郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

![]()
Nature May 17, 2018
Received: 5 July 2017; Accepted: 3 April 2018;
Published online 9 May 2018.
Abstract
深度神经网络在从目标识别到复杂的游戏(例如Go1,2)等领域都取得了令人瞩目的成功。然而,对于人工智能体而言,导航仍然是一个巨大的挑战,通过强化学习训练的深度神经网络3-5无法与哺乳动物空间行为的能力相提并论,而后者是由内嗅皮层中的网格细胞支持的6。网格细胞被认为提供了多尺度的周期性表征,用作编码空间的度量函数7,8,对于整合自身运动(路径整合)6,7,9和规划目标的直接轨迹(基于矢量的导航)7,10,11至关重要 。在这里,我们着手利用网格细胞的计算功能来开发具有类似于哺乳动物的导航能力的深度强化学习智能体。我们首先训练了一个循环网络来执行路径整合,从而导致出现了类似于网格细胞以及其他内嗅细胞类型的表征12。然后,我们证明了这种表征为智能体在困难,陌生且多变的环境中定位目标提供了有效的基础——通过深度强化学习优化了导航的主要目标。具有网格状表征的智能体的性能超过了专家级人员和比较智能体的性能,而基于矢量的导航所需的度量值则源自网络内的网格状细胞。此外,类似网格的表征使智能体能够进行捷径行为,使人联想到哺乳动物的行为。我们的发现表明,类似网格的新兴表征为智能体提供了欧式空间度量和相关的矢量运算,为熟练的导航提供了基础。因此,我们的研究结果支持了神经科学理论,这些理论将网格细胞视为基于矢量的导航的关键7,10,11,表明网格可以与基于路径的策略结合使用,以在具有挑战性的环境中支持导航。

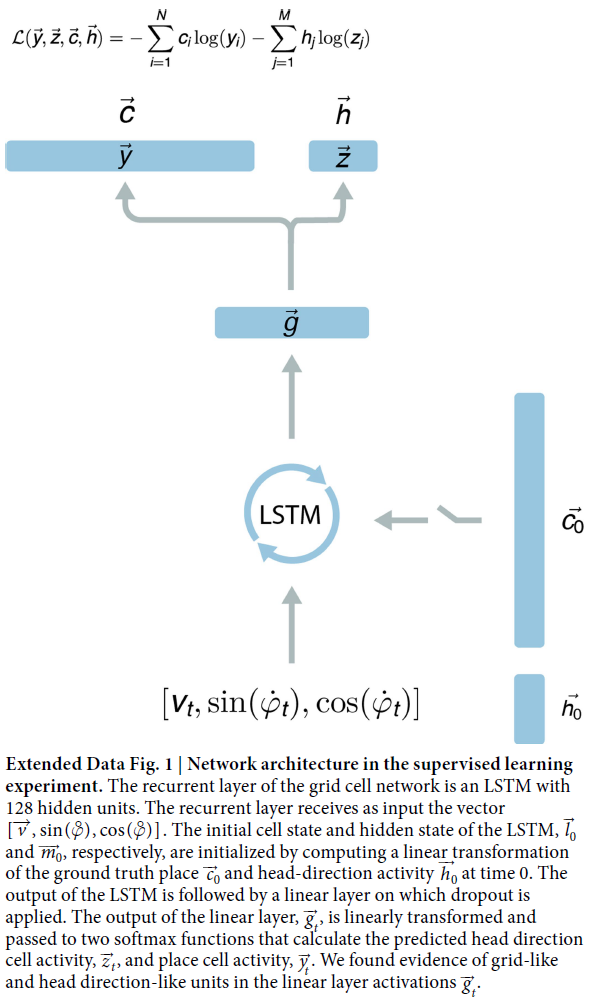
图1 | 类似内嗅表征出现在经过训练以进行路径整合的网络中。a,网络结构示意图(参见扩展数据中的图1)。b,示例轨迹(15s);从位置细胞解码的自身定位(深蓝色)类似于实际路径(浅蓝色)。c,训练之前(蓝色)和训练后(绿色)的解码位置的精度。d,线性层单元表现出类似于网格,边界和头部方向细胞的空间调谐响应。顶部,ratemap显示了地理位置上的活动;中间,标明网格度的ratemap的空间自相关图;底部,极坐标图显示了活动与头部方向的关系。e,将网格状单元的空间比例(n = 129)聚类。分布比偶然性更离散(影响大小为2.98;95%CI为0.97-4.91),并且最好是由三个高斯混合而成(中心为0.47、0.70和1.06m,比率为1.49和1.51)。f,定向性最强的单元(n = 52)的定向调整。线表示合成向量的长度和方向(请参见“方法”),表现出六折的聚类,使人联想到联合网格细胞。g,网格度分布和方向调整。虚线表示距零分布的95%置信区间(基于500个数据排列);14个(11%)网格显示方向调节(请参见方法)。在圆形环境中也看到了类似的结果(扩展数据中的图3)。
