InnoDB 是聚集索引方式,因此数据和索引都存储在同一个文件里。首先 InnoDB 会根据主键 ID 作为 KEY 建立索引 B+树,如左下图所示,而 B+树的叶子节点存储的是主键 ID 对应的数据,比如在执行 select * from user_info where id=15 这个语句时,InnoDB 就会查询这颗主键 ID 索引 B+树,找到对应的 user_name='Bob'。
这是建表的时候 InnoDB 就会自动建立好主键 ID 索引树,这也是为什么 Mysql 在建表时要求必须指定主键的原因。当我们为表里某个字段加索引时 InnoDB 会怎么建立索引树呢?比如我们要给 user_name 这个字段加索引,那么 InnoDB 就会建立 user_name 索引 B+树,节点里存的是 user_name 这个 KEY,叶子节点存储的数据的是主键 KEY。注意,叶子存储的是主键 KEY!拿到主键 KEY 后,InnoDB 才会去主键索引树里根据刚在 user_name 索引树找到的主键 KEY 查找到对应的数据。
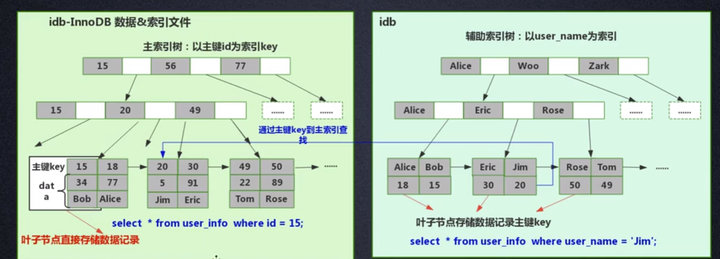
问题来了,为什么 InnoDB 只在主键索引树的叶子节点存储了具体数据,但是其他索引树却不存具体数据呢,而要多此一举先找到主键,再在主键索引树找到对应的数据呢?
其实很简单,因为 InnoDB 需要节省存储空间。一个表里可能有很多个索引,InnoDB 都会给每个加了索引的字段生成索引树,如果每个字段的索引树都存储了具体数据,那么这个表的索引数据文件就变得非常巨大(数据极度冗余了)。从节约磁盘空间的角度来说,真的没有必要每个字段索引树都存具体数据,通过这种看似“多此一举”的步骤,在牺牲较少查询的性能下节省了巨大的磁盘空间,这是非常有值得的。
转载至:https://zhuanlan.zhihu.com/p/113917726