前言
这不是我第一次写关于C指针的文章了,只是因为指针对于C来说太重要,而且随着自己编程经历越多,对指针的理解越多,因此有了本文。然而,想要全面理解指针,除了要对C语言有熟练的掌握外,还要有计算机硬件以及操作系统等方方面面的基本知识。所以我想通过一篇文章来尽可能的讲解指针,以对得起这个文章的标题吧。
本文会持续更新。
为什么需要指针?
指针解决了一些编程中基本的问题。
指针是什么?

为什么程序中的数据会有自己的地址?

而作为一个程序员,我们不需要了解内存的物理结构,操作系统将DRAM等硬件和软件结合起来,给程序员提供的一种对物理内存使用的抽象。这种抽象机制使得程序使用的是虚拟存储器,而不是直接操作物理存储器。所有的虚拟地址形成的集合就是虚拟地址空间。
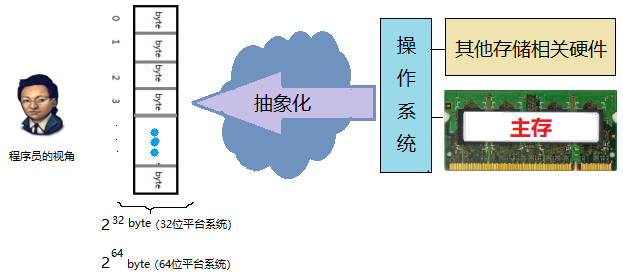
在程序员眼中的内存应该是下面这样的。(假设使用的是32位系统平台,虚拟存储空间为4GB)

也就是说,虚拟存储器是一个很大的,线性的字节数组(平坦寻址)。每一个字节都是固定的大小,由8个二进制位组成。最关键的是,每一个字节都有一个唯一的编号,编号从0开始,一直到最后一个字节。如上图中,这是一个4GB的虚拟存储器的模型,它一共有4x1024x1024x1024 个字节,那么它的虚拟地址范围就是 0 ~ 4x1024x1024x1024-1 。
由于内存中的每一个字节都有一个唯一的编号,因此,在程序中使用的变量,常量,甚至数函数等数据,当他们被载入到内存中后,都有自己唯一的一个编号,这个编号就是这个数据的地址。指针就是这样形成的。
下面用代码说明
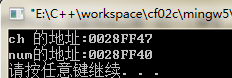
#include <stdio.h> int main(void) { char ch = 'a'; int num = 97; printf("ch 的地址:%p ",&ch); //ch 的地址:0028FF47 printf("num的地址:%p ",&num); //num的地址:0028FF40 return 0; }