在环境中进行自身定位并根据自身运动更新位置的能力是导航的核心组成部分13。我们使用了以觅食啮齿类动物为模型的模拟轨迹,训练了一个深度神经网络,以在正方形区域(2.2m×2.2m)内进行路径整合(请参见方法)。该网络需要使用平移和角速度信号更新其位置和头部方向的估计,以反映哺乳动物大脑可用的那些信号12,14,15(参见方法;图1a,b)。速度被提供给具有长短期记忆(LSTM)架构的循环网络的输入,该架构使用时间反向传播进行训练(请参见方法和补充讨论),从而使网络可以动态地将当前输入信号与反映过去事件的活动模式组合在一起(请参见方法;图1a)。LSTM计划通过线性层位置和头部方向单元——具有定义为其输入的简单线性函数的活动的单元(有关结构,请参见扩展数据中的图1)。重要的是,线性层要经过正则化处理,尤其是随机失活16,以便在每个时间步骤随机将50%的单元沉默。在每个时间步骤,提供了与当前位置相对应的位置和头部方向单元的活动矢量作为监督训练信号(请参见方法;扩展数据中的图1)。这种监督形式遵循的证据表明,在哺乳动物中,位置和头部方向表征在解剖学上与内嗅网格细胞紧密相连12,并在成熟网格细胞出现之前出现在啮齿动物幼崽中17,18。同样,在成年啮齿动物中,内嗅网格细胞已知会投射到海马体上,并似乎对位置细胞的神经活动有贡献19。
如期望的那样,网络能够在这种涉及觅食行为的环境中进行准确的路径整合(15s轨迹后的平均误差为16cm,而未经训练的网络为91cm,效果大小为2.83,95%置信区间(CI)为2.80-2.86;图1b,c)。令人惊讶的是,网络线性层内的单个单元发展出了稳定的空间活动曲线,类似于内嗅网络6,12内的神经元(图1d,扩展数据中的图2)。具体来说,在512个线性层单元中有129个(25.2%)类似于网格细胞,相对于由保守场改组程序生成的零分布,显示出显著的六边形周期性(网格度20)(请参见方法)。根据活动图的空间自相关图测量的网格模式的规模20在单元之间变化(范围为28cm至115cm,平均为66cm),并遵循多模式分布,这与啮齿动物网格细胞的经验结果一致21,22(图1e)。为了评估这些聚类,我们拟合了高斯混合,通过最小化贝叶斯信息准则(BIC)来找到最简约的数字。该分布最适合三个高斯的混合(均值分别为47cm,70cm和106cm),表明存在规模聚类,相邻聚类之间的比率约为1.5,与理论预测值非常接近23,并且也位于啮齿类动物报道的范围内21,22(图1e,扩展数据中的图3)。线性层还表现出类似于头部方向细胞(10.2%),边界细胞(8.7%)和少量位置细胞12的单元,以及这些表征的结合20,24(图1d,f,g,扩展数据中的图2)。
为了确定这些表征的鲁棒性,我们对网络进行了100次重训练,在每种情况下都发现了类似比例的网格状单元(平均为23%,s.d. 2.8%,具有显著网格度得分的单元)和其他空间调节单元(扩展数据中的图3)。相反,没有正则化的网络就不会出现类似网格的表征(例如,Dropout,请参见方法;另请参见参考资料25,扩展数据中的图4)。因此,使用正则化,包括Dropout(已经被认为是神经系统中的噪声的平行线),对于类似内嗅表征的出现至关重要。因此值得注意的是,我们的结果表明,类似于哺乳动物内嗅皮质中发现的网格状表征出现在经过训练以进行路径整合的通用网络中,这与以前使用预先配置的网格细胞的方法形成了鲜明的对比(见补充讨论)。此外,我们的结果与以下观点相一致:网格细胞代表了由自身运动信号6-9更新的位置代码的有效而强大的基础。

