一.材料准备
https://www.kaggle.com/c/titanic-gettingStarted/
二.提出问题
生存率和哪些因素有关(性别,年龄,是否有伴侣,票价,舱位等级,包间,出发地点)
1.乘客的年龄和票价的分布
2.样本生存的几率是多少
3.乘客的性别比例
4.乘客的舱位分布
5.性别和生还有没有关系
6.舱位等级和生还有没有关系
7.年龄和生还有没有关系
8.出发地点和生存率有没有关系
9.票价和生还有没有关系
10.有陪伴的乘客的生还几率是否更高
三.编写代码和做出图形来验证所提出的的问题
1.加载数据


1 %pylab inline 2 %matplotlib inline 3 import seaborn as sns 4 import numpy as np 5 import pandas as pd 6 import matplotlib.pyplot as plt 7 titanic_data = pd.read_csv('titanic-data.csv') 8 titanic_data.info()
结论:Age,Embarked这两列需要进行数据清洗,因为Cabin列缺失的数据太多所以不能作为分析的依据
2.自定义函数分析数据
1 #统计变量和生存率的关系,如果需要使用堆栈图更清晰的展示数据,stacked的值设置为True,为False默认展示该变量下的生存率 2 def visualize_survival(feature,stacked=False): 3 if stacked: 4 survived_rate = titanic_data.groupby([feature,'Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True') 5 else: 6 survived_rate = (titanic_data.groupby([feature]).sum()/titanic_data.groupby([feature]).count())['Survived'] 7 survived_rate.plot(kind='bar') 8 plt.title(feature + ' V.S. Survival')
1 #比较单个变量之间的关系,feature表示要分析的列,args表示x轴的名称 2 def visualize_column(feature,*args): 3 fig,ax=plt.subplots(figsize=(7,5)) 4 titanic_data[feature].value_counts().plot(kind='bar') 5 for i in range(len(args)): 6 ax.set_xticklabels((args[i]),rotation='horizontal') 7 ax.set_title('bar of ' + feature)
3.分析乘客年龄和票价分布
1 fig,axes=plt.subplots(2,1,figsize=(15,5)) 2 titanic_data['Age'].hist(ax=axes[0]) #年龄分布 3 axes[0].set_title('plot of age') 4 titanic_data['Fare'].hist(ax=axes[1]) #票价分布 5 axes[1].set_title('plot of fare')
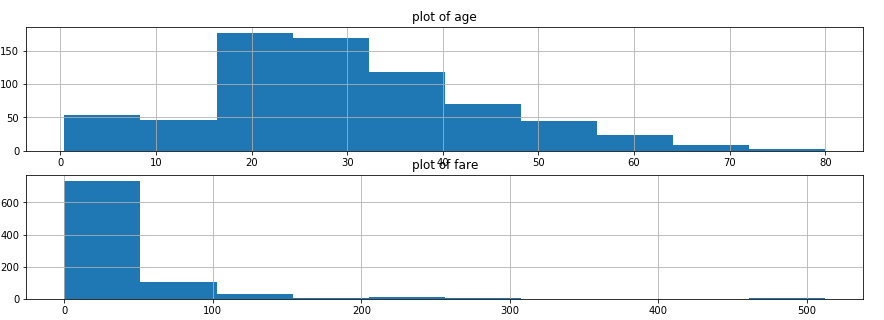
结论:
1.大部分乘客的年龄在20到40岁之间
2.票价在主要分布在(0,100)美元之间
4.样本的生存几率
1 survived_rate = float(titanic_data['Survived'].sum())/titanic_data['Survived'].count() 2 print survived_rate 3 by_survived = titanic_data.groupby(['Survived'])['Survived'].count() 4 plt.pie(by_survived,labels=['Non-Survived','Survived'],autopct='%1.0f%%') 5 plt.title('Pie Chart Of Surviveness for Surviveness of Passengers')

结论:整体的存活率约等于0.384,不超过40%的存活率
5.乘客的性别比例
1 visualize_column('Sex',('Male','Female'))

结论:大部分的乘客是男性,男性比女性多50%
6.乘客的舱位分布
1 visualize_column('Pclass',('Class 3','Class 2','Class 1'))
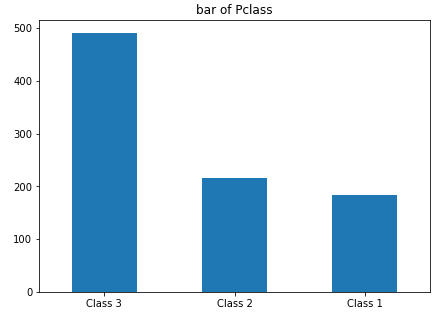
结论:三等舱的工人和奴隶占绝大多数,大约是一二等舱的总和
7.性别和生还的关系
1 visualize_survival('Sex',True)

结论:女性的生还人数远远超过男性
8.舱位等级和生还的关系
1 visualize_survival('Pclass',True)

