郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 以下是对本文关键部分的摘抄翻译,详情请参见原文。
NeurIPS 2019 Workshop on Federated Learning for Data Privacy and Confidentiality, Vancouver, Canada.

Abstract
我们解决了非i.i.d.情况下的联邦学习问题,在这种情况下,局部模型漂移,抑制了学习。基于与终身学习的类比,我们将灾难性遗忘的解决方案改用在联邦学习上。我们在损失函数中加入一个惩罚项,强迫所有局部模型收敛到一个共享的最优值。我们表明,这可以有效地进行通信(不增加进一步的隐私风险),在分布式设置中随着节点数量的增加而扩展。实验结果表明,该方法在MNIST数据集上的识别效果优于同类方法。
1 Introduction
近年来,智能设备和传感器的出现,在边缘收集数据,并能够对这些数据采取行动保持数据私有化的愿望和其他考虑因素促使机器学习社区研究不需要从边缘设备发送数据的分布式训练算法。边缘设备通常具有较低的网络可用性和容量,这可能会限制通过标准SGD进行训练。McMahan等人的联邦平均算法(FedAvg)[1]让设备在将训练模型发送到中央服务器之前,对其本地数据进行多个epochs的训练(使用本地SGD)。然后,服务器聚合模型,并将聚合模型发送回设备以完成迭代,直到收敛。
联邦学习提出了三个不同于传统分布式学习的挑战。第一个是计算站的数量,可能有数亿个。第二个是比数据中心的集群间通信慢得多的通信。第三个区别,也是我们在这项工作的重点,是高度非i.i.d.方式,其中数据可以分布在设备之间。
在一些实际情况下,联邦学习对非i.i.d.分布具有鲁棒性[2]。最近也有一些理论结果证明了联邦学习算法在非i.i.d.数据上的收敛性。然而,很明显,即使在非常简单的场景中,在非i.i.d.分布上的联邦学习也难以获得良好的结果(与i.i.d.情况相比,在准确性和通信轮数方面)[1,4]。
1.1 Overcoming Forgetting in Sequential Lifelong Learning and in Federated Learning
联邦学习问题和另一个被称为终身学习的基本机器学习问题(以及相关的多任务学习)之间有着很深的相似性。在终身学习中,挑战是学习任务A,并使用相同的模型继续学习任务B,但不要“遗忘”,不要严重影响任务A的性能;或者一般来说,学习任务A1, A2, …依次进行,不要忘记以前学过的任务,这些任务不再提供样本。除了串行而不是并行的学习任务外,在终身学习中,每个任务只出现一次,而在联邦学习中则没有这样的限制。但撇开这些差异不谈,这些范式有一个共同的主要挑战——如何在不干扰在同一模型上学习的不同任务的情况下学习一项任务。
因此,类似的方法被应用于解决联邦学习和终身学习问题也就不足为奇了。一个这样的例子是数据蒸馏,其中代表性的数据样本在任务之间共享[5,6]。然而,联邦学习经常被用于实现数据隐私,这将被从一个设备发送到另一个设备或从一个设备发送到一个中心点的数据打破。因此,我们寻求在任务之间共享其他类型的信息。