图2 | one-shot野外导航到隐含目标。a,基于矢量的导航示意图。b,典型环境的俯视图(图标表示智能体和朝向)。c,b的智能体视图。d,深度强化学习架构示意图(扩展数据中的图5)。PCP,位置细胞预测;HDP,头部方向细胞预测。e,从位置细胞单元解码的自身定位的精度。f,网格细胞智能体和位置细胞智能体的性能(y轴表示在一次episode中获得的奖励,每次到达目标计10分,灰色带表示基于5000个bootstrapped样本的68%置信区间)。g,如图1所示,线性层形成类似于内嗅皮层的空间表征。从左到右,两个网格细胞,一个边界细胞和一个头部方向细胞。h,在episode的第一次尝试中,智能体探索找到目标,然后直接导航到目标。'S'表示起始位置。i,成功导航后,为策略LSTM提供了“伪”目标网格代码,将智能体引导到没有目标的位置。j,k,根据网格细胞和位置细胞智能体的策略LSTM解码目标导向的度量代码(即,欧氏距离和方向)。相关系数的bootstrapped分布(1000个样本)每个都用覆盖在Tukey箱形图上的小提琴图显示。
接下来,我们试图检验以下假设:当通过深度强化学习进行训练时,新兴表征可为新型具有挑战性且多变的环境中的目标导航提供有效的基础功能。已经提出了内嗅网格细胞以提供欧式空间度量,从而支持目标导向矢量的计算,使动物能够遵循直接路线到达被记住的目标,这一过程称为基于矢量的导航7,10,11。从理论上讲,将空间位置分解为网格细胞提供的多尺度周期代码的优势在于,可以通过检查每个尺度级别的代码差异来检索两点的相对位置7,11(图2a)——结合模余数以返回真实向量。然而,尽管这种框架具有明显的实用性,但仍然缺乏网格表征直接参与目标导向导航的实验证据。
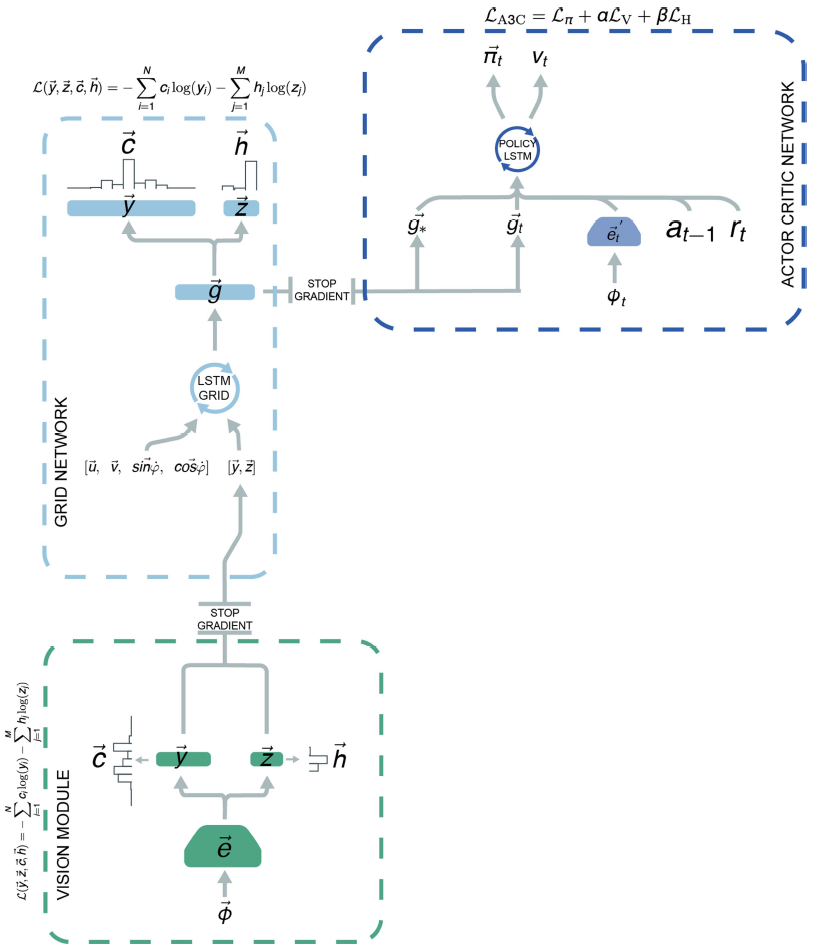
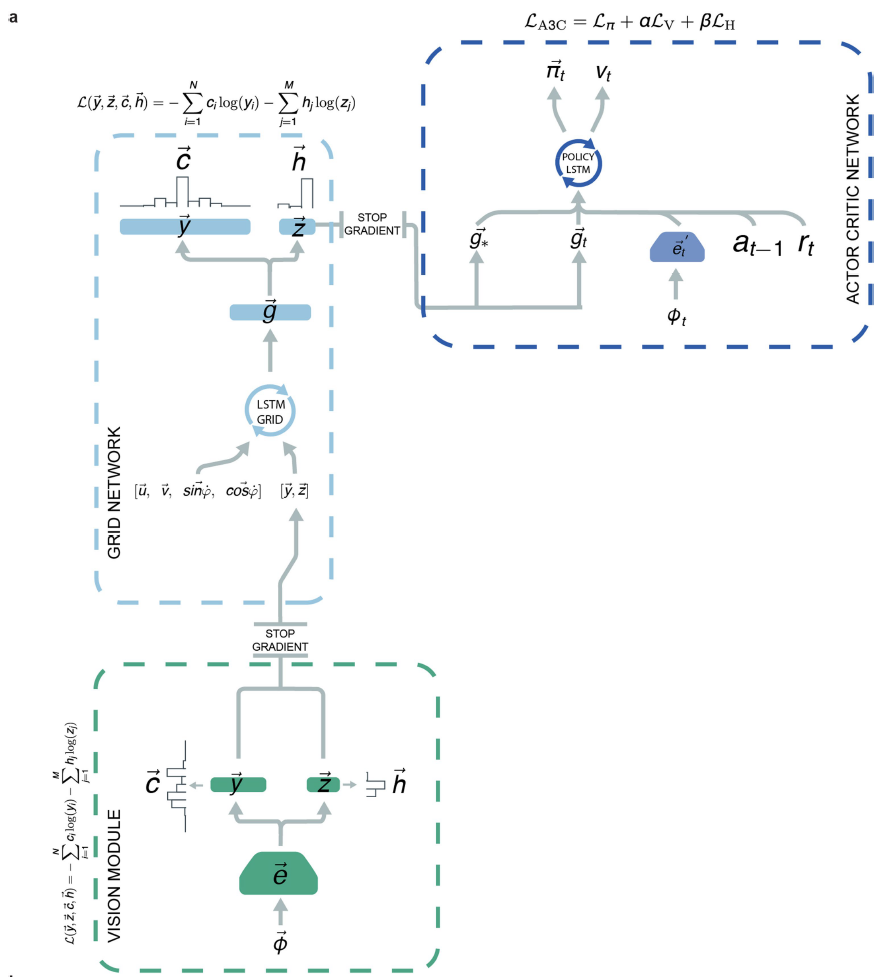
为了开发具有潜力的基于矢量的导航的智能体,我们将上述的“网格网络”整合到了使用深度强化学习进行训练的更大的架构中(图2d,扩展数据中的图5)。像以前一样,网格网络是使用监督学习进行训练的,但是,为了更好地估计可用于导航哺乳动物的信息,它现在收到了受到随机噪声和视觉输入干扰的速度信号。实验证据表明,向网格细胞输入的位置细胞可校正漂移并将网格固定到环境信号21。与此并行的是,视觉输入由“视觉模块”处理,该视觉模块由卷积网络组成,该卷积网络产生位置和头部方向的细胞活动模式,这些活动模式在5%的时间内作为输入提供给网格网络,这类似于偶尔移动的动物,对显著的环境信号的不完美观察27(参见方法;图2b,c和扩展数据中的图5)。网格网络线性层的输出(对应智能体的当前位置)作为“策略LSTM”的输入提供,“策略LSTM”是第二个循环网络,既控制智能体的动作,又输出价值功能。此外,每当智能体达到目标时,“目标网格代码”(线性层中的活动)便会在导航期间作为额外输入提供给策略LSTM。
我们首先在经典Morris水迷宫的启发下,在一个简单的环境中检查了智能体的导航能力(图2b,c;2.5m×2.5m方形场地;请参见方法和补充结果)。值得注意的是,在这种更具挑战性的环境中,智能体仍然能够准确地自身定位,在这种情况下,没有提供有关位置的真实信息,而且速度输入是带噪的(15s轨迹后的平均误差为12cm,而未经训练的网络为88cm;效果大小为2.82;95%CI为2.79-2.84;图2e)。此外,智能体表现出熟练的目标发现能力,通常会从任意起始位置直接进入目标(图2h)。之所以选择性能,是因为其优于自身控制的位置细胞智能体(图2f,请参见“补充结果和方法”),这是因为位置细胞提供了自身定位的鲁棒性表征,但并未为远程矢量计算提供基础11。我们检查了线性层中的单元,再次发现了与内嗅皮层中相似的异质群体,包括网格状单元(21.4%)以及其他空间表征(图2g,扩展数据中的图6)——与哺乳动物网格细胞对自身运动信息15,28和空间信号6,21的依赖。
