mysql基础
三大范式
第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项。
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
常用数据类型
数值类型
| 类型 | 有符号 | 无符号 |
|---|---|---|
| tinyint | -128~127 | 0~255 |
| int | -2^31 ~ 2^31-1 | 0~2^32-1 |
浮点型
| 类型 | 大小 |
|---|---|
| float | 4字节 |
| double | 8字节 |
时间日期
| 类型 | 格式 |
|---|---|
| Datetime | YYYY-mm-dd HH:MMss |
| Date | YYYY-mm-dd |
| Time | HH:MM:ss |
| Timestamp | 时间戳,从1970/1/1开始,格式与Datetime一致 |
字符串型
| 格式 | 长度 |
|---|---|
| char | 最大长度255 |
| varchar | 可变字符串,最大长度65536 |
| Text | 通常超过255就会使用 |
数据库语法
查询已有数据库列表:
show databases;
创建数据库:
create database 数据库库名 [选项];
查看建库语句:
show create database 数据库名;
修改数据库(数据库名不可更改):
alter database 数据库名 [选项];
删除数据库:
drop database [if exists] 数据库名;
进入/使用数据库:
use 数据库名;
数据库约束
| 约束类型 | 语法 | 举例 |
|---|---|---|
| 非空约束 | not null | |
| 唯一约束 | unique | |
| 主键约束 | primary kry | |
| 条件约束 | check | $ check(id>0) |
| 默认值 | default | $ default ‘ ‘ |
| 自增约束 | auto_increment |
表级约束:
字符集:charser/ character set 具体字符集
校对集:collate 具体校对集
存储引擎:engine 具体存储引擎(InnoDB MyISAM)
表语法
例子:
create table t_user(
id int primary key auto_increment,
name char(32) default '',
age int
)engine=InnoDB charset=utf8
查看所有表:
show tables;
查询带关键字的表:
show tables like '%关键字%';
查看建表语句:
show create table 表名;
查看表结构:
#三种方式:
desc 表名;
describe 表名;
show columns from 表名;
删除表(可多表删除):
drop table [if exists] 表名1,表名2...;
修改表名:
rename table 旧表名 to 新表名;
修改表选项(字符集,校对集,存储引擎):
alter table 表名 表选项=值;
新增表字段:
alter table 表名 add 字段名 数据类型 [列属性] [位置];
修改表字段:
alter table 表名 change 旧字段 新字段名 数据类型 [列属性] [位置];
删除字段:
alter table 表名 drop 字段名;
表数据操作(增删改查)
插入数据:
insert into 表名(字段列表) values(对应字段值列表1),(对应字段值列表2)...
删除数据:
delete from 表名 [where 条件];
更新数据:
update 表名 set 字段=值 [where 条件];
查询数据:
select */字段列表 from 表名 [where 条件];
查询操作
where条件查询
where的字符串查询不区分大小写,若要区分则用binary
select * from t_user where binary name = 'zhangsan';
like模糊查询
select * from t_user where name like 'zhang%';
占位符:
% : 匹配0个或多个字符
_ : 匹配1个字符
order by 排序
默认为升序 ASC,倒序使用 DESC
select * from t_user order by name desc;
select * from t_user order by age desc name ASC;
使用多个字段排序时,按先后顺序
按第一字段规则排序时,有重复的数据,再根据第二字段规则排序,以此类推。
且多个字段时,要显式引用ASC/DESC,否则为默认ASC
in 包含
select * from t_user where id in(1,3,5);
between and
#查询id在1到5之间的记录(包含1,包含5)
select * from t_user where id between 1 and 5;
limit 分页
#查询6~15行数据
select * from t_user limit 5 10;
distinct 去除重复
select distinct * from t_user;
聚合函数
| 函数名 | 作用 |
|---|---|
| AVG | 返回平均值 |
| count | 返回总记录条数 |
| sum | 返回数值总和 |
| min | 返回最小值 |
| max | 返回最大值 |
聚合函数无法与where 一起使用
group by 分组函数
分组函数是根据一个或多个字段的唯一组合结果集进行分组
通常结合聚合函数一起使用
#统计男女人数
select sex as '性别',count(sex)as '人数'
from t_user
group by sex;
结果:
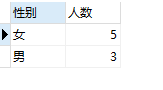
根据性别的唯一组合进行分组,分成 男 女 两组,再结合count()函数进行统计
对字段分组:
#统计不同年龄的男女人数
select sex as '性别',age as '年龄',count(sex)as '人数'
from t_user
group by sex,age;
结果:
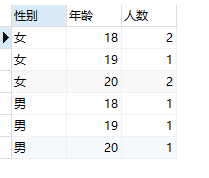
根据sex, age两个字段进行分组,根据不同值进行唯一组合,再结合聚合函数进行统计
having 条件
因为聚合不能与where一起使用,所以有了having
having是用于分组后返回满足条件的数据
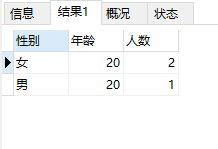
#统计不同年龄的男女人数,并要求年龄不小于19
select sex as '性别',age as '年龄',count(sex)as '人数'
from t_user
group by sex,age having age>=19;
连接查询
内连接 inner join

左外连接 left join

右外连接 right join

以员工表和部门表为例,dept代表该员工所在的部门:
t_employee表
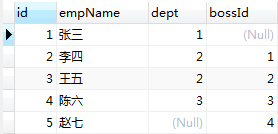
t_dept表
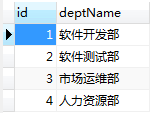
内连接查询:
#查询出员工姓名以及其对应的部门名称
select
e.empName,d.deptName
from t_employee e
INNER JOIN t_dept d
ON e.dept = d.id;
结果:
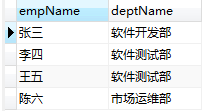
在内连接中赵七没有被查出来,因为他没有对应的部门,现在想要把赵七也查出来,就要使用左外连接查询:
#查询所有员工姓名以及他所在的部门名称
select e.empName,d.deptName
from t_employee e
left join t_dept d
on d.id = e.dept;
结果:

右外连接查询与做查询同理,只是基准表的位置发生了变化:
SELECT e.empName,d.deptName
from t_employee e
right join t_dept d
on d.id = e.dept;
结果:
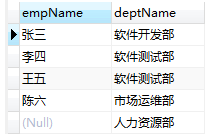
总结:
左连接查询时,左表数据全部显示,若右表没有对应数据,则显示为null;
右连接查询时,右表数据全部显示,若左表没有对应数据,则显示为null;
自连接查询
自连接查询就是当前表与自身的连接查询,关键点在于虚拟化出一张表给一个别名
#查询员工以及他的上司的名称,由于上司也是员工,所以这里虚拟化出一张上司表
SELECT e.empName,b.empName
from t_employee e
LEFT JOIN t_employee b
ON e.bossId = b.id;
结果:
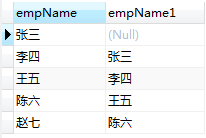
全外连接 union
mysql是没有全外连接的(mysql中没有full outer join关键字),想要达到全外连接的效果,可以使用union关键字连接左外连接和右外连接
欢迎访问个人博客:http://www.itle.info/