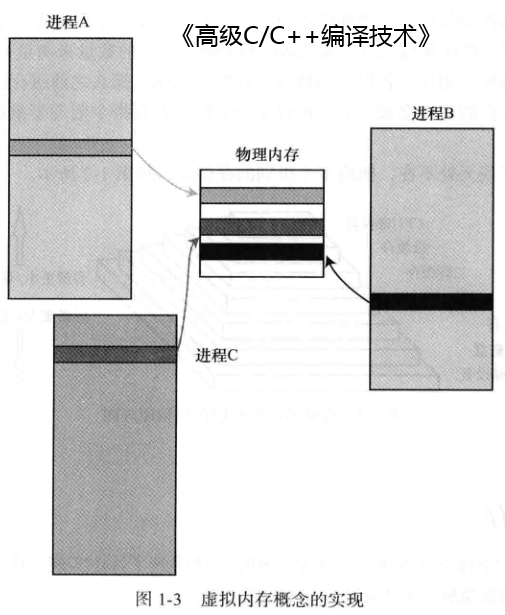
操作系统为什么提供虚拟地址空间给程序员用而不是让程序员直接使用物理地址空间?
本节内容属于编程思想上的内容,可以先不看,或仅作了解。
1、提高物理内存的利用效率。
你可能会困惑,这怎么就提高物理内存使用效率了呢?我这里举个共享单车的例子:假如一个国家有10个人,而只生产了2辆自行车(国家小,资源有限嘛~),这2辆车被2个人买了。把你自己想象为那8个没有自行车的人之一,你的思维是什么——"我没有自行车,我只能步行外出"。倘若是那2个有车的人呢——"我每次外出都可以骑车去,但是大部分时间,我的车是空闲的,没其他人用"。后来,这个国家回收了这仅有的2辆车,把车刷成了统一的颜色,贴上二维码,引入了共享单车系统,然后发出公告:只要车停在路边没人用,任何人都可以刷开骑走。那现在这10个人怎么想呢——“只要我看到有空闲的单车,我就可以使用它”。
2、抽象的东西更加简单稳定。
从古至今,我们对于“去饭馆吃饭”这个抽象社会行为没有太大的变化——进入饭馆,点菜,付钱,享用,走人。但是人们烹饪的方法却发生了具大的改变,烹饪的器材、食材、食谱一直都在更新改进,如果你经常烹饪,你就需要不断的学习,因为你需要掌握做一道菜的每个细节。
回到内存相关的话题来:无论机器的内存用的是ddr3还是ddr4,是4G物理内存还是8G物理内存,程序员都似乎无需太过关心,因为他们在编程时面向的是虚拟内存,而虚拟内存的模型到目前为止都是固定的。这给程序员带来非常大的便利,他们无需为快速更新的计算机设备而改变自己的编程思维。
这并不意味着抽象的东西就一定不会改变。例如从“到饭馆吃饭”到“点外卖”;从32位操作系统到64位操作系统。都属于抽象的更新换代。
3、使用虚拟地址空间更加安全。操作系统对应用程序提供操作内存的API,而不让应用程序直接操作物理内存。避免应用程序因操作不当而导致整个系统挂掉的危险情况发生。
总结(我个人认为):
- 资产有限的情况下,使用合理的资产使用管理机制,可以使有限的资产服务于更多的人。
- 抽象的事物更加简单稳定,特定的事物更加复杂易变。
- 底层通过给上层提供抽象服务来获得利益,上层通过使用底层的抽象来获得便利。
变量和内存
为了简单起见,这里就用上面例子中的 int num = 97 这个局部变量来分析变量在内存中的存储模型。

指针变量 和 指向关系
用来保存 指针(地址) 的变量,就是指针变量。如果指针变量p1保存了变量 num的地址,则就说:p1指向了变量num,也可以说p1指向了num所在的内存块 ,这种指向关系,在图中一般用 箭头表示。

上图中,指针变量p1指向了num所在的内存块 ,即从地址0028FF40开始的4个byte 的内存块。
这里学2个名词,读英文资料的时候可能会用到
- pointer:指针,例如上面例子中的p1
- pointee:被指向的数据对象,例如上面例子中的num
- 所以我们可以说:a pointer stores the address of a pointee
int a ; //int类型变量 a int* p ; //int* 变量p int arr[3]; //arr是包含3个int元素的数组 int (* parr )[3]; //parr是一个指向【包含3个int元素的数组】的指针变量 //-----------------各种类型的指针------------------------------ int* p_int; //指向int类型变量的指针 double* p_double; //指向double类型变量的指针 struct Student *p_struct; //结构体类型的指针 int(*p_func)(int,int); //指向返回类型为int,有2个int形参的函数的指针 int(*p_arr)[3]; //指向含有3个int元素的数组的指针 int** p_pointer; //指向 一个整形变量指针的指针
int add(int a , int b) { return a + b; } int main(void) { int num = 97; float score = 10.00F; int arr[3] = {1,2,3}; //----------------------- int* p_num = # float* p_score = &score; int (*p_arr)[3] = &arr; int (*fp_add)(int ,int ) = &add; //p_add是指向函数add的函数指针 return 0; }
- 数组名的值就是这个数组的第一个元素的地址。
- 函数名的值就是这个函数的地址。
- 字符串字面值常量作为右值时,就是这个字符串对应的字符数组的名称,也就是这个字符串在内存中的地址。
int add(int a , int b){ return a + b; } int main(void) { int arr[3] = {1,2,3}; //----------------------- int* p_first = arr; int (*fp_add)(int ,int ) = add; const char* msg = "Hello world"; return 0; }
int main(void) { int age = 19; int*p_age = &age; *p_age = 20; //通过指针修改指向的内存数据 printf("age = %d ",*p_age); //通过指针读取指向的内存数据 printf("age = %d ",age); return 0; }
int* p1 = & num; int* p3 = p1; //通过指针 p1 、 p3 都可以对内存数据 num 进行读写,如果2个函数分别使用了p1 和p3,那么这2个函数就共享了数据num。

#ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif
void opp() { int*p = NULL; *p = 10; //Oops! 不能对NULL解地址 } void foo() { int*p; *p = 10; //Oops! 不能对一个未知的地址解地址 } void bar() { int*p = (int*)1000; *p =10; //Oops! 不能对一个可能不属于本程序的内存的地址的指针解地址 }
指针的2个重要属性
指针也是一种数据,指针变量也是一种变量,因此指针 这种数据也符合前面 变量和内存 主题中的特性。 这里我只想强调2个属性: 指针的类型,指针的值。
int main(void) { int num = 97; int *p1 = # char* p2 = (char*)(&num); printf("%d ",*p1); //输出 97 putchar(*p2); //输出 a return 0; }
结构体和指针
typedef struct { char name[31]; int age; float score; }Student; int main(void) { Student stu = {"Bob" , 19, 98.0}; Student*ps = &stu; ps->age = 20; ps->score = 99.0; printf("name:%s age:%d ",ps->name,ps->age); return 0; }
数组和指针
int main(void) { int arr[3] = {1,2,3}; int*p_first = arr; printf("%d ",*p_first); //1 return 0; }
int main(void) { int arr[3] = {1,2,3}; int*p = arr; for(;p!=arr+3;p++){ printf("%d ",*p); } return 0; }
int main(void) { int arr[3] = {1,2,3}; int*p = arr; printf("sizeof(arr)=%d ",sizeof(arr)); //sizeof(arr)=12 printf("sizeof(p)=%d ",sizeof(p)); //sizeof(p)=4 return 0; }
函数和指针
void change(int a) { a++; //在函数中改变的只是这个函数的局部变量a,而随着函数执行结束,a被销毁。age还是原来的age,纹丝不动。 } int main(void) { int age = 19; change(age); printf("age = %d ",age); // age = 19 return 0; }
void change(int* pa) { (*pa)++; //因为传递的是age的地址,因此pa指向内存数据age。当在函数中对指针pa解地址时, //会直接去内存中找到age这个数据,然后把它增1。 } int main(void) { int age = 19; change(&age); printf("age = %d ",age); // age = 20 return 0; }
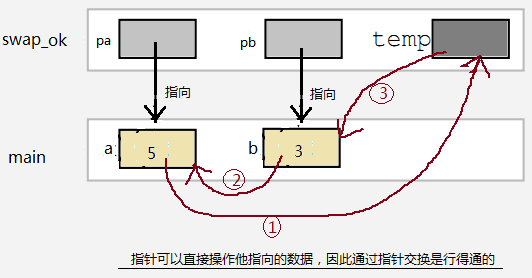
再来一个老生常谈的,用函数交换2个变量的值的例子:
#include<stdio.h> void swap_bad(int a,int b); void swap_ok(int*pa,int*pb); int main() { int a = 5; int b = 3; swap_bad(a,b); //Can`t swap; swap_ok(&a,&b); //OK return 0; } //错误的写法 void swap_bad(int a,int b) { int t; t=a; a=b; b=t; } //正确的写法:通过指针 void swap_ok(int*pa,int*pb) { int t; t=*pa; *pa=*pb; *pb=t; }