接下来,我们转向我们的中心论断,即网格细胞使智能体具有执行基于矢量的导航的能力,从而使下游区域能够通过将当前活动与记住的目标活动进行比较来计算目标定向矢量7,10,11。在智能体中,我们希望这些计算将由策略LSTM执行,该策略将接收线性层上的当前活动模式(称为“当前网格代码”;图2d和扩展数据中的图5)以及代表智能体最后一次达到目标的时间的活动模式(称为“目标网格代码”),并使用它们来控制移动。因此,我们执行了几种操作,得出了四行证据,以支持基于矢量的导航假设(请参阅补充结果)。
首先,为了证明目标网格代码提供了足够的信息以使智能体能够导航到任意位置,我们将其替换为从环境中某个位置随机采样的“伪”目标网格代码(请参见方法)。智能体沿着一条直接路径到达新指定的位置,绕过不存在的目标(图2i),这与Morris水迷宫探测试验中的啮齿动物相似(已移除逃逸平台)。其次,我们证明了从网格细胞智能体的策略LSTM中保留目标网格代码对性能具有惊人的有害影响(扩展数据中的图6c)。第三,我们证明了网格细胞智能体的策略LSTM包含基于矢量的导航的关键组成部分的表征(图2j,k),以及欧氏距离(在r = 0.17上的差异;95%CI,0.11-0.24)和同心目标方向(在r = 0.22上的差异;95%CI,0.18-0.26)比位置细胞智能体代表更强。值得注意的是,最近在哺乳动物海马体中已经报道了目标距离的神经表征29。最后,我们提供了与基于矢量的导航假设的预测相符的证据,即,目标网格代码中最接近网格状单元的目标病变(即沉默)应该对性能和基于矢量的度量的表征(例如,欧氏距离)而不是假病变(即,非网格单元的沉默;请参见补充结果)。

图3 | 在具有挑战性的环境中导航。a,b,多房间环境的俯视图,目标驱动(a)和目标门(即具有随机门;b)。显示目标(星号)和智能体(头部图标)位置。c,d,a和b的智能体视图分别显示红色目标和关闭的黑色门。e,f,分别为a和b的智能体训练性能曲线,以及人类专家的性能(虚线)。性能是指超过100个episode的平均累积奖励。灰色带显示基于5000个bootstrapped样本的68%CI。g,超过100个episode的测试性能分布,显示了智能体推广到更大版本目标门环境的能力,并在每个智能体的Tukey箱形图上覆盖了小提琴图。h,网格细胞智能体的价值函数作为热图投影到示例较大的门窗环境中(红色表示较高价值的函数)。虚线表示原始训练环境的范围。尽管尺寸较大,但价值函数显然会近似欧氏距离目标的距离。i,示意图显示基于矢量的目标导航所需的关键度量。j,k,在导航期间从智能体的策略LSTM解码基于向量的度量代码。在每种情况下,都将相关系数的bootstrapped分布(1000个样本)与小提琴图叠加在Tukey箱形图上显示。