结论:1等舱生还的几率超过50%,2等舱的生还几率接近50%,而三等舱获救的可能性最低,证实了事故发生时三等舱被第一时间锁死
9.年龄和生还的关系
首先年龄这一列存在多个空值,要进行数据的清洗,利用非空的年龄字段计算出平均年龄来填充到空值字段,其次分段是在(0,80]之间,所以以10年作为分段点可以更直观的看出年龄和生存率的关联
1 titanic_data.Age.fillna(titanic_data.Age.mean(),inplace=True) #使用均值来填充Age中的空值 2 ages = np.arange(0,90,10) #年龄分段 3 titanic_data['age_cut'] = pd.cut(titanic_data.Age,ages) 4 visualize_survival('age_cut',True)

结论:婴儿的生存比例较高,其次(20,40)岁之间的成年人生存所占比例较高,50岁以上老人和10岁左右的儿童少年生存率偏低
10.出发地点和生存率的关系
发现有个上船地点是空值,要进行数据的清洗,因为空值的票价接近于瑟堡的中位数,所以以C填充空值
1 titanic_data.Embarked[titanic_data.Embarked.isnull()] 2 print titanic_data[titanic_data['Embarked'].isin(['S','C','Q'])==False] 3 titanic1 = titanic_data[titanic_data['Pclass']==1] 4 ax=sns.boxplot(titanic1.Embarked,titanic1.Fare) 5 plt.plot((-100,100),(80,80),'r-')
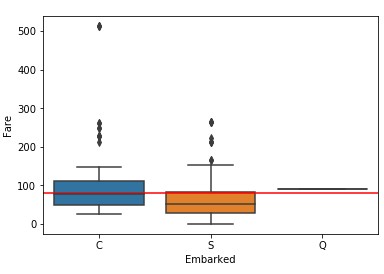
做出结论图形
1 titanic_data.Embarked=titanic_data.Embarked.fillna('C') 2 visualize_survival('Embarked')
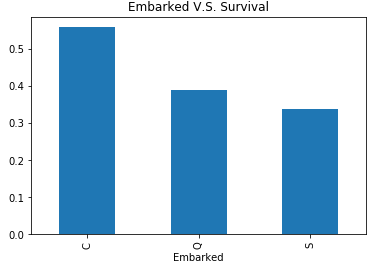
结论:从瑟堡,皇后镇,南安普顿的上船的生存率依次下降
11.票价和生存率的关系
根据问题1的分析可得出票价的分段在(0,500]美金之间,但是根据数据分组来看票价有异常值,如果票价大于100美金则为异常值,需要舍弃否则会影响统计结果的表达,
1 fares = np.arange(0,600,50) #划分票价区间 2 fares_cut = pd.cut(titanic_data.Fare,fares) 3 fares_cut_group = titanic_data.groupby(fares_cut) 4 fares_cut_group.count().PassengerId #获取异常数据 5 titanic_data.Fare.sort_values(ascending=False).head() #查看异常数据 6 #进行IQR运算找出异常数据 7 q75,q25 = np.percentile(titanic_data.Fare,[75,25]) 8 iqr = q75-q25 9 print q75+iqr*3 #确定异常数据的值
结论:超过100.27美金的票价都是异常值,在接下来的分析中要舍弃
重新进行票价的统计分区,做出图形
1 fares_count = titanic_data.Fare[titanic_data.Fare<100.27] #舍弃异常数据 2 fares_count_range = np.arange(0,110,10) #重新计算票价区间 3 titanic_data['new_fare'] = pd.cut(titanic_data.Fare,fares_count_range) 4 visualize_survival('new_fare')
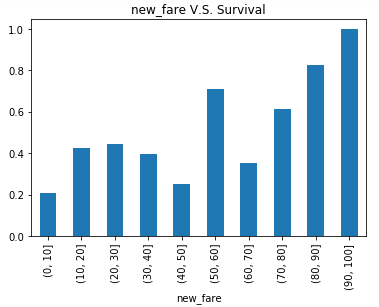
结论:总体来说票价越高生还的几率越大
12.有陪伴的乘客的生还几率是否更高
1 #通过SibSp+Parch总体计算出陪伴的生还率 2 titanic_data['family_member'] = titanic_data.SibSp+titanic_data.Parch 3 visualize_survival('family_member')
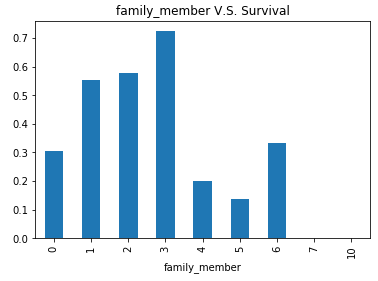
结论:当有1,2个家庭成员结伴出行的时候,生存率较高,但不是主要提高生存的途径
四.总结:
由上述一系列图表可知
1.样本整体的存活率大约为39%
2.性别是影响生存率的最主要的因素
3.票价和舱位是影响生存率的第二要因
4.年龄和生存率没有太大的关系
5.上船地点和是否家人结伴略微地影响了生存率
五.分析限制讨论:
1.此样本并非是泰坦尼克号全部乘客的数据,据了解,泰坦尼克号一共有2224名乘客,本数据一共是891名乘客,如果是891名乘客根据是从2224名乘客中随机选出,根据中心极限定理,该样本足够大,分析结论具有代表性,如果不是随机抽取,那么分析的结果就不可靠
2.可能还有其他影响生存的情况,比如国籍是否影响生存率,是否会游泳会不会影响生存率,不同的职业会不会影响生存率