# 1 web,app,微信小程序 # 2 web项目 -前端: -用cdn,静态资源,放到cdn上(js,css,静态图片) -用精灵图(一个大图,上面又很多小图,用定位,定位到小图) -前端缓存(响应头设置缓存时间)cache-control (django如何向响应头写键值对:响应对象["aaa"]="aaa") -nginx: -nginx做集群(dns解析,负载均衡硬件 f5)# dns解析到不同的nginx集群上(百度各地ip不同) 负载均衡硬件f5也能抗并发量,转到不同的nginx集群中(硬件层面实现) -动静分离(静态资源直接通过nginx转发,拿取;uwsgi只负责处理动态请求) -负载均衡(nginx的配置) -集群化部署 -拆服务(把项目做成分布式) -使用uwsgi(c写的wsgi服务器)部署,使用gunicorn(python写的wsgi服务器)部署 -代码层面: -缓存(redis)--》本来一个请求,要查5个表,耗时3s---》json格式--》放到缓存中--》下次再发请求,直接去缓存查---》0.001秒就返回了-----》(存在问题:缓存击穿,缓存穿透,缓存雪崩 双写一致性问题) -页面静态化(不适用于app和小程序),提前生成一个首页页面(被访问频繁的页面) # 下方代码示例 -/index--->(查数据库(用了缓存)---》dtl渲染页面)--》提前生成出index.hmtl---》django模板渲染 -数据不一致(当有数据增加,再重新生成一次这个页面),同步?异步? -用异步:用celery,django的信号(异步操作),当对象保存时,重新生成静态页面(celery有返回值,信号无返回值) -异步操作(celery),一个请求需要耗时3s,设计成异步--请来了--》直接返回(任务已提交,请求正在处理) -小米秒杀:您正在排队(前端设置了定时,每隔5s,发送一个请求,查是否秒杀成功) -保存视频,发送邮件,保存文章, -后台管理,统计最近三,五,半年,个月的订单量--》折线图,饼状图展示 -消息队列:rabbitmq,kafka。。。异步,解耦 -请求打到数据库了(只要打到数据库,性能就下来了) -优化sql,外键尽量不建立,适当建索引 -读写分离,数据库集群,分库分表 -优化代码,多线程处理,尽量不在for循环里查数据库 -换框架(异步框架),换语言 --最本质的一句,代码优化不了了,垒机器 django的cache如何实现的? -配置,缓存到文件,redis,mysql -可以缓存对象(set了对象,pickle序列化成二进制,存到了redis中) -cache.set() -cache.get()
# ================================django模板修改的视图函数 提前生成一个页面 # from django.template import Template,Context # now=datetime.datetime.now() # t=Template('<html><body>现在时刻是:<h1>{{current_date}}</h1></body></html>') #模板文件 # #t=get_template('current_datetime.html') # 或者获取一个模板文件 # c=Context({'current_date':str(now)}) # 把变量渲染进去 # html=t.render(c) # 生成字符串(完整的html页面),可以存入html格式文件 # # return HttpResponse(html) render('index.html',{'key':'value'}) # 此行用于回忆

# 1 产生背景:大规模数据如何检索,数据安全(单点故障),备份,检索速度 # mysql如果是innodb引擎在千万级数据量,速度直线下降 # 2 Elasticsearch介绍 -是一个基于Lucene的分布式搜索和分析引擎,全文检索引擎 -Elasticsearch使用Java开发 -但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单 # 3 Lucene与Elasticsearch关系 -Lucene只是java一个库----》只能java来使用 -python中集合--》只能python来用--》java,go用不了,其它语言想用,怎么做? -做成服务---》django搭建一个服务---》对外通过restful接口 ---> get /key post /key=value -基于Lucene封装 ,做成服务,通过restful来调用,使用全文检索 # 4 Elasticsearch vs solr -solr 也是一个全文检索引擎 -跟es关系就像是mysql和oracle的关系 -传统搜索用solr多,es新兴互联网用的多 # 5 es核心概念 -集群:多台服务器的集合,称为es的集群 -节点:集群的每个服务器称为节点 -分片:10g的数据(一个表中),对10g数据分片(自动调度),分成2g,3g,5g,把这些数据,分别放在不同的节点上(查任意一台服务器,都会在汇总的数据(自动调度,无需关注)中检索) -副本:为提高查询吞吐量或实现高可用性,可以使用分片副本(每个服务器备份其他服务器部分分片(自动调度),一旦某个服务器挂了,另一个服务器备份了他的数据部分升为分片,继续运行,
然后这些分片再做副本分配到其他服务器上;如果再加一台机器(数据必须为空或与其他节点数据相同),又会默默副本操作) -全文检索:分词,全文检索---》可以根据关键字搜索 # 6 es跟mysql比较 (存直接存文档不用建类型,索引,它会自己倒推;查索引->类型->文档) mysql es 数据库 索引(index) 表 类型(type) 一条一条数据 文档(document) 一列一列(字段) 字段(field)(name,age) 字段属性(主键,类型,索引) 映射(mapping) 索引 所有字段建索引(倒排索引)、 增删查改 get、post、delete。。。 # 7 ELK是什么? -ELK=elasticsearch+Logstash+kibana -日志的收集和分析系统 # Logstash日志搬运工,收集日志存到es中,kibana前端展示 # 8 Elasticsearch特点和优势 -笔记看一下即可 1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。 2)实时分析的分布式搜索引擎。 分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作; 负载再平衡和路由在大多数情况下自动完成。 3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试) 4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等 # 9 为什么使用es? -13年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索 -我们用在什么地方? -我们项目如果有搜索功能,都可以用 -日志存储分析 -大数据量的存储和检索 ** 应用场景:** 1)新系统开发尝试使用ES作为存储和检索服务器; 2)现有系统升级需要支持全文检索服务,需要使用ES # 10 Elasticsearch索引到底能处理多大数据 -es一个索引(数据库)可以有多个分片,一个分片是一个lucene的索引 -lucene一个索引不能处理多于21亿篇文档,或者多于2740亿的唯一词条 -理论上是可以无限加的 在线教育---》用户去浏览---》浏览记录---》停留时间(前端传给后端)---》存到日志---》日志分析的系统---》Linux感兴趣---》定向推荐----》linux课程上新了,打折了,短信推送,微信推送,都行 日志记录,收集
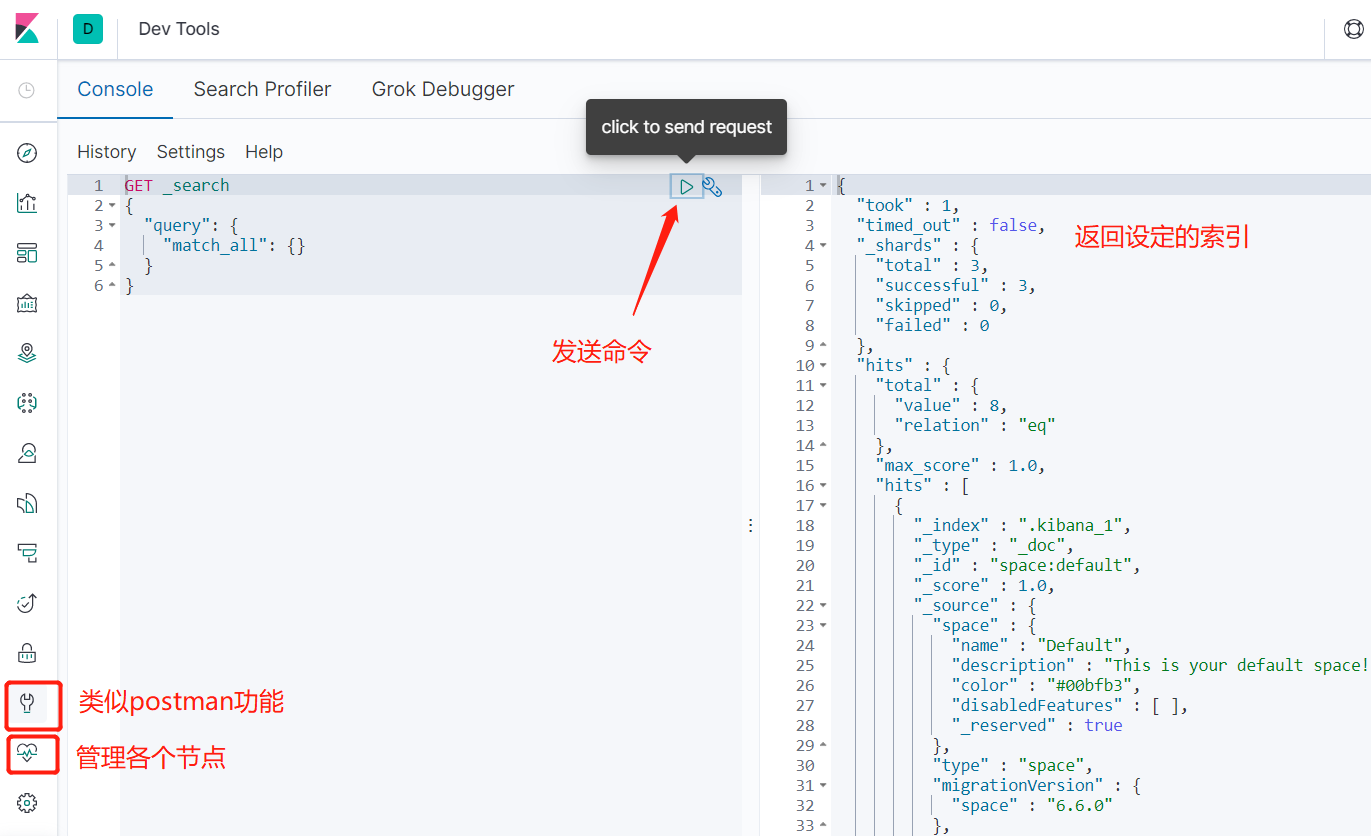
Elasticsearch-head连接如下
# 1 基于java开发的,安装jdk,windows上安装(jdk 1.8 以上),一路下一步(jdk,jre),(不需要配置环境变量了) #jre java运行环境 # jdk java开发 cmd下输入 java -version Java(TM) SE Runtime Environment (build 1.8.0_201-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode) # 2 安装es前下载(去官网下载相应的版本,es+kiban. 注意版本一定要对应一致) # 此次我下载:elasticsearch-7.5.0-windows-x86_64.zip kibana-7.5.0-windows-x86_64.zip -版本问题:2 5版本 6版本 7版本 7.6.2版本最新(讲课用7版本),公司可能会用6或者6之前的版本 -haystack:不支持es,6以上版本,django上做全文检索的框架(对接es,对接solr,对接whoosh) # django开源搜索框架 -whoosh-纯Python的全文搜索库,Whoosh是索引文本及搜索文本的类和函数库。