在证明了网格状表征在简单的方形运动场中优化one-shot目标学习的有效性之后,我们评估了智能体在两种具有挑战性的程序生成的多房间环境中的性能,称为“目标驱动”和“目标门”(请参见方法)。值得注意的是,这些环境对于具有外部记忆的深度强化学习智能体来说具有挑战性(扩展数据中的图7e,f,h,i和补充结果)。同样,网格细胞智能体表现出高水平的性能,在一系列网络超参数方面具有惊人的鲁棒性(扩展数据中的图7a–c),并且比控制智能体或人工专家更频繁地达到目标——这是深度强化学习智能体在游戏场景中的典型基准性能2(图3e,f;参见补充结果)。此外,当在比以前看到的环境大得多的环境中测试智能体而不进行重训练时,只有网格细胞智能体能够有效地泛化(图3g,h;参见补充结果)。尽管“目标驱动”环境非常复杂,我们仍然可以在导航的初始阶段以高精度从网格智能体策略LSTM解码关键度量代码,并且网格细胞智能体中的解码精度明显高于位置细胞和深度强化学习控制智能体(图3j,k和补充结果;有关控制智能体结构,请参见扩展数据中的图8,9)。

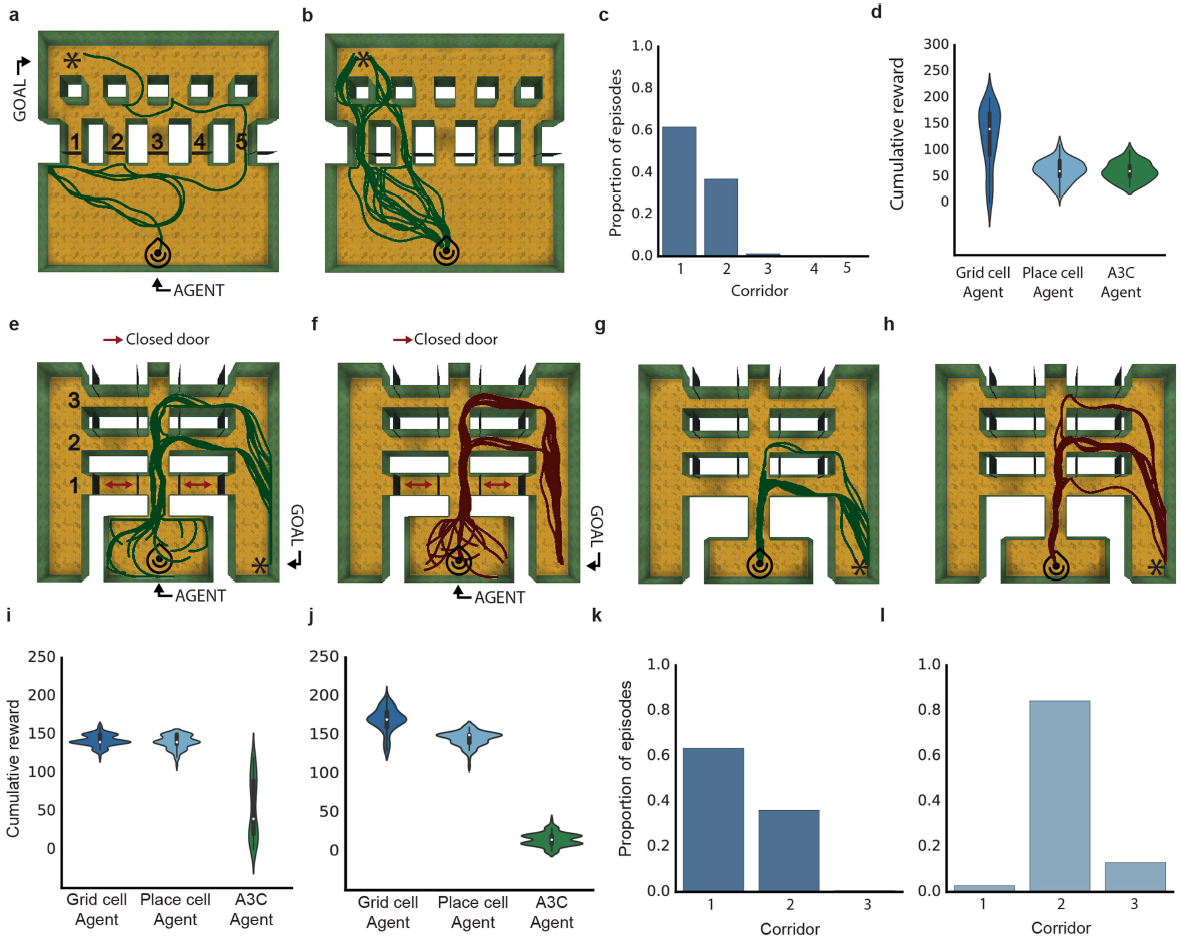
图4 | 灵活使用捷径。a,线性朝阳迷宫中的网格细胞智能体的示例轨迹(仅门5打开;图标表示开始位置)。b,在所有门打开的情况下进行测试配置;网格细胞智能体使用新近可用的捷径(显示了100个episode)。c,直方图显示智能体对大多数直接路线的强烈偏好。d,在双重E迷宫(走廊1门关闭)中训练期间的示例网格细胞智能体轨迹(100)。e,在走廊1打开且有100个网格智能体轨迹的测试配置。f,类似于c的直方图,显示智能体更喜欢新近可用的最短路径。有关位置细胞智能体的性能,请参见扩展数据中的图10。
最后,哺乳动物空间行为的核心特征是能够利用新颖的捷径并穿越空间的未访问部分,这种能力被认为依赖于基于矢量的导航9,11。令人惊讶的是,网格细胞智能体(但不是比较智能体)在经过专门设计的神经科学启发的迷宫中鲁棒地展示了这些能力,并在它们出现后立即采取了直接通往目标的路线(图4,扩展数据中的图10和补充结果)。
传统的同时定位和映射(simultaneous localization and mapping, SLAM)技术通常需要构建准确且完整的地图,并从外部定义目标的性质和位置。相比之下,本文中介绍的深度强化学习方法具有从稀疏奖励中端到端学习复杂控制策略的能力,能够以自动的方式采取涉及捷径的直接途径,其能力超出了以往的深度强化学习方法3–5,并且在任何SLAM系统中都必须手工编码。
我们的工作表明,网格状表征为在具有挑战性的新颖环境中灵活导航提供了有效的基础,支持了以前缺乏强大的经验支持的基于矢量的导航中网格细胞的理论模型7,10,11。我们还表明,基于矢量的导航可以与基于路径的障碍回避策略有效结合,从而能够在具有挑战性的多隔室环境中利用最优路线。总而言之,我们认为网格状表征为智能体提供了欧氏几何框架,这与它们在哺乳动物中提出的计算作用相似,是一种早期的Kantian式空间支架,用于组织感知经验17,18。
Methods
Path integration: supervised learning experiments.
Simplified 2D environment. 在正方形和圆形环境中,壁长为L(圆形情况下的直径),生成了持续时间为T的模拟大鼠轨迹。模拟的老鼠从外壳内的均匀采样位置和朝向角度开始。使用类似老鼠的运动模型31,通过避开墙壁来获得均匀覆盖整个环境的轨迹(有关模型的参数,请参见补充方法中的表1)。




Navigation through deep reinforcement learning.