可以在Kirkpatrick等人[7]中找到使用哪种信息的答案。本文提出了一种新的终身学习算法——弹性权值合并(Elastic Weight Consolidation, EWC)。EWC旨在防止从学习任务A转移到学习任务B时发生灾难性遗忘。其思想是确定网络参数θ中对任务A信息量最大的坐标,然后在学习任务B时,惩罚学习者更改这些参数。 它的基本假设是深度神经网络过参数化程度足够高,因此很有可能找到一个任务B的最优解在先前学习到的任务A的最优解的邻域。
为了控制学习任务B时各坐标中θ的刚度,作者建议使用Fisher信息矩阵的对角项,对距离任务A的最优解太远的部分参数向量θ进行选择性惩罚。这是使用以下目标(公式1)完成的。
它们提供(1)的形式化证明是贝叶斯的:让DA和DB成为用于任务A和B的独立数据集。我们就可以得到概率公式(见截图)。log p(DB | θ)是LB(θ)优化的标准似然最大化,后验p(θ | DA)用拉普拉斯方法近似为高斯分布,期望为任务A的最优解,协方差为任务A最优解的Fisher信息矩阵对角项。
众所周知,在某些正则条件下,在θ取θ*时,信息矩阵近似于L(θ)的Hessian矩阵HL。由此我们得到(1)的非贝叶斯解释,即公式2。其中L(θ) = LB(θ) + LA(θ)正是我们希望最小化的损失。一般来说,你可以学习一系列的任务A1, …, AT。在第3节中,我们依赖于上述解释作为二阶近似,以便构建联邦学习的算法。我们将进一步展示如何以保留标准FedAvg算法的隐私优势的方式实现这种算法。
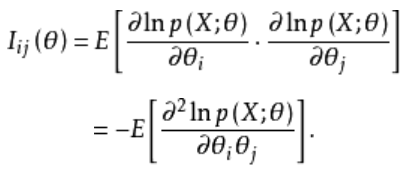
费雪信息(Fisher Information)参见https://blog.csdn.net/artifact1/article/details/80731417.
费雪信息矩阵(Fisher Information Matrix)参见https://baike.baidu.com/item/%E8%B4%B9%E6%AD%87%E8%80%B3%E4%BF%A1%E6%81%AF%E7%9F%A9%E9%98%B5/22676174?fr=aladdin.
2 Related Work
只有少数工作直接试图应对非i.i.d.分布的联邦学习的挑战。一种方法是放弃周期平均,通过对每个局部小批量之后发送到中心点的更新进行稀疏化和量化来减少通信量[9]。Zhao等人[6]研究表明,在不同的节点之间只共享一小部分数据,可以大大提高模型的精度。然而,在许多联邦学习场景中,共享数据是不可接受的。

与我们的方法有些相似,MOCHA[10]用不同的参数wi∈Rdxn连接每个任务,并且通过添加损失项tr(WΩWT)来对任务之间关系的建模,其中W=[w1, …, wn]和Ω∈Rnxn。对W和Ω进行了优化。MOCHA使用原始对偶公式来解决优化问题,因此,与我们的算法不同,它不适合于深度网络。
也许最接近我们工作的是Sahu等人[11],作者提出了他们的FedProx算法,它和我们的算法一样,也使用参数刚度。然而,与我们的算法不同,在FedProx中,惩罚项是各向同性的,μ||θ - θt|| / 2。DANE[12]通过添加梯度校正项增强FedProx,以加速收敛,但对非i.i.d.数据不鲁棒[11,13]。AIDE[13]提高了DANE处理非i.i.d数据的能力。然而,它是通过使用DANE的不精确版本,并通过限制本地计算量来实现的。
最近的一项工作[3]证明了非i.i.d.情形下FedAvg的收敛性。它还从理论上解释了一个在实践中已知的现象,即当局部迭代次数太多时性能下降。这正是我们在这项工作中要解决的问题。
3 Federated Curvature

在本节中,我们将介绍EWC算法对联邦学习场景的适应性我们称之为FedCurv(用于联邦曲率,启发自(2))。将N个节点标记为S={1, …, N},则各个任务的本地数据集为{A1, …, AN}。我们不同于FedAvg算法,在每一轮t中,我们使用S中的所有节点,而不是随机选择它们的子集。(我们的算法可以很容易地扩展到选择一个子集。)在第t轮,每个节点s∈S优化以下损失:公式(3)。
在每轮t上,从初始点开始,节点通过为E个局部epochs运行SGD来优化其局部损失。在每轮t结束时,每个节点j向其余节点发送SGD结果和Fisher信息矩阵的对角项。这些将用于t+1轮的损失。我们切换θ值,以表示本地任务是为E epochs优化的,而不是在它们收敛之前(就像EWC的情况一样)。然而,(2)(它推广到N个任务)支持使用大E值。
3.1 Keeping Low Bandwidth and Preserving Privacy