它能让你开发出一个个性化的经典搜索引擎 -6以后,不允许一个索引下建多个type(类型)---》一个数据库只能有一个表 #6兼容,7只能有一表 # 3 解压到指定目录(随便,不要有空格,中文 c://soft ) # 4 启动es (如果在c盘,注意权限问题,可能kibana等工具无法删除文件等操作,放d盘保险) # 索引数据路径:..elasticsearch-7.5.0data odes� (单机配置) -cmd到es的bin路径下,输入elasticsearch.bat # 看到publish_address {127.0.0.1:9200}监听地址,已启动 浏览器输入http://127.0.0.1:9200/ 可看到版本等信息如下 { "name" : "LAPTOP-41G9JFOT", "cluster_name" : "elasticsearch", "cluster_uuid" : "SpkA_Se6TuyqMw9iT_m3wQ", "version" : { "number" : "7.5.0", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "e9ccaed468e2fac2275a3761849cbee64b39519f", "build_date" : "2019-11-26T01:06:52.518245Z", "build_snapshot" : false, "lucene_version" : "8.3.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } -Kibana 就是es的客户端(官方提供,相当于Navicat) -Elasticsearch-head 就是es的客户端(第三方的,相当于Navicat)#比Kibana好用 # 5 启动kibana -修改kibana配置文件 ..kibana-7.5.0-windows-x86_64configkibana.yml #里面最下面加入这4句话(顶格,去注释) server.port: 5601 # kibana监听端口号 server.host: "127.0.0.1" # kibana监听地址 server.name: lqz # 名字随便起 elasticsearch.hosts: ["http://localhost:9200/"] # 让kibana连到es上 -配置跨域(改es的配置) # 因为端口不一样 修改完配置,重启es -elasticsearch.yml ..elasticsearch-7.5.0configelasticsearch.yml #最下面加入 http.cors.enabled: true # 允许跨域 http.cors.allow-origin: "*" # 允许的域,任意客户端来访问 -cmd到kibana的bin路径下,输入kibana.bat 启动 # 得到http server running at http://127.0.0.1:5601 浏览器访问 # 6 启动Elasticsearch-head(第三方用node 写的一个es客户端) -node 环境要装好 -下载:https://github.com/mobz/elasticsearch-head -解压 -执行 (进入Elasticsearch-head文件夹,cmd下运行下方2行代码) npm install # 装依赖 npm run start # 启动 返回http://localhost:9100 http://localhost:9100/ # 输入浏览器 # kibana:官方提供的es客户端,主要用来做增删查改,有提示(postman,Elasticsearch-head) # Elasticsearch-head :看集群的状态,索引的状态 # 你在工作中碰到的问题和如何解决的? -django+haystack+whoosh 实现全文检索 -换成es,性能更高 目标 -项目里加全文检索,django---》haystack---》es版本必须6以下 问题 -django+es原生操作---》实现了全文检索 # 原生操作也就是http请求