Environments and task. 我们从DeepMind Laboratory39平台的第一人称视角评估了智能体在三种环境下的智能体性能。
Custom environment: square arena. 这包括一个10×10的方形运动场,对应于假设智能体速度为15cm/s的2.5×2.5m运动场(图2b,c)。运动场包含一个单一且彩色的运动场内信号,其位置和颜色在每一个episode中都会发生变化,地板的质地,墙壁的质地和运动场的位置也会改变。如下所述,在目标驱动和目标门环境中,有一组远端信号(即建筑物)与人类实验中使用的虚拟现实环境的设计相平行40。这些远端信号是在无限远处渲染的,以便提供方向信息,但不提供距离信息,并且它们的配置在各个episode中都是一致的。在每个episode开始时,智能体(如下所述)始于一个随机的位置,并且被要求探索以找到一个未标记的目标,这与经典Morris水迷宫中啮齿动物的任务平行。该智能体始终始于环境的中央6×6网格(即1.5×1.5m)。在整个训练和测试中都会应用速度输入![]() 中的噪声(即高斯噪声ε,其中μ= 0,σ= 0.01)。动作空间是离散的(六个动作),但是提供了细粒度的电机控制(即智能体可以小幅旋转,向前,向后或侧向加速,或者在移动时实现旋转加速度)。
中的噪声(即高斯噪声ε,其中μ= 0,σ= 0.01)。动作空间是离散的(六个动作),但是提供了细粒度的电机控制(即智能体可以小幅旋转,向前,向后或侧向加速,或者在移动时实现旋转加速度)。
DeepMind laboratory environments:目标驱动和目标门。目标驱动和目标门是具有挑战性的,视觉上丰富的多房间环境(图3a–d)。迷宫形成在11×11的网格内,对应于2.7×2.7m(有关较大的11×17迷宫的定义,请参见下文)。在每个episode的开始都以程序方式产生迷宫。因此,每个episode的布局,墙壁纹理,地标(墙壁上的迷宫内信号)和目标位置均不同,但在episode内保持一致。以无穷远渲染的建筑物形式出现的远端信号,如上文针对方形运动场所述。
目标驱动任务和目标门任务之间的关键区别在于,后者具有迷宫中随机门的额外挑战。具体来说,每次智能体到达目标时,门的状态(打开或关闭)在一个episode中随机改变。这意味着在episode发生期间,从给定位置到目标的最优路径发生了变化,这需要智能体重新计算轨迹。
在这两个任务中,智能体均从迷宫中的随机位置开始,其任务是探索以找到目标。两个级别的目标始终由同一对象表示(图3c)。到达目标后,智能体获得10分的奖励,之后将其传送到迷宫中的新随机位置。在这两个级别中,episode持续了5400个环境步骤(90s)的固定持续时间。
Generalization on larger environments. 我们测试了在标准环境(11×11)下训练的智能体推广到较大环境(11×17,对应于2.7×4.25m)的能力。这些环境的过程生成和组成与标准环境相同。每位智能体在11×11目标门迷宫中接受了总共109个环境步骤的训练,并选择性能最优的副本(在11×11中的最高渐近性能平均超过100个episode)来评估较大的迷宫。注意,在较大的迷宫中评估过程中冻结了智能体的权重。评估是100次固定持续时间为12600个环境步骤(210s)的episode。
Probe mazes to assess shortcut behaviour. 为了测试智能体遵循新颖的目标导向的路线的能力,我们创建了一系列受迷宫启发的环境,旨在测试啮齿动物的捷径能力。
第一个迷宫是Tolman朝阳迷宫的线性版本(图4a),用于确定智能体在路径可用时是否能够准确地朝目标前进(请参阅补充方法)。在这个迷宫中,到达目标后,智能体以相同的航向传送到原始位置。在目标门迷宫中对智能体进行了训练,并在测试过程中冻结了网络的权重——所有智能体均进行了100个episode,每一个持续5400个环境步骤(90s)的固定持续时间。
第二种环境是双重E迷宫(图4d,扩展数据中的图10),旨在测试智能体穿越整个空间的能力(请参阅补充方法)。在这个迷宫中,我们既有训练条件,又有测试条件。训练和测试均在迷宫中进行,但在测试时将权重冻结。智能体始终在中央房间启动(例如,请参见图4d)。迷宫的随机门具有两种不同的配置,一种用于训练阶段,一种用于测试阶段。在训练过程中,每次智能体到达目标时,门的状态(打开或关闭)都会随机改变。至关重要的是,在训练过程中,呈现出通向目标最短路径的走廊(即靠近中央房间的走廊)的两端均被关闭,从而无法进入或观察内部空间。在测试时,智能体第一次达到目标后,所有门都打开。所有智能体被测试了100个episode,每个episode持续了5400个环境步骤(90s)的固定持续时间。
Agent architectures.
