自己的主机上的Hadoop版本是2.7.6,是测试用的伪分布式Hadoop,在前段时间部署了Hive on Spark,但由于没有做好功课,导致了Hive无法正常启动,原因在于Hive 3.x版本不适配Hadoop 2.x版本。之前我在学校服务器上部署的Hadoop版本是3.1.2,现打算将自己的从2.7.6升级到3.1.2版本,同时也当作练练手并记录以便以后参考。这是一个大版本跨度的升级操作,所以先参考Hadoop权威指南上的方案以及官方文档,然后拟定了升级和回滚方案。
根据官方文档所说:
”For non-HA clusters, it is impossible to upgrade HDFS without downtime since it requires restarting the namenodes. However, datanodes can still be upgraded in a rolling manner.“
也就是说对于非HA群集,由于需要重新启动名称节点,因此无法在没有停机的情况下升级HDFS。但是,仍可以回滚方式升级datanode。
注意:仅从Hadoop-2.4.0开始支持滚动升级。
Hadoop升级最主要是HDFS的升级,HDFS的升级是否成功,才是升级的关键,如果升级出现数据丢失,则其他升级就变得毫无意义。
解决方法:
- 备份HDFS的NameNode元数据,升级后,对比升级前后的文件信息。
- 单台升级DataNode,观察升级前后的Block数(有较小浮动范围,v2与v3的计数方式不一样)。
第一阶段 停机以及备份NameNode目录
通过命令stop-yarn.sh和stop-dfs.sh关闭HDFS集群:
# stop-yarn.sh # stop-dfs.sh
然后备份NameNode目录到NFS或者其他文件系统中,如果不记得NameNode目录存储的地址可以通过查看hdfs-site.xml文件的:
# vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml

第二阶段 在集群上安装新版本的Hadoop
下载Hadoop 3.1.2后解压,最好移除PATH环境变量下的Hadoop脚本,这样的话,就不会混淆针对不同版本的脚本。将HADOOP_HOME指向新的Hadoop:

接下来将${HADOOP_HOME}/etc/hadoop/hdfs-site.xml中的dfs.namenode.name.dir和dfs.datanode.data.dir属性的值分别指向Hadoop 2.7.6的hdfs-site.xml的dfs.namenode.name.dir和dfs.datanode.data.dir属性的值。
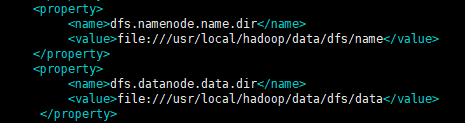
第三阶段 准备滚动升级
在hdfs-site.xml增加属性:
<property> <name>dfs.namenode.duringRollingUpgrade.enable</name> <value>true</value> </property>
先启动旧版本的Hadoop:
# /usr/local/hadoop/sbin/start-dfs.sh
进入安全模式:
# hdfs dfsadmin -safemode enter

准备滚动升级:
1. 运行“hdfs dfsadmin -rollingUpgrade prepare”以创建用于回滚的fsimage。
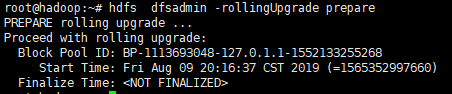
2. 运行"hdfs dfsadmin -rollingUpgrade query"以检查回滚映像的状态。等待并重新运行该命令,直到显示“继续滚动升级”消息。
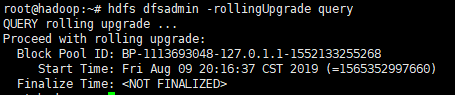
第四阶段 升级NN与SNN
1. 关闭SNN:
# /usr/local/hadoop/sbin/hadoop-daemon.sh stop secondarynamenode
2. 关闭NameNode和DataNode:
# /usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
# /usr/local/hadoop/sbin/hadoop-daemon.sh stop datanode
3. 在新版本的Hadoop使用“-rollingUpgrade started”选项启动NN:
进入新版本的Hadoop目录,然后以升级的方式启动NameNode:
# $HADOOP_HOME/bin/hdfs --daemon start namenode -rollingUpgrade started
升级hdfs花费的时间不长,升级丢失数据的风险几乎没有。
接下来升级并重启SNN:
# $HADOOP_HOME/bin/hdfs --daemon start secondarynamenode
第五阶段 升级DN
由于我升级的Hadoop是伪分布式的,NameNode和DataNode是在同一节点上,按集群升级分类来说,属于非HA集群升级。在这里,升级DataNode是比较简单的,在新版本的Hadoop上重新启动DataNode即可,等待一会,DataNode自动升级成功。
# $HADOOP_HOME/bin/hdfs --daemon start datanode
无论Hadoop是非HA还是HA,且是完全分布式的话,DataNode节点较多的情况下,可以参考官方文档的思路(写脚本实现):
- 选择一小部分数据节点(例如特定机架下的所有数据节点)
- 运行“hdfs dfsadmin -shutdownDatanode <DATANODE_HOST:IPC_PORT> upgrade”以关闭其中一个选定的数据节点。
- 运行"hdfs dfsadmin -getDatanodeInfo <DATANODE_HOST:IPC_PORT>"以检查并等待datanode关闭。
- 升级并重新启动datanode
- 对子集中所有选定的数据节点并行执行上述步骤。
2. 重复上述步骤,直到升级群集中的所有数据节点。
等待升级完成后,可以查看Web页面,NameNode和DataNode版本已经升级为3.1.2版本:


此时可以已完成滚动升级:
# $HADOOP_HOME/bin/hdfs dfsadmin -rollingUpgrade finalize

如果升级失败,可以随时回滚,回滚,数据会回滚到升级前那一刻的数据,升级后的数据修改,全部失效,回滚启动步骤如下:
# /usr/local/hadoop/bin/hadoop-daemon.sh start namenode –rollback # /usr/local/hadoop/bin/hadoop-daemon.sh start datanode –rollback
遇到的问题:
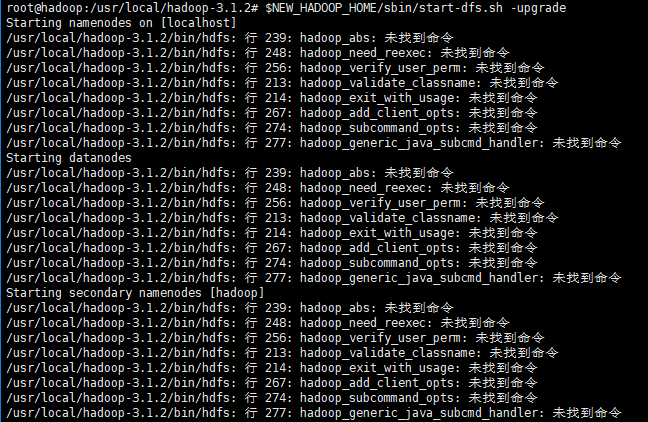
参考网址: https://stackoverflow.com/questions/21369102/hadoop-command-not-found
解决方法:查找配置环境变量的文件,/etc/profile、~/.bashrc、hadoop-env.sh,发现在~/.bashrc文件中配置了HADOOP_HOME,用了旧版本的路径,删除或者更新为新的环境变量即可。
参考资料: 《Hadoop权威指南(第四版)》