参考链接:100万帧数据仅1秒!AI大牛颜水成团队强化学习新作,代码已开源 (qq.com)
GTC 2021演讲:https://events.rainfocus.com/widget/nvidia/nvidiagtc/sessioncatalog/session/1630239583490001Z5dE

论文:

开源代码:
EnvPool是一种高度并行的强化学习环境执行引擎,其性能明显优于现有环境执行器。通过专用于RL用例的策划设计,我们利用通用异步执行模型的技术,在环境执行中使用C++线程池实现。
以下是EnvPool的几个亮点:
- 兼容OpenAI gym API和DeepMind dm_env API;
- 管理一个envs池,默认与批处理API中的envs交互;
- 同步执行API和异步执行API;
- 用于添加新环境的简单C++开发人员API;
- 每秒模拟100万Atari帧,具有256个CPU内核,吞吐量是基于Python子进程的向量环境的约13倍;
- 在低资源设置(如12个CPU内核)上,吞吐量是基于Python子进程的向量环境的吞吐量的约3倍;
- 与现有的基于GPU的解决方案(Brax/Isaac-gym)相比,EnvPool是各种加速RL环境并行化的通用解决方案;
- 兼容一些现有的强化学习库,例如Tianshou。
Installation
PyPI
EnvPool目前托管在PyPI上。它需要Python≥3.7。您可以使用以下命令简单地安装EnvPool:
$ pip install envpool
安装后,打开Python控制台并输入:
import envpool print(envpool.__version__)
From Source
请参考guideline.
Documentation
教程和API文档托管在envpool.readthedocs.io.
示例代码位于文件夹examples/.
Supported Environments
我们正在从我们的内部版本中开源所有可用的环境,敬请期待。

Benchmark Results
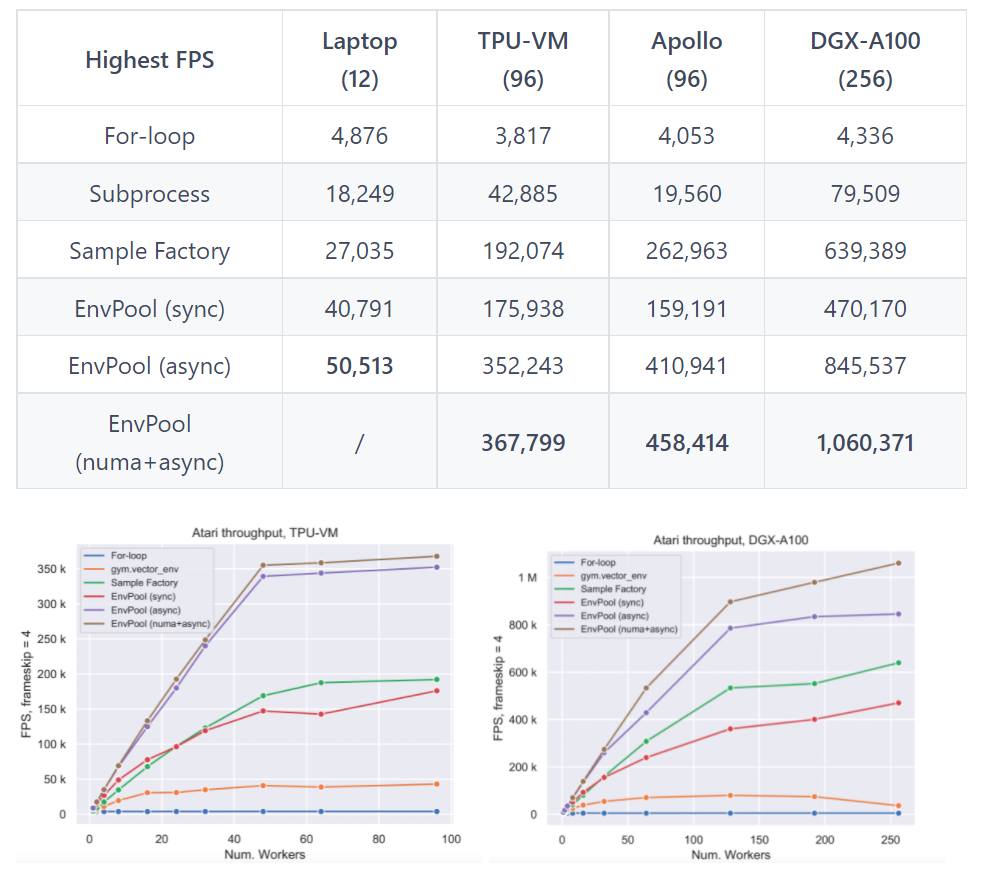
我们使用ALE Atari环境(带有环境包装器)在不同硬件设置上执行基准测试,包括具有96个CPU内核和2个NUMA节点1的TPUv3-8虚拟机(VM),以及具有256个CPU内核和8个NUMA节点的NVIDIA DGX-A100节点。基准包括1) 简单的Python for循环;2) 最流行的RL环境并行化执行Python子进程,例如,gym.vector_env;3) 据我们所知,EnvPool之前最快的RL环境执行器Sample Factory。
我们报告了同步模式、异步模式和NUMA + 异步模式下的EnvPool性能,与不同数量的工作线程(即CPU内核数量)的基准进行比较。从结果中可以看出,EnvPool在所有设置的基准上都取得了显著的改进。在高端设置上,EnvPool在256个CPU内核上实现了每秒100万帧,这是gym.vector_env基准的13.3倍。在具有12个CPU内核的典型PC设置上,EnvPool的吞吐量是gym.vector_env的2.8倍。
我们的基准测试脚本在examples/benchmark.py中。4类系统的详细配置为:
- Personal laptop: 12 core
Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz - TPU-VM: 96 core
Intel(R) Xeon(R) CPU @ 2.00GHz - Apollo: 96 core
AMD EPYC 7352 24-Core Processor - DGX-A100: 256 core
AMD EPYC 7742 64-Core Processor
1 NUMA (Non Uniform Memory Access)技术可以使众多服务器像单一系统那样运转,同时保留小系统便于编程和管理的优点。非统一内存访问(NUMA)是一种用于多处理器的电脑内存体设计,内存访问时间取决于处理器的内存位置。在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些。
基准测试脚本(examples/benchmark.py):


import argparse import time import numpy as np import envpool if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--task", type=str, default="Pong-v5") parser.add_argument("--num-envs", type=int, default=645) parser.add_argument("--batch-size", type=int, default=248) # num_threads == 0 means to let envpool itself determine parser.add_argument("--num-threads", type=int, default=0) # thread_affinity_offset == -1 means no thread affinity parser.add_argument("--thread-affinity-offset", type=int, default=0) parser.add_argument("--total-iter", type=int, default=50000) args = parser.parse_args() env = envpool.make_gym( "Pong-v5", num_envs=args.num_envs, batch_size=args.batch_size, num_threads=args.num_threads, thread_affinity_offset=args.thread_affinity_offset, ) env.async_reset() action = np.ones(args.batch_size, dtype=np.int32) t = time.time() for _ in range(args.total_iter): info = env.recv()[-1] env.send(action, info["env_id"]) duration = time.time() - t fps = args.total_iter * args.batch_size / duration * 4 print(f"Duration = {duration:.2f}s") print(f"EnvPool FPS = {fps:.2f}")
envpool.list_all_envs():
>>> envpool.list_all_envs() ['Solaris-v5', 'BeamRider-v5', 'Earthworld-v5', 'YarsRevenge-v5', 'VideoCube-v5', 'MsPacman-v5', 'MazeCraze-v5', 'Tennis-v5', 'Klax-v5', 'Berzerk-v5', 'TicTacToe3d-v5', 'Asteroids-v5', 'Superman-v5', 'Seaquest-v5', 'VideoPinball-v5', 'MrDo-v5', 'Surround-v5', 'Kaboom-v5', 'AirRaid-v5', 'IceHockey-v5', 'Adventure-v5', 'MiniatureGolf-v5', 'ChopperCommand-v5', 'Robotank-v5', 'UpNDown-v5', 'JourneyEscape-v5', 'Atlantis2-v5', 'Blackjack-v5', 'WordZapper-v5', 'VideoCheckers-v5', 'Hero-v5', 'Pitfall-v5', 'SirLancelot-v5', 'Jamesbond-v5', 'SpaceWar-v5', 'Alien-v5', 'Frostbite-v5', 'Hangman-v5', 'DemonAttack-v5', 'Qbert-v5', 'LostLuggage-v5', 'StarGunner-v5', 'HumanCannonball-v5', 'Othello-v5', 'Galaxian-v5', 'BasicMath-v5', 'Pacman-v5', 'Combat-v5', 'KungFuMaster-v5', 'Darkchambers-v5', 'Et-v5', 'Gravitar-v5', 'Koolaid-v5', 'MarioBros-v5', 'Skiing-v5', 'Atlantis-v5', 'FishingDerby-v5', 'Freeway-v5', 'BankHeist-v5', 'RoadRunner-v5', 'Boxing-v5', 'Crossbow-v5', 'Zaxxon-v5', 'Warlords-v5', 'HauntedHouse-v5', 'Assault-v5', 'Breakout-v5', 'WizardOfWor-v5', 'FlagCapture-v5', 'Casino-v5', 'DonkeyKong-v5', 'Gopher-v5', 'ElevatorAction-v5', 'MontezumaRevenge-v5', 'Tutankham-v5', 'Krull-v5', 'Phoenix-v5', 'Enduro-v5', 'TimePilot-v5', 'Trondead-v5', 'KeystoneKapers-v5', 'Turmoil-v5', 'Venture-v5', 'LaserGates-v5', 'Pooyan-v5', 'Amidar-v5', 'Entombed-v5', 'Tetris-v5', 'Pong-v5', 'Pitfall2-v5', 'Frogger-v5', 'Joust-v5', 'Defender-v5', 'Riverraid-v5', 'NameThisGame-v5', 'Kangaroo-v5', 'VideoChess-v5', 'BattleZone-v5', 'Asterix-v5', 'CrazyClimber-v5', 'Centipede-v5', 'SpaceInvaders-v5', 'PrivateEye-v5', 'KingKong-v5', 'Bowling-v5', 'DoubleDunk-v5', 'Backgammon-v5', 'Carnival-v5']
envpool.make_gym(args):
- task_id:task id, use
envpool.list_all_envs()to see all support tasks; - num_envs:how many envs are in the envpool;how many envs are in the envpool, default to
1; - batch_size:async configuration, see the last section, default to
num_envs; - num_threads:the maximum thread number for executing the actual
env.step, default tobatch_size; - thread_affinity_offset:the start id of binding thread.
