皮尔逊相关系数:
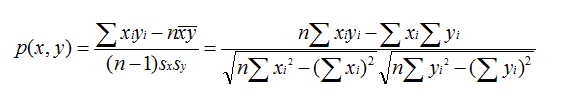
其中sx,sy表示x和y的标准差。
Cosine相似度:
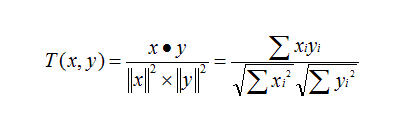
Tanimoto系数,也称作Jaccard系数:

基于用户的协同过滤:不考虑用户、物品的属性(特征)信息,它主要是根据用户对物品的偏好(Preference)信息,发掘不同用户之间口味(Taste)的相似性,使用这种用户相似性来进行个性化推荐。基于用户的协同过滤推荐,它是以用户为中心,观察与该用户兴趣相似的一个用户的群体,将这个兴趣相似的用户群体所感兴趣的其他物品,推荐给该用户。
基于物品的协同过滤:也不考虑用户、物品的属性(特征)信息,它也是根据用户对物品的偏好(Preference)信息,发掘不同物品之间的相似性。基于物品的协同过滤推荐,是以物品为中心,通过观察用户对物品的偏好行为,将相似的物品计算出来,可以认为这些相似的物品属于特定的一组类别,然后根据某个用户的历史兴趣计算其所属的类别,然后看该类别是否属于这些成组类别中的一个,最后将属于成组类别所对应的物品推荐给该用户。
基于模型的协同过滤:基于模型的协同过滤推荐,是采用机器学习的方法,通过离线计算实现推荐的,通常它会首先根据历史数据,将数据集分成训练集和测试集两个数据集,使用训练集进行训练生成推荐模型,然后将推荐模型应用到测试集上,评估模型的优劣,如果模型到达实际所需要的精度,最后可以使用训练得到的推荐模型进行推荐(预测)。可见,这种方法使用离线的历史数据,进行模型训练和评估,需要耗费较长的时间,依赖于实际的数据集规模、机器学习算法计算复杂度。
对于我们的用户历史行为数据,我们关注的是用户与物品之间的关系,可以生成一个用户-物品矩阵,矩阵元素表示用户对物品的偏好行为(或者是评分),如果用户和物品的数量都很大,那么可见这是一个超大稀疏矩阵,因为并不是每用户都对所有的物品感兴趣,只有每个用户感兴趣的物品才会有存在对应的偏好值,没有感兴趣的都为空缺值,最终我们是要从这些空缺值对应的物品中选择出一些用户可能会感兴趣的,推荐给用户,这样才能实现个性化推荐。
下面,我们假设使用用户-物品的评分矩阵来实现推荐,定义评分矩阵为R,那么通过将R分解为另外两个低秩矩阵U和M,由于R是稀疏矩阵,很多位置没有值,只能通过计算使用U与M的乘积近似矩阵R,那么只要最终得到的误差尽量小,能满足实际需要即可,一般使用均方根误差(Root mean square error,RMSE)来衡量,那么就要计算一个目标函数的最小值,如下函数公式所示:
√[∑di^2/n]=Re,式中:n为测量次数;di为一组测量值与真值的偏差。
具体代码如下:


# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. """ import os import codecs import numpy as np import pandas as pd from sklearn import cross_validation as cv from sklearn.metrics.pairwise import pairwise_distances #计算余弦相似性 os.getcwd() os.chdir("C:/Users/admin/Desktop/ml-100k/ml-100k") f=codecs.open('u.data', 'r') print (f.read()) header = ['user_id', 'item_id', 'rating', 'timestamp'] df = pd.read_csv('u.data', sep=' ', names=header) #计算唯一用户和电影的数量 n_users = df.user_id.unique().shape[0] n_items = df.item_id.unique().shape[0] print ('Number of users = ' + str(n_users) + ' | Number of movies = ' + str(n_items) ) #使用scikit-learn库将数据集分割成测试和训练,根据测试样本的比例(test_size),取0.25 train_data, test_data = cv.train_test_split(df, test_size=0.25) #基于内存的协同过滤 #创建用户-产品矩阵 #Create two user-item matrices, one for training and another for testing train_data_matrix = np.zeros((n_users, n_items)) for line in train_data.itertuples(): train_data_matrix[line[1]-1, line[2]-1] = line[3] test_data_matrix = np.zeros((n_users, n_items)) for line in test_data.itertuples(): test_data_matrix[line[1]-1, line[2]-1] = line[3] #计算余弦相似性,输出从0到1,因为打分都是正的 user_similarity = pairwise_distances(train_data_matrix, metric='cosine') item_similarity = pairwise_distances(train_data_matrix.T, metric='cosine') #预测 def predict(ratings, similarity, type='user'): if type == 'user': mean_user_rating = ratings.mean(axis=1) #You use np.newaxis so that mean_user_rating has same format as ratings ratings_diff = (ratings - mean_user_rating[:, np.newaxis]) pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T elif type == 'item': pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)]) return pred item_prediction = predict(train_data_matrix, item_similarity, type='item') user_prediction = predict(train_data_matrix, user_similarity, type='user') #评估 使用均方根误差(RMSE) from sklearn.metrics import mean_squared_error from math import sqrt def rmse(prediction, ground_truth): prediction = prediction[ground_truth.nonzero()].flatten() ground_truth = ground_truth[ground_truth.nonzero()].flatten() return sqrt(mean_squared_error(prediction, ground_truth)) print ('User-based CF RMSE: ' + str(rmse(user_prediction, test_data_matrix))) print ('Item-based CF RMSE: ' + str(rmse(item_prediction, test_data_matrix))) #基于模型的协同过滤 #计算稀疏度 sparsity=round(1.0-len(df)/float(n_users*n_items),3) print ('The sparsity level of MovieLens100K is ' + str(sparsity*100) + '%') import scipy.sparse as sp from scipy.sparse.linalg import svds #get SVD components from train matrix. Choose k. u, s, vt = svds(train_data_matrix, k = 20) s_diag_matrix=np.diag(s) X_pred = np.dot(np.dot(u, s_diag_matrix), vt) print ('User-based CF MSE: ' + str(rmse(X_pred, test_data_matrix)))
参考地址:http://python.jobbole.com/85516/