typedef struct { char name[31]; int age; float score; }Student; //打印Student变量信息 void show(const Student * ps) { printf("name:%s , age:%d , score:%.2f ",ps->name,ps->age,ps->score); }
void echo(const char *msg) { printf("%s",msg); } int main(void) { void(*p)(const char*) = echo; //函数指针变量指向echo这个函数 p("Hello "); //通过函数的指针p调用函数,等价于echo("Hello ") echo("World "); return 0; }
const 和 指针
如果const 后面是一个类型,则跳过最近的原子类型,修饰后面的数据。(原子类型是不可再分割的类型,如int, short , char,以及typedef包装后的类型)
int main() { int a = 1; int const *p1 = &a; //const后面是*p1,实质是数据a,则修饰*p1,通过p1不能修改a的值 const int*p2 = &a; //const后面是int类型,则跳过int ,修饰*p2, 效果同上 int* const p3 = NULL; //const后面是数据p3。也就是指针p3本身是const . const int* const p4 = &a; // 通过p4不能改变a 的值,同时p4本身也是 const int const* const p5 = &a; //效果同上 return 0; }
typedef int* pint_t; //将 int* 类型 包装为 pint_t,则pint_t 现在是一个完整的原子类型 int main() { int a = 1; const pint_t p1 = &a; //同样,const跳过类型pint_t,修饰p1,指针p1本身是const pint_t const p2 = &a; //const 直接修饰p,同上 return 0; }
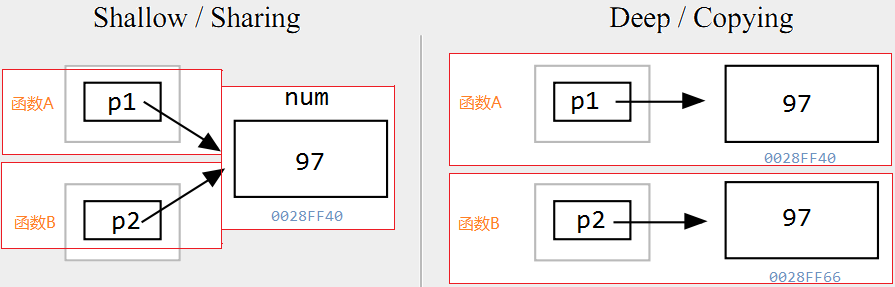
深拷贝和浅拷贝
如果2个程序单元(例如2个函数)是通过拷贝 他们所共享的数据的 指针来工作的,这就是浅拷贝,因为真正要访问的数据并没有被拷贝。如果被访问的数据被拷贝了,在每个单元中都有自己的一份,对目标数据的操作相互 不受影响,则叫做深拷贝。
附加知识
指针和引用这个2个名词的区别。他们本质上来说是同样的东西。指针常用在C语言中,而引用,则用于诸如Java,C#等 在语言层面封装了对指针的直接操作的编程语言中。引用是编程语言提供给程序员的抽象机制,而指针是操作系统提供给软件开发模型的抽象机制。

#include<stdio.h> //测试机器使用的是否为小端模式。是,则返回true,否则返回false //这个方法判别的依据就是:C语言中一个对象的地址就是这个对象占用的字节中,地址值最小的那个字节的地址。 int isSmallIndain(void) { unsigned short val = 0x0001; unsigned char* p = (unsigned char*)&val; //C/C++:对于多字节数据,取地址是取的数据对象的第一个字节的地址,也就是数据的低地址 return (*p == 0x01); } int main(void) { if(isSmallIndain()) { puts("小端"); } else{ puts("大端"); } return 0; }
第二种方法,使用union类型
#include<stdio.h> typedef union { unsigned short us; unsigned char uc; }Test_t; int main(void) { Test_t val; val.us = 0x0001; if(val.uc==0x01) { puts("小端"); } else{ puts("大端"); } return 0; }
#include<stdio.h> //打印出一个unsigned short int 类型的原始字节流 //这个例子中很明显看到,取到a的首地址后,我们循环递增了p,而非递减p,也从来不会看到有从首地址递减输出数据的字节的写法。 //这也就佐证了:在C语言中,对于一个多字节数据,它的地址就是它占用的所有字节中的地址值最小的那个字节的虚拟空间地址 //这也又说明了一个事实:C语言中,一个多字节数据类型的实例,占用的虚拟内存空间是连续的。 int main(void) { size_t i; unsigned short int a = 0xA1FF; unsigned char*p = (unsigned char*)&a; for( i=0;i<sizeof(a);++i) { printf("%#x ",*p); //小端平台输出:0xFF 0xA1 p++; //大端平台输出:0xA1 0xFF } printf(" "); return 0; }