-1means not to use thread affinity in thread pool, and this is the default behavior;
>>> envpool.make_gym( ... "Pong-v5", ... num_envs=645, ... batch_size=248, ... num_threads=0, ... thread_affinity_offset=0, ... ) AtariGymEnvPool(num_envs=645, batch_size=248, num_threads=0, max_num_players=1, thread_affinity_offset=0, base_path='/opt/conda/lib/python3.8/site-packages/envpool', seed=42, max_episode_steps=25000, stack_num=4, frame_skip=4, noop_max=30, zero_discount_on_life_loss=False, episodic_life=False, reward_clip=False, img_height=84, img_width=84, task='pong')
API Usage
下面的内容展示了EnvPool的同步和异步API用法。您还可以在以下位置运行完整脚本examples/env_step.py
Synchronous API
import envpool import numpy as np # make gym env env = envpool.make("Pong-v5", env_type="gym", num_envs=100) # or use envpool.make_gym(...) obs = env.reset() # should be (100, 4, 84, 84) act = np.zeros(100, dtype=int) obs, rew, done, info = env.step(act)
在同步模式下,envpool与openai-gym/dm-env非常相似。具有同义的reset和step函数。但是有一个例外,在envpool中批处理交互是默认设置。因此,在创建envpool期间,有一个num_envs参数表示您希望并行运行多少个envs。
env = envpool.make("Pong-v5", env_type="gym", num_envs=100)
传递给step函数的action的第一个维度应该等于num_envs。
act = np.zeros(100, dtype=int)
当任何一个done为true时,您不需要手动重置一个环境,而是默认情况下envpool中的所有envs都启用了自动重置。
Asynchronous API
import envpool import numpy as np # make asynchronous env = envpool.make("Pong-v5", env_type="gym", num_envs=64, batch_size=16) env.async_reset() # send the initial reset signal to all envs while True: obs, rew, done, info = env.recv() action = np.random.randint(batch_size, size=len(info.env_id)) env.send(action, env_id)
在异步模式下,step函数分为两部分,即send/recv函数。send接受两个参数,一批动作,以及每个动作应发送到的相应env_id。与step不同的是,send不等待envs执行并返回下一个状态,它在将操作馈送到envs后立即返回。(之所以称为异步模式的原因)。
env.send(action, env_id)
要获得"下一个状态",我们需要调用recv函数。但是,recv并不能保证您会取回您刚刚调用send的环境的"下一个状态"。取而代之的是,无论envs首先完成执行什么,都会首先被recv。
state = env.recv()
除了num_envs,还有一个参数batch_size。num_envs定义了envpool总共管理了多少个envs,而batch_size定义了每次与envpool交互时涉及的envs数量。例如envpool中有64个envs在执行,每次与一批16个envs 交互时,send和recv。
envpool.make("Pong-v5", env_type="gym", num_envs=64, batch_size=16)
envpool.make还有其他可配置的参数,请查看envpool interface introduction.
Contributing
EnvPool仍在开发中。将添加更多环境,我们始终欢迎贡献以更好地帮助EnvPool。如果你想贡献,请查看我们的contribution guideline.
API使用总结:
目前来说,文档工作相对不足,很多细节并没有在样例中进行展示,例如如何在实际强化学习算法中调用等。所以在实际强化学习实验中,我总结了以下几点:
- env.reset():只重置那些未初始化的或者已经done的环境,返回的状态是0-255的像素值;
- env.recv():返回的状态是状态是0-255的像素值,奖励未经过裁剪;只有env刚经历过reset或者send之类的操作且还未调用过recv()函数,recv()才会返回值,否则是一个空数组;