隐私:需要注意的是,我们只需要将本地梯度相关的聚合信息(按本地数据样本聚合)从设备发送到中心点。在隐私方面,它与经典的FedAvg算法没有显著区别。与FedAvg一样,中心点本身只需要保留来自设备的全局聚合信息。我们看不出为什么成功应用于FedAvg的安全聚合方法[14]不能应用于FedCurv的原因。

4 Experiments
我们在一组96个模拟设备上进行了实验。我们将MNIST数据集[16]分成962个同质标签块(丢弃少量数据)。我们随机给每个设备分配了两个块。我们使用了来自MNIST PyTorch样例的CNN架构[17]。
我们探索了两个因素:(1) 学习方法 - 我们考虑了三个算法:FedAvg、FedProx和FedCurv(我们的算法);(2) E:每轮的epochs数,这是本研究的特别关注点,因为我们的算法是为大的E值设计的;C:参与每次迭代的设备的比例;B:本地批处理大小;这些参数被固定在C=1.0, B=256。对于所有的实验,我们还使用了一个恒定的学习速率η=0.01。
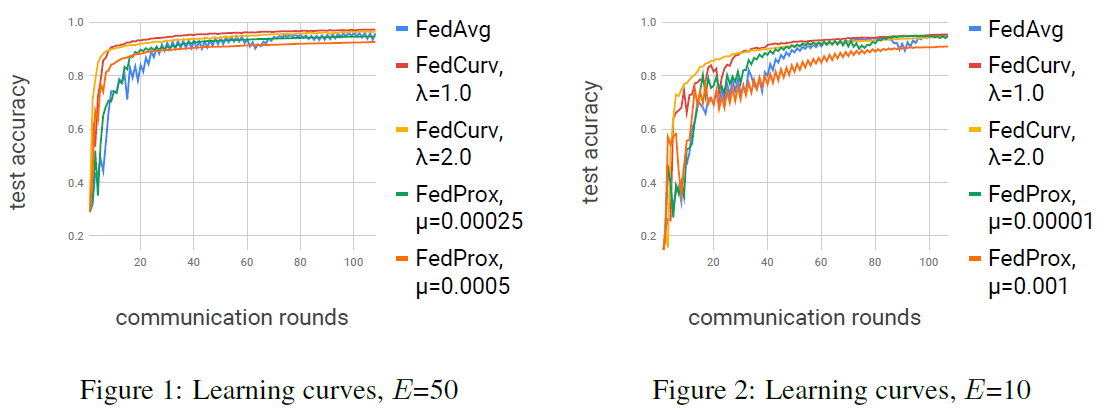
FedProx的µ和FedCurv的λ值是按以下方式选择的:我们寻找在最小轮数下达到90%测试精度的值。我们通过在使用因子10的乘法网格上搜索,然后使用因子2,以确保最小值。表1显示了使用这些选择的参数达到95%、90%和85%测试精度所需的轮数。我们发现,对于E=50,FedCurv达到90%的测试精度的速度,是原版FedAvg算法的三倍。FedProx也比FedAvg快90%。然而,虽然我们的算法达到95%的测试精度的速度是FedAvg的两倍,但FedProx的速度却比FedAvg慢了两倍。当E=10时,FedCurv和FedProx的改善不太显著,FedCurv仍优于FedProx和FedAvg。
在图1和图2中,我们可以看到FedProx和FedCurv在训练过程的开始阶段都表现良好。然而,虽然FedCurv提供了足够的灵活性,允许在过程结束时达到高精度,但参数的刚度是以精度为代价的。FedCurv为更高的E值提供了更显著的改进(FedProx也是如此),正如理论所预期的那样。

5 Conclusion
这项工作为非i.i.d.数据的联邦学习问题提供了一种新的解决方法。它建立在终身学习的基础上,利用Fisher信息矩阵的对角项来保护对每个任务都很重要的参数。迁移需要修改顺序解决方案(从终身学习)为并行形式(联邦学习),这在先验上涉及数据的过度共享。我们证明了这是可以有效地做到的,而不会大幅增加带宽使用和损害隐私。正如我们的实验所证明的,我们的FedCurv算法保护了每个任务的重要参数,提高了收敛性。