Architecture for the grid cell agent. 智能体架构(扩展数据中的图5)由可视模块,网格细胞网络(如上所述)和执行者-评论者学习器组成41。视觉模块是一个神经网络,其输入由三通道(RGB)64×64图像Φ∈[-1, 1]3×84×84组成。图像由CNN处理(有关详细信息,请参见补充方法),该过程产生嵌入![]() ,进而将其用作以监督方式训练的全连接线性层的输入,以预测位置和头部方向细胞联合激活,
,进而将其用作以监督方式训练的全连接线性层的输入,以预测位置和头部方向细胞联合激活,![]() 和
和![]() (如上所述)。预测的位置和头部方向的细胞活动模式平均以5%的时间提供给网格网络,这类似于动物表现出明显的环境信号时偶尔出现的不完美观察27。具体来说,然后将卷积网络的输出
(如上所述)。预测的位置和头部方向的细胞活动模式平均以5%的时间提供给网格网络,这类似于动物表现出明显的环境信号时偶尔出现的不完美观察27。具体来说,然后将卷积网络的输出![]() 通过掩膜层,以95%的概率将这些单元置零。
通过掩膜层,以95%的概率将这些单元置零。
智能体的网格细胞网络按照监督学习设置进行实施,所不同的是,LSTM(“网格LSTM”)未使用真实位置细胞激活进行初始化,而是设置为零。网格细胞网络的输入是u和v这两个平移速度,因为在DeepMind实验室中,可以沿与面对方向不同的方向移动。角速度![]() 的正弦和余弦(这些速度由DeepMind实验室提供);视觉模块输出
的正弦和余弦(这些速度由DeepMind实验室提供);视觉模块输出![]() 和
和![]() 。与监督学习情况相反,这里的网格细胞网络必须在每次将其传送到环境中的任意位置(例如,访问目标之后)时使用
。与监督学习情况相反,这里的网格细胞网络必须在每次将其传送到环境中的任意位置(例如,访问目标之后)时使用![]() 和
和![]() 来学习如何重置其内部状态。与上述监督学习实验一样,位置场的配置(即11×11环境中位置场中心的位置,目标驱动和目标门,10×10方形运动场和13×13双重E迷宫)在整个训练过程中(即各个episode)保持不变。
来学习如何重置其内部状态。与上述监督学习实验一样,位置场的配置(即11×11环境中位置场中心的位置,目标驱动和目标门,10×10方形运动场和13×13双重E迷宫)在整个训练过程中(即各个episode)保持不变。
对于执行者-评论者学习器,输入的是三通道64×64图像Φt∈[−1, 1]3×84×84,该图像由CNN处理,然后是全连接层(有关详细信息,请参阅补充方法)。然后将卷积网络![]() 的全连接层的输出与奖励rt,先前动作at-1,当前网格代码
的全连接层的输出与奖励rt,先前动作at-1,当前网格代码![]() 和目标网格代码
和目标网格代码![]() (即上一次达到目标时观察到的线性层激活)——如果episode中尚未达到目标,则为零。请注意,为简洁起见,我们将这些线性层激活称为“网格代码”,即使该层中的单元还包括类似于头部方向细胞和边界细胞的单元(扩展数据中的图6a)。此连接的输入提供给具有256个单元的LSTM。LSTM有两个不同的输出。第一个输出(执行者)是一个具有六个单元的线性层,其后是softmax激活函数,该函数表示智能体的下一个动作的分类分布。第二个输出(评论者)是估计价值函数的单个线性单元。请注意,为简便起见,我们将其称为“策略LSTM”,即使它也输出价值函数。
(即上一次达到目标时观察到的线性层激活)——如果episode中尚未达到目标,则为零。请注意,为简洁起见,我们将这些线性层激活称为“网格代码”,即使该层中的单元还包括类似于头部方向细胞和边界细胞的单元(扩展数据中的图6a)。此连接的输入提供给具有256个单元的LSTM。LSTM有两个不同的输出。第一个输出(执行者)是一个具有六个单元的线性层,其后是softmax激活函数,该函数表示智能体的下一个动作的分类分布。第二个输出(评论者)是估计价值函数的单个线性单元。请注意,为简便起见,我们将其称为“策略LSTM”,即使它也输出价值函数。
Comparison agents. 我们比较了网格细胞智能体与两种智能体的性能,具体是因为它们对空间使用了不同的表示方案(即位置细胞智能体,位置细胞预测智能体),并且与神经科学文献中针对目标的导航的理论模型有关(例如42,43)。我们还比较了网格细胞智能体和基准深度强化学习智能体(异步优势执行者-评论者(A3C)41)。
Place cell agent. 位置细胞智能体结构在扩展数据中的图8b中显示,在补充方法中有更详细的描述。与网格细胞智能体相反,位置细胞智能体使用真实信息:具体来说,真实位置![]() 和头部方向
和头部方向![]() ,细胞激活(如上所述)。以类似于在网格细胞智能体中提供网格代码的方式,将这些活动向量作为策略LSTM的输入提供。
,细胞激活(如上所述)。以类似于在网格细胞智能体中提供网格代码的方式,将这些活动向量作为策略LSTM的输入提供。
具体来说,将卷积网络![]() 的全连接层的输出与奖励rt,先前动作at-1,真实的当前位置代码
的全连接层的输出与奖励rt,先前动作at-1,真实的当前位置代码![]() 和当前头部方向代码
和当前头部方向代码![]() 连接起来 ,以及最后一次达到目标时观察到的真实目标位置代码
连接起来 ,以及最后一次达到目标时观察到的真实目标位置代码![]() 和真实头部方向代码
和真实头部方向代码![]() ——如果在episode中尚未达到目标,则为零(扩展数据中的图8b)。卷积网络具有与网格细胞智能体相同的架构。
——如果在episode中尚未达到目标,则为零(扩展数据中的图8b)。卷积网络具有与网格细胞智能体相同的架构。
Place cell prediction agent. 位置细胞预测智能体的架构(扩展数据中的图9a)类似于上述网格细胞智能体的架构:关键区别在于如下所述的提供给策略LSTM的输入的性质。位置细胞预测智能体具有一个网格细胞网络,该网络具有与网格细胞智能体相同的参数。但是,我们没有使用来自网格网络线性层![]() 的网格代码作为策略LSTM的输入(如在网格细胞智能体中一样),而是使用了预测的位置细胞群体活动向量
的网格代码作为策略LSTM的输入(如在网格细胞智能体中一样),而是使用了预测的位置细胞群体活动向量![]() 和头部方向群体活动向量
和头部方向群体活动向量![]() (在每个时间步骤出现在网格细胞网络的输出位置和头部方向单元层上的激活;请参阅补充方法)。
(在每个时间步骤出现在网格细胞网络的输出位置和头部方向单元层上的激活;请参阅补充方法)。
位置细胞智能体与位置细胞预测智能体(分别参见扩展数据中的图8b和9a)之间的关键区别在于,前者使用真实信息(当前位置与目标位置的位置和头部方向细胞激活),而后者使用与网格细胞智能体相同的网格网络线性层,在输出位置和头部方向的单元层上生成的群体活动(用于当前位置和目标位置)。
A3C. 我们用卷积网络实现了异步优势执行者-评论者结构41,其中卷积网络的结构与网格细胞智能体所描述的结构相同(扩展数据中的图8a)。
Other agents. 我们还评估了带有外部记忆的两个深度强化学习智能体的性能(扩展数据中的图9b),这些学习智能体用于确定多隔室环境(目标门和目标驱动)的挑战性。首先,我们实现了一个由FRMQN结构3组成的记忆网络智能体(NavMemNet),但是我们使用下面描述的A3C算法代替了Q学习。此外,存储器的输入是作为LSTM控制器(扩展数据中的图9b)的输出而生成的,而不是构成来自卷积网络的嵌入(即参考3)。卷积网络具有与网格细胞智能体相同的架构,并且记忆由两个存储体(键和值)组成,每个存储体具有1350个slot。
其次,我们实现了可微神经计算机(DNC)智能体,该智能体使用基于内容的检索并写入最近使用或最少使用的记忆slot44。



Neuroscience-based analyses of network units.
