郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS 30 (NIPS 2017), (2017): 6379-6390
Abstract
我们探索了多智能体领域的深度强化学习方法。我们首先分析传统算法在多智能体情况下的难度:Q学习受到环境固有的非平稳性的挑战,而策略梯度受到随着智能体数量增加而增加的方差的影响。然后,我们提出了一种对 actor-critic方法的改进,该方法考虑了其他智能体的动作策略,并且能够成功地学习需要复杂的多智能体协调的策略。此外,我们引入了一种训练方案,该方案利用针对每个智能体的一组策略,从而产生更强大的多智能体策略。与合作和竞争场景中的现有方法相比,我们展示了我们的方法的优势,其中智能体群体能够发现各种物理和信息协调策略。
1 Introduction
2 Related Work
3 Background
4 Methods
4.1 Multi-Agent Actor Critic
我们在上一节中已经讨论过,朴素策略梯度方法在简单的多智能体设置中表现不佳,这在我们第5节的实验中得到了支持。我们在本节中的目标是推导出一种在此类设置中运行良好的算法。然而,我们希望在以下约束下运行:(1) 学到的策略在执行时只能使用局部信息(即他们自己的观察),(2) 我们不假设环境动态的可微模型,不像[25],以及(3) 我们不假设智能体之间的通信方法有任何特定的结构(也就是说,我们不假设可微的通信渠道)。实现上述需求将提供一种通用的多智能体学习算法,该算法不仅可以应用于具有明确通信渠道的合作游戏,还可以应用于竞争游戏和仅涉及智能体之间物理交互的游戏。
与[8]类似,我们通过采用分散执行的集中训练框架来实现我们的目标。因此,只要在测试时不使用这些信息,我们就允许策略使用额外的信息来简化训练。用Q学习做到这一点是不自然的,因为Q函数在训练和测试时通常不能包含不同的信息。因此,我们提出了actor-critic策略梯度方法的简单扩展,其中用关于其他智能体的策略的额外信息来增强critic。
更具体地说,考虑一个具有N个智能体的游戏,其策略参数化为![]() ,令
,令![]() 为所有智能体策略的集合。然后我们可以将智能体 i 的期望回报的梯度,
为所有智能体策略的集合。然后我们可以将智能体 i 的期望回报的梯度,![]() 写为:
写为:
![]()

请注意,我们需要其他智能体的策略来应用等式6中的更新。了解其他智能体的观察和策略并不是特别严格的假设;如果我们的目标是训练智能体在模拟中表现出复杂的交流行为,则这些信息通常可供所有智能体使用。然而,如果有必要,我们可以通过从观察中学习其他智能体的策略来放松这个假设——我们在4.2节中描述了一种这样做的方法。
4.2 Inferring Policies of Other Agents

4.3 Agents with Policy Ensembles
如前所述,多智能体强化学习中一个反复出现的问题是由于智能体不断变化的策略导致环境的非平稳性。在竞争环境中尤其如此,智能体可以通过过拟合竞争对手的行为来制定强有力的策略。这种策略是不可取的,因为它们很脆弱,并且当竞争对手改变策略时可能会失败。
为了获得对竞争智能体的策略变化更稳健的多智能体策略,我们提出训练 K 个不同子策略的集合。在每一个回合中,我们为每个智能体随机选择一个特定的子策略来执行。假设策略μi是K个不同子策略的集合,子策略 k 表示为![]() (表示为
(表示为![]() )。对于智能体 i,我们然后最大化集成目标:
)。对于智能体 i,我们然后最大化集成目标:![]()
由于不同的子策略将在不同的回合中执行,我们为智能体 i 的每个子策略![]() 维护一个回放缓存
维护一个回放缓存![]() 。因此,我们可以推导出集合目标关于
。因此,我们可以推导出集合目标关于![]() 的梯度如下:
的梯度如下:
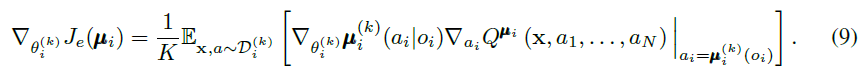
5 Experiments1
5.1 Environments
为了进行我们的实验,我们采用了[25]3中提出的接地通信环境,它由N个智能体和L个地标组成,它们居住在具有连续空间和离散时间的二维世界中。智能体可能会在环境中采取物理动作,以及向其他智能体广播的通信动作。与[25]不同,我们不假设所有智能体都具有相同的动作和观察空间,或根据相同的策略π行动。我们还考虑了合作(所有智能体必须最大化共享回报)和竞争(智能体有相互冲突的目标)的游戏。有些环境需要智能体之间进行明确的通信才能获得最优奖励,而在其他环境中智能体只能执行物理动作。我们在下面提供了每个环境的详细信息。
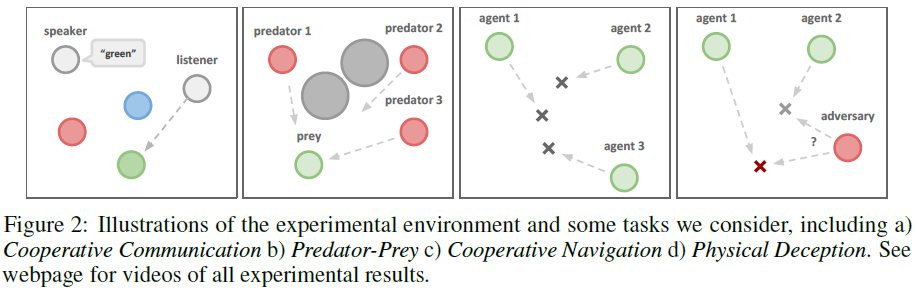
Cooperative communication. (协作沟通) 该任务由两个合作智能体组成,一个说话者和一个聆听者,它们被放置在具有三个不同颜色的地标的环境中。在每一个回合,聆听者必须导航到特定颜色的地标,并根据它与正确地标的距离获得奖励。然而,虽然聆听者可以观察地标的相对位置和颜色,但它不知道它必须导航到哪个地标。相反,说话者的观察由正确的地标颜色组成,它可以在聆听者观察到的每个时间步骤产生通信输出。因此,说话者必须学会根据聆听者的动作输出地标颜色。尽管这个问题相对简单,但正如我们在5.2节中展示的那样,它对传统的RL算法提出了重大挑战。
- 两个智能体,一个是 speaker,一个是 listener。(灰色)
- 三个地标 landmarks。(红绿蓝)
- 游戏任务:
- listener 导航到特定颜色的 landmark,如果成功抵达,listener 将得到奖励
- listener 知道所有 landmark 的颜色,并且知道到每个 landmark 的距离,但是 listener 并不知道正确的 landmark 颜色是哪个
- speaker 知道正确的 landmark 颜色,speaker 需要学会基于 listener 的移动来推测每个 landmark 颜色
Cooperative navigation. (协作导航) 在这种环境中,智能体必须通过物理动作进行协作才能到达一组L个地标。智能体观察其他智能体和地标的相对位置,并根据任何智能体与每个地标的接近程度共同获得奖励。换句话说,智能体必须"覆盖"所有地标。此外,智能体占用大量物理空间并在相互碰撞时受到惩罚。我们的智能体学会推断它们必须覆盖的地标,并在避开其他智能体的同时移动到那里。
- L 个 landmarks,N 个智能体
- 游戏任务:每个智能体占领一个 landmark (就跟占板凳游戏一样)
- 观察:到其它 agents 和 landmarks 的距离
- 奖励:任意智能体到每个 landmark 的距离
- 如果智能体之间发生碰撞,则会受到惩罚
- 每个智能体需要学会推断他们应该 cover 的 landmark
Keep-away. (远离) 这个场景包括L个地标,包括一个目标地标,N个知道目标地标并根据它们与目标的距离获得奖励的合作智能体,以及M个必须阻止合作智能体到达目标的对抗性智能体。对手通过物理地将智能体推离地标,暂时占据它来实现这一点。虽然对手也根据与目标地标的距离进行奖励,但它们不知道正确的目标;这必须从智能体的移动中推断出来。
- L 个 landmarks,其中一个是 target landmark
- N 个协作智能体
- 协作智能体知道 target landmark 位置
- 奖励是到 target landmark 的距离
- M 个对手智能体
- 防止协作智能体抵达 target landmark
- 奖励是到 target landmark 的距离
- 对手智能体不知道正确的 target landmark 位置
- 对手智能体需要根据协作智能体的移动来推断正确的 target landmark 位置
Physical deception. (物理欺骗) 在此,N个智能体合作从总共N个地标中到达单个目标地标。它们根据任何智能体到目标的最小距离获得奖励(因此只有一个智能体需要到达目标地标)。然而,一个孤独的对手也希望到达目标地标;问题是对手不知道哪个地标是正确的。因此,根据对手与目标的距离而受到惩罚的合作智能体,学会分散并覆盖所有地标以欺骗对手。
- N 个 landmarks,N 个协作智能体,1 个对手智能体
- 协作智能体:
- 只有一个 target landmark,协作智能体目标是抵达 target landmark
- 奖励:离 target landmark 最近的智能体到 target landmark 的距离
- 惩罚:对手到 target landmark 的距离
- 协作智能体需要学会分开行动和 cover 所有的 landmark 来迷惑和欺骗对手
- 对手智能体:
- 目标也是抵达 target landmark
- 但是对手智能体不知道 target landmark 是哪个,需要根据协作智能体行为来推断
Predator-prey. (捕食者-被捕食者) 在经典捕食者-猎物游戏的这种变体中,N个较慢的合作智能体必须在随机生成的环境中追逐速度较快的对手,其中L个大地标阻碍了前进的道路。每次合作智能体与对手发生碰撞时,智能体都会得到奖励,而对手则受到惩罚。智能体观察智能体的相对位置和速度,以及地标的位置。
- N 个速度慢的协作智能体,1 个速度快的对手智能体,L 个 landmarks(障碍物)
- 协作智能体要追逐对手智能体
- 如果协作智能体和对手智能体发生碰撞,协作智能体得到奖励,对手得到惩罚
- 智能体的观察:
- 智能体的相对位置和速度
- landmarks 的位置
Covert communication. 这是一个对抗性的通信环境,其中说话者智能体('Alice')必须将消息传达给聆听者智能体('Bob'),后者必须在另一端重建消息。然而,一个对抗智能体('Eve')也在观察通道,并想要重建消息——Alice和Bob根据Eve的重建受到惩罚,因此Alien必须使用随机生成的密钥(只有Alien和Bob知道)对她的消息进行编码。这类似于[2]中考虑的密码学环境。
1 我们的实验结果的视频可以在这里看到:https://sites.google.com/site/multiagentac/
3 代码可以在这里找到:https://github.com/openai/multiagent-particle-envs
5.2 Comparison to Decentralized Reinforcement Learning Methods
5.3 Effect of Learning Polices of Other Agents
5.4 Effect of Training with Policy Ensembles
6 Conclusions and Future Work
Appendix
Multi-Agent Deep Deterministic Policy Gradient Algorithm
Experimental Results
Variance of Policy Gradient Algorithms in a Simple Multi-Agent Setting