Generation of activity maps. 如下计算各个单元的空间(ratemaps)和定向活动图。轨迹中的每个点都根据其位置和面向的方向分配给特定的空间和方向容器。空间容器定义为跨越每个环境的32×32正方形网格,方向容器定义为20个等宽间隔。然后,对于每个单元,找到分配给该容器的所有轨迹点的平均活动。这些值无需进一步平滑即可显示和进一步分析。
Inter-trial stability. 对于每个单元,通过计算在训练中的两个不同记录步骤(t = 2×105;t' = 3×105)下成对的ratemap对之间的空间相关性,来评估基准试验之间空间发放的可靠性。总训练时间为3×105,因此选择的点具有足够的时间差,以最大程度地减少发现随机相关性的机会。在两次试验的等效容器之间计算了Pearson乘积矩相关系数,将未访问的容器从测量中排除。
Quantification of spatial activity. 在可能的情况下,我们使用神经科学文献中采用的方法评估了单元的空间调节。使用网格度得分18,20和网格比例20量化了网格状图案的六边形规则性和比例,网格度是从每个单元ratemap的空间自动核图20得出的。类似地,使用定向活动图的合成矢量47的长度评估每个单元显示的定向调节度。最后,使用边界得分48来量化单元沿环境边界发放的倾向。
线性层中各单元所显示的网格度和边界得分是根据应用到每个单元的ratemap上的置换程序(空间场改组49)获得的空分布的95th百分位数进行基准测试的。这种改组程序旨在在每个ratemap中保留场的局部地形,同时将场本身随机分配49。所获得的阈值的均值(按单元)为网格度>0.37和边界得分>0.50。超过这些阈值的单元分别被认为是网格状和边界状。为了识别定向调节单元,我们将定向均匀性的Rayleigh测试应用于合并的定向活动图。如果统一的零假设在α = 0.01的水平上被拒绝,则认为该单元是定向调节的单元,对应于合成矢量长度超过0.47的单元(请参阅补充方法)。
Clustering of scale in grid-like units. 为了确定类似网格的单元是否表现出在特定尺度上聚集的趋势,我们应用了两种方法。首先,为了确定网格状单元的标度(网格度>0.37,129/512单元)是否遵循连续分布或离散分布,我们计算了其尺度分布的离散度度量22(请参阅补充方法)。发现真实数据的离散度得分超过所有500个随机排序的得分。其次,为了刻画尺度簇的数量和位置,将网格状单元的尺度分布与高斯混合分布拟合,发现三个分量提供了最简约的拟合,表明存在三个尺度簇(请参阅补充方法)。
Multivariate decoding of representation of metric quantities within LSTM. 为了测试网格智能体是否学会使用预测的基于矢量的导航(VBN)度量代码,我们记录了策略LSTM层的隐含单元的激活,同时智能体在陆地迷宫中导航了200个episode。我们使用L2正则化(岭)回归解码欧氏距离和目标的同心轴方向(有关完整解码的详细信息,请参阅补充方法)。我们在导航的早期特别关注了十二个步骤(步骤9-21),但是在智能体有时间进行准确的自身定位之后。在智能体首次达到目标之后的这个早期阶段,VBN策略应该是最有效的。我们对位置单元智能体控制进行了相同的分析,预计不会有效地使用基于矢量的导航。解码精度被测量为保留数据中预测度量值与实际度量值之间的相关性。通过评估智能体之间解码相关性的差异,比较了不同智能体之间的解码精度。使用bootstrap的方法(使用10000个样本)来计算此相关差异的95%置信区间,并为每次比较报告这些。在陆地迷宫的病变网格智能体中,使用相同的方法来解码和比较这两个指标。最后,为了在更复杂的环境中探索VBN指标,将相同的方法应用于目标驱动的任务。在这种情况下,我们还研究了控制A3C智能体中的度量解码。
Reporting summary. 有关实验设计的更多信息,请参见与本文链接的《自然研究报告摘要》。
Data availability statement. 本文中描述的所有强化学习任务都是使用可公开获得的DeepMind实验室平台(https://github.com/deepmind/lab)构建的。 目标驱动任务和目标门任务都包含在最新版本中,分别名为explorer_goal_locations和explorer_obstructed_goals。
Code availability statement. 我们将在接下来的六个月内发布用于监督学习实验的代码。深度强化学习智能体的代码库使用专有组件,因此我们无法公开发布此代码。但是,对所有实验和智能体进行了足够详细的描述,以允许独立复现。